A Simple Joint Model for Improved Contextual Neural Lemmatization

0
📈
Sign in to get full access
Overview
- The paper presents a simple joint neural model for lemmatization and morphological tagging that achieves state-of-the-art results on 20 languages.
- Lemmatization is the task of mapping diverse verb forms (e.g., "talk", "talks", "talked", "talking") back to a canonical form known as the lemma.
- The authors describe the model architecture and training/decoding procedures.
- Error analysis indicates that joint morphological tagging and lemmatization is especially helpful for low-resource lemmatization and languages with high morphological complexity.
Plain English Explanation
Verbs in English can take different forms depending on the context - for example, the verb "talk" can appear as "talks", "talked", or "talking". Lemmatization is the process of mapping these diverse verb forms back to a single, canonical form known as the lemma.
In this paper, the researchers present a simple neural network model that can perform both lemmatization and morphological tagging - identifying the grammatical properties of words like part of speech, number, and tense. Their model achieves the best results to date on 20 different languages from the Universal Dependencies corpora.
The researchers found that jointly modeling lemmatization and morphological tagging is particularly useful for languages with complex grammar, as well as for situations where there is limited training data available. This suggests the approach could be valuable for building natural language processing (NLP) systems for low-resource languages.
Technical Explanation
The paper introduces a joint neural network model for lemmatization and morphological tagging. The model takes a word as input and outputs both the lemma (canonical form) and the morphological tags (e.g., part of speech, number, tense) for that word.
The architecture consists of a BiLSTM encoder that learns contextual word representations, which are then passed to separate decoding layers for lemmatization and morphological tagging. The lemmatization decoder uses an attention mechanism to predict the output lemma one character at a time, while the morphological tagging decoder predicts a sequence of tags.
The model is trained end-to-end on data annotated with lemmas and morphological information, such as the Universal Dependencies corpora. During inference, the model performs joint lemmatization and tagging in a single forward pass.
Error analysis revealed that the joint modeling approach is particularly beneficial for low-resource lemmatization and languages with a high degree of morphological complexity, as the morphological signals help guide the lemmatization predictions.
Critical Analysis
The paper presents a strong technical contribution, with a simple yet effective joint model that outperforms previous approaches on a diverse set of languages. The authors provide a thorough error analysis to understand the model's strengths and weaknesses.
One potential limitation is that the model relies on contextual word representations, which can be challenging to obtain for low-resource languages lacking large text corpora. The authors mention this as a direction for future work, potentially exploring ways to leverage large language models for better representation learning in these scenarios.
Additionally, the paper does not explore the model's performance on truly endangered or under-resourced languages, which may have even more complex morphological systems. Further research is needed to assess the model's scalability and robustness to a wider range of linguistic diversity.
Overall, this work makes an important contribution to the field of morphological modeling and low-resource NLP, providing a strong foundation for future research in this area.
Conclusion
This paper presents a simple yet effective joint neural model for lemmatization and morphological tagging that achieves state-of-the-art results across 20 languages. The key insights are that jointly modeling these two related tasks can be particularly beneficial for low-resource settings and languages with high morphological complexity.
The researchers' findings suggest that this approach could be valuable for building robust NLP systems for a wide range of languages, including endangered or under-resourced ones. As the field of natural language processing continues to evolve, techniques like this that can adapt to diverse linguistic landscapes will be increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
A Simple Joint Model for Improved Contextual Neural Lemmatization
Chaitanya Malaviya, Shijie Wu, Ryan Cotterell
English verbs have multiple forms. For instance, talk may also appear as talks, talked or talking, depending on the context. The NLP task of lemmatization seeks to map these diverse forms back to a canonical one, known as the lemma. We present a simple joint neural model for lemmatization and morphological tagging that achieves state-of-the-art results on 20 languages from the Universal Dependencies corpora. Our paper describes the model in addition to training and decoding procedures. Error analysis indicates that joint morphological tagging and lemmatization is especially helpful in low-resource lemmatization and languages that display a larger degree of morphological complexity. Code and pre-trained models are available at https://sigmorphon.github.io/sharedtasks/2019/task2/.
Read more5/29/2024
🐍
0
Joint Lemmatization and Morphological Tagging with LEMMING
Thomas Muller, Ryan Cotterell, Alexander Fraser, Hinrich Schutze
We present LEMMING, a modular log-linear model that jointly models lemmatization and tagging and supports the integration of arbitrary global features. It is trainable on corpora annotated with gold standard tags and lemmata and does not rely on morphological dictionaries or analyzers. LEMMING sets the new state of the art in token-based statistical lemmatization on six languages; e.g., for Czech lemmatization, we reduce the error by 60%, from 4.05 to 1.58. We also give empirical evidence that jointly modeling morphological tags and lemmata is mutually beneficial.
Read more5/29/2024
🧠
0
Cross-lingual, Character-Level Neural Morphological Tagging
Ryan Cotterell, Georg Heigold
Even for common NLP tasks, sufficient supervision is not available in many languages -- morphological tagging is no exception. In the work presented here, we explore a transfer learning scheme, whereby we train character-level recurrent neural taggers to predict morphological taggings for high-resource languages and low-resource languages together. Learning joint character representations among multiple related languages successfully enables knowledge transfer from the high-resource languages to the low-resource ones, improving accuracy by up to 30% over a monolingual model.
Read more6/7/2024
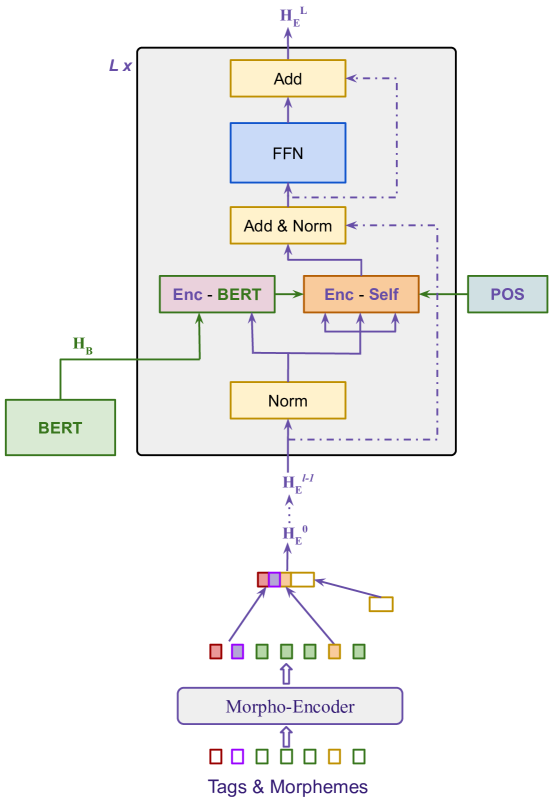
0
Low-resource neural machine translation with morphological modeling
Antoine Nzeyimana
Morphological modeling in neural machine translation (NMT) is a promising approach to achieving open-vocabulary machine translation for morphologically-rich languages. However, existing methods such as sub-word tokenization and character-based models are limited to the surface forms of the words. In this work, we propose a framework-solution for modeling complex morphology in low-resource settings. A two-tier transformer architecture is chosen to encode morphological information at the inputs. At the target-side output, a multi-task multi-label training scheme coupled with a beam search-based decoder are found to improve machine translation performance. An attention augmentation scheme to the transformer model is proposed in a generic form to allow integration of pre-trained language models and also facilitate modeling of word order relationships between the source and target languages. Several data augmentation techniques are evaluated and shown to increase translation performance in low-resource settings. We evaluate our proposed solution on Kinyarwanda - English translation using public-domain parallel text. Our final models achieve competitive performance in relation to large multi-lingual models. We hope that our results will motivate more use of explicit morphological information and the proposed model and data augmentations in low-resource NMT.
Read more4/4/2024