Cross-Subject Data Splitting for Brain-to-Text Decoding
2312.10987
0
0
Abstract
Recent major milestones have successfully decoded non-invasive brain signals (e.g. functional Magnetic Resonance Imaging (fMRI) and electroencephalogram (EEG)) into natural language. Despite the progress in model design, how to split the datasets for training, validating, and testing still remains a matter of debate. Most of the prior researches applied subject-specific data splitting, where the decoding model is trained and evaluated per subject. Such splitting method poses challenges to the utilization efficiency of dataset as well as the generalization of models. In this study, we propose a cross-subject data splitting criterion for brain-to-text decoding on various types of cognitive dataset (fMRI, EEG), aiming to maximize dataset utilization and improve model generalization. We undertake a comprehensive analysis on existing cross-subject data splitting strategies and prove that all these methods suffer from data leakage, namely the leakage of test data to training set, which significantly leads to overfitting and overestimation of decoding models. The proposed cross-subject splitting method successfully addresses the data leakage problem and we re-evaluate some SOTA brain-to-text decoding models as baselines for further research.
Create account to get full access
Overview
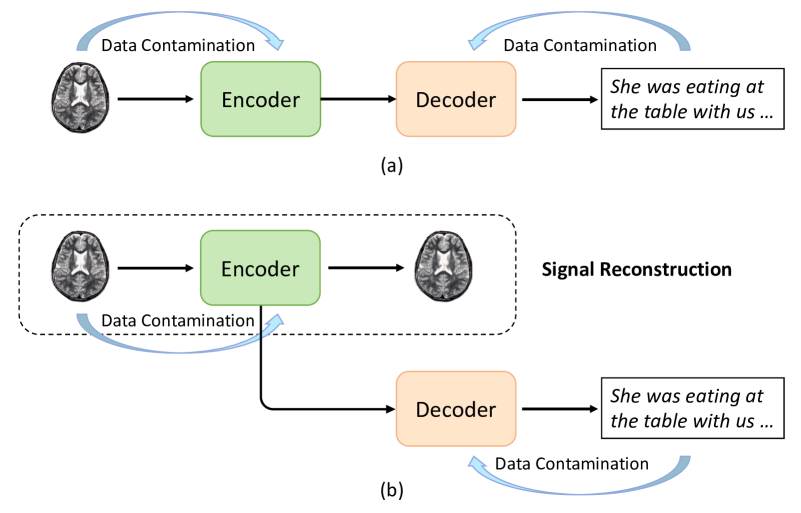
- This paper discusses the issue of data contamination in brain-to-text decoding, which is the process of translating brain activity signals into written text.
- Brain-to-text decoding has applications in assistive technology for people with speech and motor disabilities, but it faces challenges due to the complex and noisy nature of brain signals.
- The paper examines how data contamination, where external factors unrelated to the task influence the model's predictions, can lead to inaccurate and biased results in brain-to-text decoding systems.
Plain English Explanation
The paper focuses on a problem called "data contamination" that can occur when developing systems to translate brain signals into text. Brain-to-text decoding is a promising technology that could help people with speech and motor disabilities communicate by allowing them to control a computer or device using their thoughts. However, this is a challenging task because brain signals are complex and often noisy, making it hard for the decoding system to accurately interpret them.
The issue of data contamination arises when factors unrelated to the task of translating brain signals into text somehow influence the model's predictions. For example, if the training data includes information about the participant's identity or the experimental setup, the model may learn to associate certain brain patterns with those irrelevant factors instead of the actual intended text. This can lead to the model making inaccurate or biased predictions, undermining the reliability and usefulness of the brain-to-text decoding system.
By understanding and addressing data contamination, researchers can improve the performance and robustness of brain-to-text decoding systems, bringing us closer to realizing the potential of this technology to enhance communication and independence for people with disabilities.
Technical Explanation
The paper investigates the problem of data contamination in the context of brain-to-text decoding, which is the task of translating brain activity signals into written text. Brain-to-text decoding has applications in assistive technology for individuals with speech and motor disabilities, but it faces challenges due to the complex and noisy nature of brain signals.
Data contamination occurs when external factors unrelated to the primary task, such as the participant's identity or experimental setup, inadvertently influence the model's predictions. This can lead to inaccurate and biased results, as the model may learn to associate certain brain patterns with these irrelevant factors instead of the intended text.
The paper examines various sources of data contamination in brain-to-text decoding, including participant identity, experimental conditions, and stimulus presentation order. The authors demonstrate how these factors can introduce systematic biases in the model's performance, compromising the reliability and generalizability of the system.
To address this issue, the paper proposes several strategies for mitigating data contamination, such as careful experimental design, data preprocessing, and the use of cross-subject decoding techniques. These approaches aim to isolate the relevant brain activity patterns from confounding factors, enabling more accurate and robust brain-to-text decoding.
Critical Analysis
The paper provides a thorough examination of the data contamination problem in brain-to-text decoding, highlighting the potential issues that can arise when external factors influence the model's predictions. The authors' identification of various sources of contamination, such as participant identity and experimental conditions, is a valuable contribution to the field.
However, the paper does not delve deeply into the specific mechanisms by which these contaminating factors can impact the model's performance. A more detailed analysis of the underlying neural and cognitive processes involved would help readers better understand the root causes of the problem.
Additionally, while the proposed mitigation strategies, such as cross-subject decoding, are promising, the paper could have provided more empirical evidence or case studies to demonstrate their effectiveness in real-world applications. This would strengthen the practical relevance and applicability of the findings.
Furthermore, the paper could have explored the potential trade-offs or limitations of these mitigation approaches, as well as suggested avenues for future research to address the remaining challenges in this domain. Advancements in EEG-based brain signal decoding may also provide valuable insights that could inform the authors' proposed solutions.
Conclusion
This paper sheds light on the critical issue of data contamination in brain-to-text decoding, a technology with the potential to significantly improve the lives of individuals with speech and motor disabilities. By highlighting the various sources of contamination and proposing mitigation strategies, the authors have made an important contribution to the field.
However, further research is needed to deepen our understanding of the underlying mechanisms and to develop more robust and reliable brain-to-text decoding systems. As the field of brain-computer interfaces continues to advance, addressing data contamination will be crucial for realizing the full potential of this transformative technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MindBridge: A Cross-Subject Brain Decoding Framework
Shizun Wang, Songhua Liu, Zhenxiong Tan, Xinchao Wang
0
0
Brain decoding, a pivotal field in neuroscience, aims to reconstruct stimuli from acquired brain signals, primarily utilizing functional magnetic resonance imaging (fMRI). Currently, brain decoding is confined to a per-subject-per-model paradigm, limiting its applicability to the same individual for whom the decoding model is trained. This constraint stems from three key challenges: 1) the inherent variability in input dimensions across subjects due to differences in brain size; 2) the unique intrinsic neural patterns, influencing how different individuals perceive and process sensory information; 3) limited data availability for new subjects in real-world scenarios hampers the performance of decoding models. In this paper, we present a novel approach, MindBridge, that achieves cross-subject brain decoding by employing only one model. Our proposed framework establishes a generic paradigm capable of addressing these challenges by introducing biological-inspired aggregation function and novel cyclic fMRI reconstruction mechanism for subject-invariant representation learning. Notably, by cycle reconstruction of fMRI, MindBridge can enable novel fMRI synthesis, which also can serve as pseudo data augmentation. Within the framework, we also devise a novel reset-tuning method for adapting a pretrained model to a new subject. Experimental results demonstrate MindBridge's ability to reconstruct images for multiple subjects, which is competitive with dedicated subject-specific models. Furthermore, with limited data for a new subject, we achieve a high level of decoding accuracy, surpassing that of subject-specific models. This advancement in cross-subject brain decoding suggests promising directions for wider applications in neuroscience and indicates potential for more efficient utilization of limited fMRI data in real-world scenarios. Project page: https://littlepure2333.github.io/MindBridge
4/12/2024
🔄
EEG2TEXT: Open Vocabulary EEG-to-Text Decoding with EEG Pre-Training and Multi-View Transformer
Hanwen Liu, Daniel Hajialigol, Benny Antony, Aiguo Han, Xuan Wang
0
0
Deciphering the intricacies of the human brain has captivated curiosity for centuries. Recent strides in Brain-Computer Interface (BCI) technology, particularly using motor imagery, have restored motor functions such as reaching, grasping, and walking in paralyzed individuals. However, unraveling natural language from brain signals remains a formidable challenge. Electroencephalography (EEG) is a non-invasive technique used to record electrical activity in the brain by placing electrodes on the scalp. Previous studies of EEG-to-text decoding have achieved high accuracy on small closed vocabularies, but still fall short of high accuracy when dealing with large open vocabularies. We propose a novel method, EEG2TEXT, to improve the accuracy of open vocabulary EEG-to-text decoding. Specifically, EEG2TEXT leverages EEG pre-training to enhance the learning of semantics from EEG signals and proposes a multi-view transformer to model the EEG signal processing by different spatial regions of the brain. Experiments show that EEG2TEXT has superior performance, outperforming the state-of-the-art baseline methods by a large margin of up to 5% in absolute BLEU and ROUGE scores. EEG2TEXT shows great potential for a high-performance open-vocabulary brain-to-text system to facilitate communication.
5/6/2024
See Through Their Minds: Learning Transferable Neural Representation from Cross-Subject fMRI
Yulong Liu, Yongqiang Ma, Guibo Zhu, Haodong Jing, Nanning Zheng
0
0
Deciphering visual content from functional Magnetic Resonance Imaging (fMRI) helps illuminate the human vision system. However, the scarcity of fMRI data and noise hamper brain decoding model performance. Previous approaches primarily employ subject-specific models, sensitive to training sample size. In this paper, we explore a straightforward but overlooked solution to address data scarcity. We propose shallow subject-specific adapters to map cross-subject fMRI data into unified representations. Subsequently, a shared deeper decoding model decodes cross-subject features into the target feature space. During training, we leverage both visual and textual supervision for multi-modal brain decoding. Our model integrates a high-level perception decoding pipeline and a pixel-wise reconstruction pipeline guided by high-level perceptions, simulating bottom-up and top-down processes in neuroscience. Empirical experiments demonstrate robust neural representation learning across subjects for both pipelines. Moreover, merging high-level and low-level information improves both low-level and high-level reconstruction metrics. Additionally, we successfully transfer learned general knowledge to new subjects by training new adapters with limited training data. Compared to previous state-of-the-art methods, notably pre-training-based methods (Mind-Vis and fMRI-PTE), our approach achieves comparable or superior results across diverse tasks, showing promise as an alternative method for cross-subject fMRI data pre-training. Our code and pre-trained weights will be publicly released at https://github.com/YulongBonjour/See_Through_Their_Minds.
6/14/2024

MindTuner: Cross-Subject Visual Decoding with Visual Fingerprint and Semantic Correction
Zixuan Gong, Qi Zhang, Guangyin Bao, Lei Zhu, Ke Liu, Liang Hu, Duoqian Miao
0
0
Decoding natural visual scenes from brain activity has flourished, with extensive research in single-subject tasks and, however, less in cross-subject tasks. Reconstructing high-quality images in cross-subject tasks is a challenging problem due to profound individual differences between subjects and the scarcity of data annotation. In this work, we proposed MindTuner for cross-subject visual decoding, which achieves high-quality and rich-semantic reconstructions using only 1 hour of fMRI training data benefiting from the phenomena of visual fingerprint in the human visual system and a novel fMRI-to-text alignment paradigm. Firstly, we pre-train a multi-subject model among 7 subjects and fine-tune it with scarce data on new subjects, where LoRAs with Skip-LoRAs are utilized to learn the visual fingerprint. Then, we take the image modality as the intermediate pivot modality to achieve fMRI-to-text alignment, which achieves impressive fMRI-to-text retrieval performance and corrects fMRI-to-image reconstruction with fine-tuned semantics. The results of both qualitative and quantitative analyses demonstrate that MindTuner surpasses state-of-the-art cross-subject visual decoding models on the Natural Scenes Dataset (NSD), whether using training data of 1 hour or 40 hours.
4/22/2024