MindTuner: Cross-Subject Visual Decoding with Visual Fingerprint and Semantic Correction
2404.12630
0
0

Abstract
Decoding natural visual scenes from brain activity has flourished, with extensive research in single-subject tasks and, however, less in cross-subject tasks. Reconstructing high-quality images in cross-subject tasks is a challenging problem due to profound individual differences between subjects and the scarcity of data annotation. In this work, we proposed MindTuner for cross-subject visual decoding, which achieves high-quality and rich-semantic reconstructions using only 1 hour of fMRI training data benefiting from the phenomena of visual fingerprint in the human visual system and a novel fMRI-to-text alignment paradigm. Firstly, we pre-train a multi-subject model among 7 subjects and fine-tune it with scarce data on new subjects, where LoRAs with Skip-LoRAs are utilized to learn the visual fingerprint. Then, we take the image modality as the intermediate pivot modality to achieve fMRI-to-text alignment, which achieves impressive fMRI-to-text retrieval performance and corrects fMRI-to-image reconstruction with fine-tuned semantics. The results of both qualitative and quantitative analyses demonstrate that MindTuner surpasses state-of-the-art cross-subject visual decoding models on the Natural Scenes Dataset (NSD), whether using training data of 1 hour or 40 hours.
Create account to get full access
Overview
- This paper proposes a novel framework called "MindTuner" for cross-subject visual decoding from functional Magnetic Resonance Imaging (fMRI) data.
- The key innovations are a "visual fingerprint" to capture subject-specific visual encoding patterns and a "semantic correction" module to align the decoding across subjects.
- The framework is evaluated on several public fMRI datasets and demonstrates state-of-the-art cross-subject visual decoding performance.
Plain English Explanation
The paper describes a new system called "MindTuner" that can decode what a person is seeing from their brain activity, even if the system hasn't been trained on that person before. This is an important challenge, because people's brains can be quite different, and a system trained on one person may not work well for another.
The key ideas in MindTuner are:
-
Visual Fingerprint: The system learns a unique "fingerprint" for each person that captures how their brain encodes visual information. This allows the system to adapt to the individual.
-
Semantic Correction: The system also learns to align the decoded information across different people's brains. So even though their brains may be wired differently, the system can translate the brain activity into a common representation.
By combining these two innovations, MindTuner is able to decode what a person is seeing much more accurately than previous approaches, even if the system hasn't been trained on that person before. This could be very useful for applications like brain-computer interfaces, where we want to decode a person's thoughts or perceptions without having to train the system extensively on them.
Technical Explanation
The MindTuner framework addresses the challenge of cross-subject visual decoding from fMRI data. Previous approaches have struggled with this because people's brains can encode visual information in very different ways.
To tackle this, MindTuner introduces two key components:
-
Visual Fingerprint: The system learns a unique "fingerprint" for each subject that captures their individual visual encoding patterns. This allows the model to adapt to the subject-specific brain representations.
-
Semantic Correction: The system also learns to align the decoded information across different subjects. This semantic mapping allows the model to translate the brain activity into a common representational space, despite the individual differences.
The full MindTuner framework combines these two components into an end-to-end system for cross-subject visual decoding. It is evaluated on several public fMRI datasets and demonstrates state-of-the-art performance, outperforming previous methods like LiteMind and DREAM.
Critical Analysis
The paper provides a comprehensive evaluation of the MindTuner framework on multiple fMRI datasets, demonstrating its strong performance for cross-subject visual decoding. However, the authors also acknowledge some limitations:
- The visual fingerprint and semantic correction components rely on having a sufficient amount of training data for each subject. In real-world scenarios with limited data, the performance may degrade.
- The framework is currently evaluated only on decoding visual stimuli. Further research is needed to assess its generalization to other cognitive domains, such as decoding from EEG data or reconstructing visual images from fMRI.
Additionally, while the authors demonstrate state-of-the-art results, it would be valuable to further investigate the underlying mechanisms and interpretability of the visual fingerprint and semantic correction components. This could provide more insights into how the brain encodes and processes visual information across individuals.
Conclusion
The MindTuner framework represents a significant advancement in the field of cross-subject visual decoding from fMRI data. By introducing the novel concepts of visual fingerprinting and semantic correction, the system is able to effectively adapt to individual brain representations and align the decoded information across subjects.
This work has important implications for brain-computer interfaces, neuroimaging research, and our understanding of how the human brain processes visual information. Further development and application of the MindTuner approach could lead to more robust and personalized brain-computer interaction technologies, as well as new insights into the neural mechanisms underlying human perception and cognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
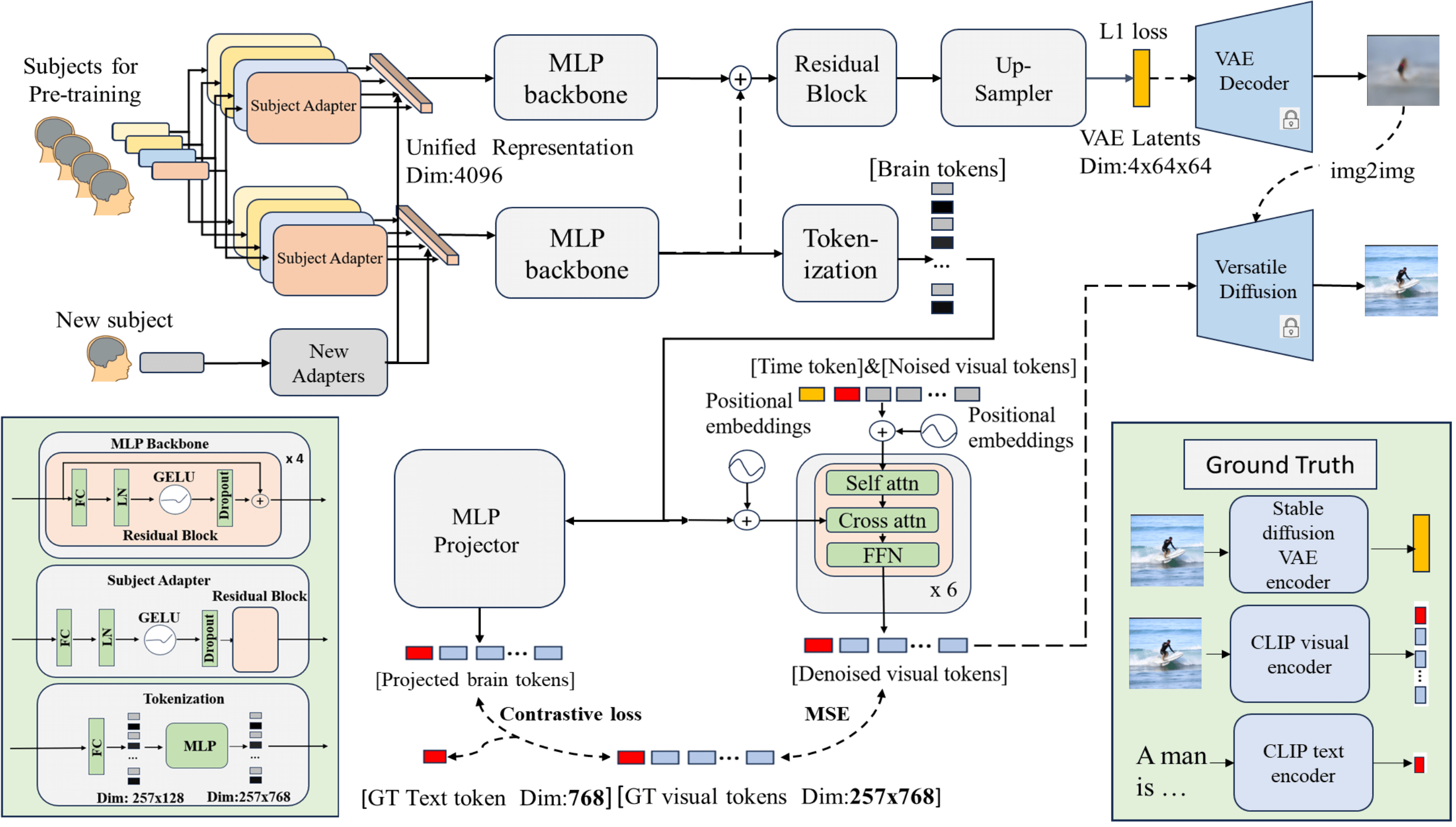
See Through Their Minds: Learning Transferable Neural Representation from Cross-Subject fMRI
Yulong Liu, Yongqiang Ma, Guibo Zhu, Haodong Jing, Nanning Zheng
0
0
Deciphering visual content from functional Magnetic Resonance Imaging (fMRI) helps illuminate the human vision system. However, the scarcity of fMRI data and noise hamper brain decoding model performance. Previous approaches primarily employ subject-specific models, sensitive to training sample size. In this paper, we explore a straightforward but overlooked solution to address data scarcity. We propose shallow subject-specific adapters to map cross-subject fMRI data into unified representations. Subsequently, a shared deeper decoding model decodes cross-subject features into the target feature space. During training, we leverage both visual and textual supervision for multi-modal brain decoding. Our model integrates a high-level perception decoding pipeline and a pixel-wise reconstruction pipeline guided by high-level perceptions, simulating bottom-up and top-down processes in neuroscience. Empirical experiments demonstrate robust neural representation learning across subjects for both pipelines. Moreover, merging high-level and low-level information improves both low-level and high-level reconstruction metrics. Additionally, we successfully transfer learned general knowledge to new subjects by training new adapters with limited training data. Compared to previous state-of-the-art methods, notably pre-training-based methods (Mind-Vis and fMRI-PTE), our approach achieves comparable or superior results across diverse tasks, showing promise as an alternative method for cross-subject fMRI data pre-training. Our code and pre-trained weights will be publicly released at https://github.com/YulongBonjour/See_Through_Their_Minds.
6/14/2024
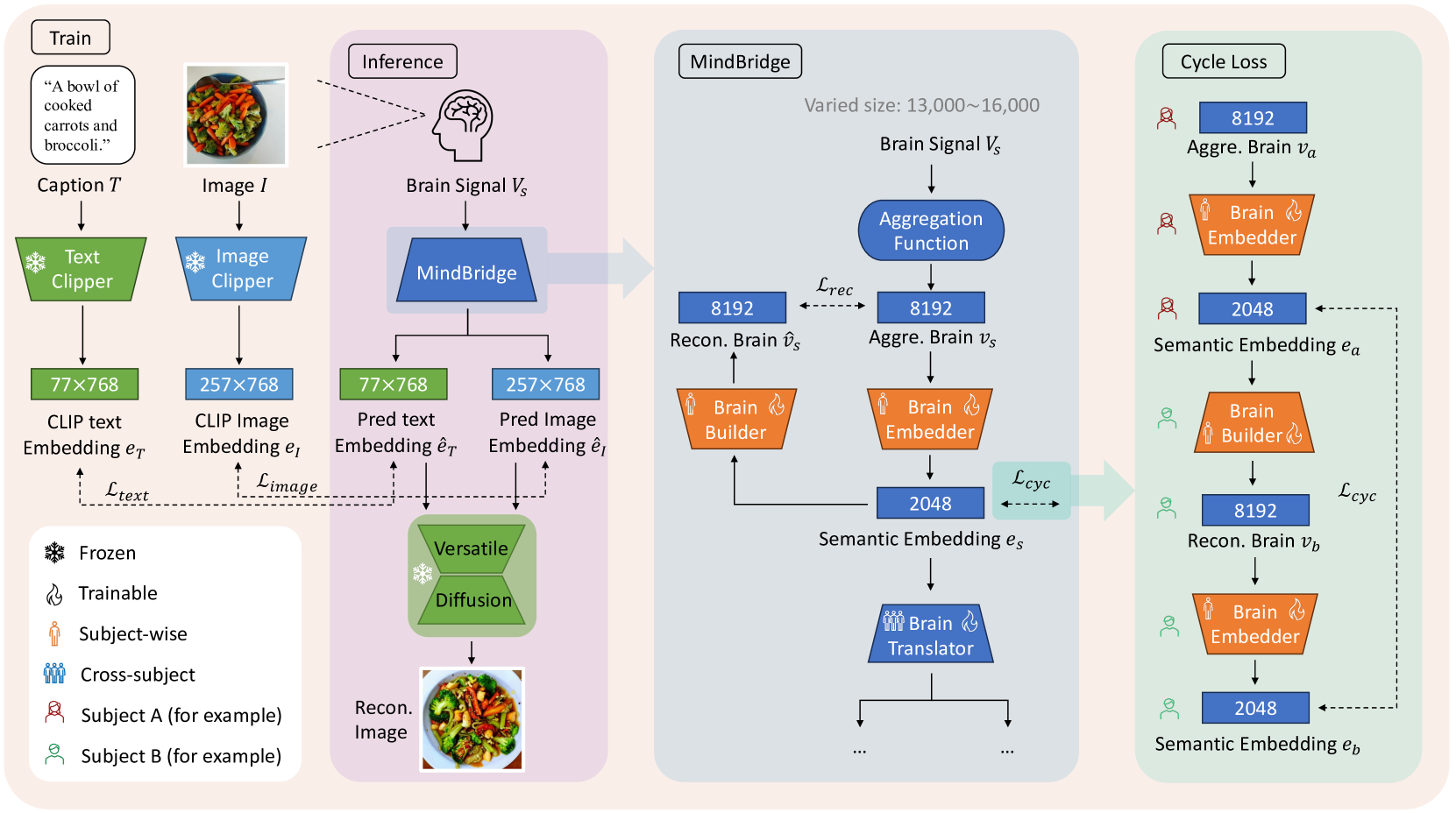
MindBridge: A Cross-Subject Brain Decoding Framework
Shizun Wang, Songhua Liu, Zhenxiong Tan, Xinchao Wang
0
0
Brain decoding, a pivotal field in neuroscience, aims to reconstruct stimuli from acquired brain signals, primarily utilizing functional magnetic resonance imaging (fMRI). Currently, brain decoding is confined to a per-subject-per-model paradigm, limiting its applicability to the same individual for whom the decoding model is trained. This constraint stems from three key challenges: 1) the inherent variability in input dimensions across subjects due to differences in brain size; 2) the unique intrinsic neural patterns, influencing how different individuals perceive and process sensory information; 3) limited data availability for new subjects in real-world scenarios hampers the performance of decoding models. In this paper, we present a novel approach, MindBridge, that achieves cross-subject brain decoding by employing only one model. Our proposed framework establishes a generic paradigm capable of addressing these challenges by introducing biological-inspired aggregation function and novel cyclic fMRI reconstruction mechanism for subject-invariant representation learning. Notably, by cycle reconstruction of fMRI, MindBridge can enable novel fMRI synthesis, which also can serve as pseudo data augmentation. Within the framework, we also devise a novel reset-tuning method for adapting a pretrained model to a new subject. Experimental results demonstrate MindBridge's ability to reconstruct images for multiple subjects, which is competitive with dedicated subject-specific models. Furthermore, with limited data for a new subject, we achieve a high level of decoding accuracy, surpassing that of subject-specific models. This advancement in cross-subject brain decoding suggests promising directions for wider applications in neuroscience and indicates potential for more efficient utilization of limited fMRI data in real-world scenarios. Project page: https://littlepure2333.github.io/MindBridge
4/12/2024
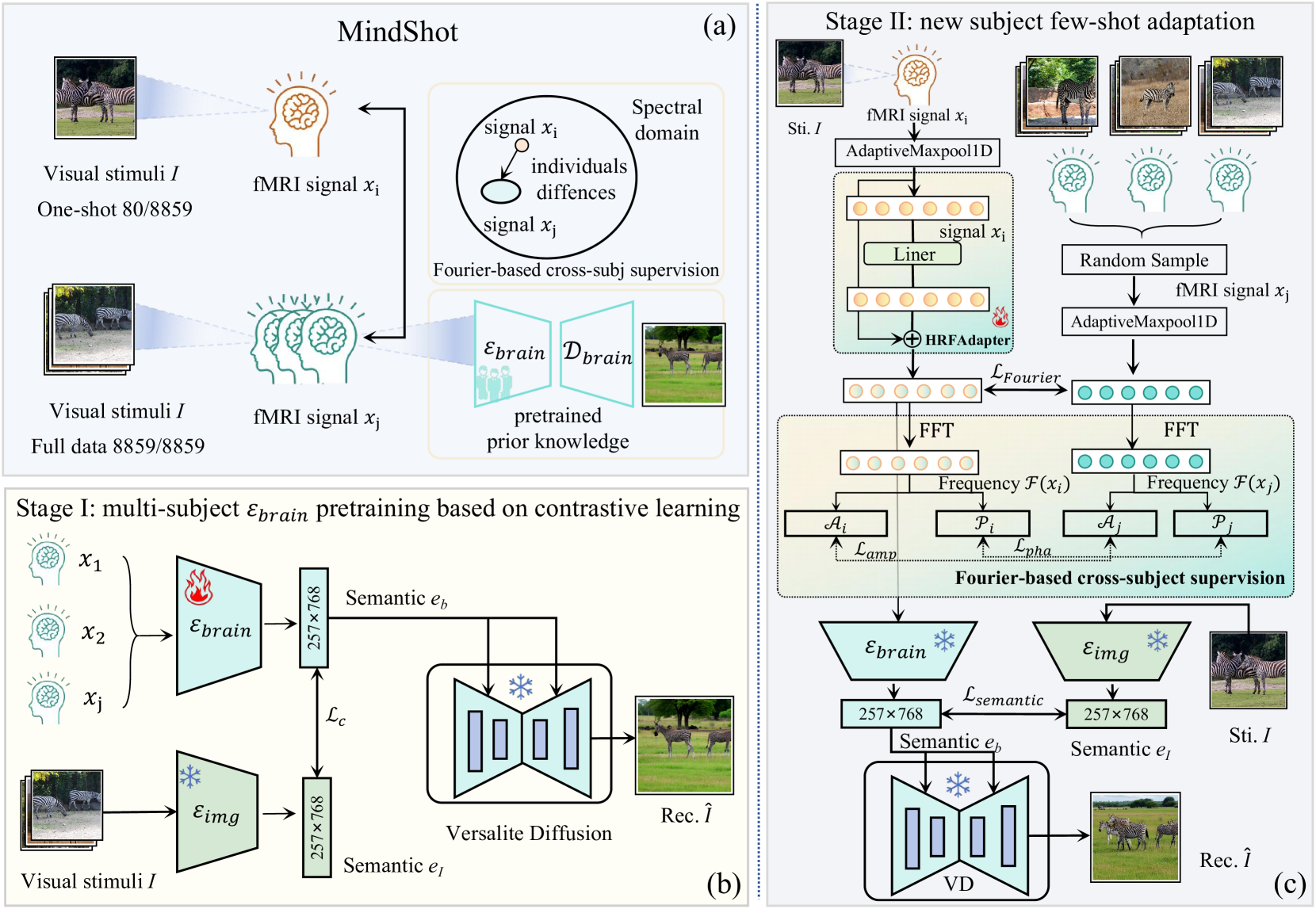
MindShot: Brain Decoding Framework Using Only One Image
Shuai Jiang, Zhu Meng, Delong Liu, Haiwen Li, Fei Su, Zhicheng Zhao
0
0
Brain decoding, which aims at reconstructing visual stimuli from brain signals, primarily utilizing functional magnetic resonance imaging (fMRI), has recently made positive progress. However, it is impeded by significant challenges such as the difficulty of acquiring fMRI-image pairs and the variability of individuals, etc. Most methods have to adopt the per-subject-per-model paradigm, greatly limiting their applications. To alleviate this problem, we introduce a new and meaningful task, few-shot brain decoding, while it will face two inherent difficulties: 1) the scarcity of fMRI-image pairs and the noisy signals can easily lead to overfitting; 2) the inadequate guidance complicates the training of a robust encoder. Therefore, a novel framework named MindShot, is proposed to achieve effective few-shot brain decoding by leveraging cross-subject prior knowledge. Firstly, inspired by the hemodynamic response function (HRF), the HRF adapter is applied to eliminate unexplainable cognitive differences between subjects with small trainable parameters. Secondly, a Fourier-based cross-subject supervision method is presented to extract additional high-level and low-level biological guidance information from signals of other subjects. Under the MindShot, new subjects and pretrained individuals only need to view images of the same semantic class, significantly expanding the model's applicability. Experimental results demonstrate MindShot's ability of reconstructing semantically faithful images in few-shot scenarios and outperforms methods based on the per-subject-per-model paradigm. The promising results of the proposed method not only validate the feasibility of few-shot brain decoding but also provide the possibility for the learning of large models under the condition of reducing data dependence.
5/27/2024

MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data
Paul S. Scotti, Mihir Tripathy, Cesar Kadir Torrico Villanueva, Reese Kneeland, Tong Chen, Ashutosh Narang, Charan Santhirasegaran, Jonathan Xu, Thomas Naselaris, Kenneth A. Norman, Tanishq Mathew Abraham
0
0
Reconstructions of visual perception from brain activity have improved tremendously, but the practical utility of such methods has been limited. This is because such models are trained independently per subject where each subject requires dozens of hours of expensive fMRI training data to attain high-quality results. The present work showcases high-quality reconstructions using only 1 hour of fMRI training data. We pretrain our model across 7 subjects and then fine-tune on minimal data from a new subject. Our novel functional alignment procedure linearly maps all brain data to a shared-subject latent space, followed by a shared non-linear mapping to CLIP image space. We then map from CLIP space to pixel space by fine-tuning Stable Diffusion XL to accept CLIP latents as inputs instead of text. This approach improves out-of-subject generalization with limited training data and also attains state-of-the-art image retrieval and reconstruction metrics compared to single-subject approaches. MindEye2 demonstrates how accurate reconstructions of perception are possible from a single visit to the MRI facility. All code is available on GitHub.
6/18/2024