CSFNet: A Cosine Similarity Fusion Network for Real-Time RGB-X Semantic Segmentation of Driving Scenes

0
🌐
Sign in to get full access
Overview
- Semantic segmentation is crucial for autonomous vehicle vision systems
- Recent studies have improved accuracy using multimodal methods, but these suffer from high complexity and slow inference
- This paper introduces the Cosine Similarity Fusion Network (CSFNet), a real-time RGB-X semantic segmentation model
Plain English Explanation
Autonomous vehicles rely on complex computer vision systems to understand their environment. A key part of this is semantic segmentation, which can identify and classify different objects and elements in a scene. Recent advances have made semantic segmentation more accurate by combining information from multiple sensors, like cameras and depth sensors, in a multimodal approach.
However, these multimodal methods tend to be computationally intensive and slow, making them difficult to implement in real-time automotive applications. To address this, the researchers proposed the Cosine Similarity Fusion Network (CSFNet). CSFNet uses a novel Cosine Similarity Attention Fusion Module (CS-AFM) that effectively combines features from different sensor modalities. This allows CSFNet to use a more efficient single-branch architecture in later stages, leading to fast and accurate semantic segmentation performance.
The key innovation in CSFNet is how it fuses the cross-modal features at lower levels to enable the use of a simpler network design at higher levels. This fusion and aggregation approach helps CSFNet achieve state-of-the-art speed among multimodal semantic segmentation models, while also maintaining competitive accuracy.
Technical Explanation
The researchers propose the Cosine Similarity Fusion Network (CSFNet) as a real-time RGB-X semantic segmentation model. They design a Cosine Similarity Attention Fusion Module (CS-AFM) that effectively rectifies and fuses features from two modalities using cross-modal similarity.
By enhancing the fusion of cross-modal features at lower levels, CS-AFM enables the use of a single-branch network architecture at higher levels. CSFNet uses this dual and single-branch approach in the encoder, along with an efficient context module and a lightweight decoder, to achieve fast and accurate predictions.
The researchers evaluate CSFNet on the Cityscapes, MFNet, and ZJU datasets for RGB-D/T/P semantic segmentation. The results show that CSFNet has competitive accuracy with state-of-the-art methods while being the fastest among multimodal semantic segmentation models. It also achieves high efficiency due to its low parameter count and computational complexity.
Critical Analysis
The paper presents a promising approach to address the computational challenges of multimodal semantic segmentation for real-time automotive applications. The Cosine Similarity Attention Fusion Module (CS-AFM) appears to be a novel and effective way to fuse cross-modal features, enabling the use of a more efficient single-branch architecture.
However, the paper does not provide extensive analysis of the limitations or potential issues with the CSFNet approach. For example, it would be valuable to understand how the model performs in diverse or challenging environmental conditions, or how it compares to other state-of-the-art real-time semantic segmentation methods that do not use multimodal inputs.
Additionally, the paper does not discuss the potential trade-offs or challenges in deploying a multimodal system with multiple sensors in a real-world autonomous vehicle setting. Further research may be needed to address practical implementation concerns, such as sensor calibration, data synchronization, and power consumption.
Conclusion
The Cosine Similarity Fusion Network (CSFNet) presents a novel approach to address the computational challenges of multimodal semantic segmentation for autonomous vehicle applications. By effectively fusing cross-modal features at lower levels, CSFNet is able to achieve state-of-the-art speed while maintaining competitive accuracy.
This research paves the way for the practical implementation of advanced computer vision techniques in real-time automotive systems, which could significantly improve the safety and performance of autonomous vehicles. However, further investigation is needed to fully understand the limitations and deployment considerations of the CSFNet approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
0
CSFNet: A Cosine Similarity Fusion Network for Real-Time RGB-X Semantic Segmentation of Driving Scenes
Danial Qashqai, Emad Mousavian, Shahriar Baradaran Shokouhi, Sattar Mirzakuchaki
Semantic segmentation, as a crucial component of complex visual interpretation, plays a fundamental role in autonomous vehicle vision systems. Recent studies have significantly improved the accuracy of semantic segmentation by exploiting complementary information and developing multimodal methods. Despite the gains in accuracy, multimodal semantic segmentation methods suffer from high computational complexity and low inference speed. Therefore, it is a challenging task to implement multimodal methods in driving applications. To address this problem, we propose the Cosine Similarity Fusion Network (CSFNet) as a real-time RGB-X semantic segmentation model. Specifically, we design a Cosine Similarity Attention Fusion Module (CS-AFM) that effectively rectifies and fuses features of two modalities. The CS-AFM module leverages cross-modal similarity to achieve high generalization ability. By enhancing the fusion of cross-modal features at lower levels, CS-AFM paves the way for the use of a single-branch network at higher levels. Therefore, we use dual and single-branch architectures in an encoder, along with an efficient context module and a lightweight decoder for fast and accurate predictions. To verify the effectiveness of CSFNet, we use the Cityscapes, MFNet, and ZJU datasets for the RGB-D/T/P semantic segmentation. According to the results, CSFNet has competitive accuracy with state-of-the-art methods while being state-of-the-art in terms of speed among multimodal semantic segmentation models. It also achieves high efficiency due to its low parameter count and computational complexity. The source code for CSFNet will be available at https://github.com/Danial-Qashqai/CSFNet.
Read more7/2/2024
0
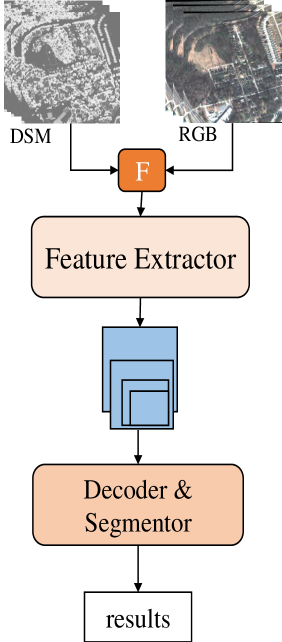
LMFNet: An Efficient Multimodal Fusion Approach for Semantic Segmentation in High-Resolution Remote Sensing
Tong Wang, Guanzhou Chen, Xiaodong Zhang, Chenxi Liu, Xiaoliang Tan, Jiaqi Wang, Chanjuan He, Wenlin Zhou
Despite the rapid evolution of semantic segmentation for land cover classification in high-resolution remote sensing imagery, integrating multiple data modalities such as Digital Surface Model (DSM), RGB, and Near-infrared (NIR) remains a challenge. Current methods often process only two types of data, missing out on the rich information that additional modalities can provide. Addressing this gap, we propose a novel textbf{L}ightweight textbf{M}ultimodal data textbf{F}usion textbf{Net}work (LMFNet) to accomplish the tasks of fusion and semantic segmentation of multimodal remote sensing images. LMFNet uniquely accommodates various data types simultaneously, including RGB, NirRG, and DSM, through a weight-sharing, multi-branch vision transformer that minimizes parameter count while ensuring robust feature extraction. Our proposed multimodal fusion module integrates a textit{Multimodal Feature Fusion Reconstruction Layer} and textit{Multimodal Feature Self-Attention Fusion Layer}, which can reconstruct and fuse multimodal features. Extensive testing on public datasets such as US3D, ISPRS Potsdam, and ISPRS Vaihingen demonstrates the effectiveness of LMFNet. Specifically, it achieves a mean Intersection over Union ($mIoU$) of 85.09% on the US3D dataset, marking a significant improvement over existing methods. Compared to unimodal approaches, LMFNet shows a 10% enhancement in $mIoU$ with only a 0.5M increase in parameter count. Furthermore, against bimodal methods, our approach with trilateral inputs enhances $mIoU$ by 0.46 percentage points.
Read more4/23/2024
🌐
0
Continual Road-Scene Semantic Segmentation via Feature-Aligned Symmetric Multi-Modal Network
Francesco Barbato, Elena Camuffo, Simone Milani, Pietro Zanuttigh
State-of-the-art multimodal semantic segmentation strategies combining LiDAR and color data are usually designed on top of asymmetric information-sharing schemes and assume that both modalities are always available. This strong assumption may not hold in real-world scenarios, where sensors are prone to failure or can face adverse conditions that make the acquired information unreliable. This problem is exacerbated when continual learning scenarios are considered since they have stringent data reliability constraints. In this work, we re-frame the task of multimodal semantic segmentation by enforcing a tightly coupled feature representation and a symmetric information-sharing scheme, which allows our approach to work even when one of the input modalities is missing. We also introduce an ad-hoc class-incremental continual learning scheme, proving our approach's effectiveness and reliability even in safety-critical settings, such as autonomous driving. We evaluate our approach on the SemanticKITTI dataset, achieving impressive performances.
Read more6/26/2024

0
New!BAFNet: Bilateral Attention Fusion Network for Lightweight Semantic Segmentation of Urban Remote Sensing Images
Wentao Wang, Xili Wang
Large-scale semantic segmentation networks often achieve high performance, while their application can be challenging when faced with limited sample sizes and computational resources. In scenarios with restricted network size and computational complexity, models encounter significant challenges in capturing long-range dependencies and recovering detailed information in images. We propose a lightweight bilateral semantic segmentation network called bilateral attention fusion network (BAFNet) to efficiently segment high-resolution urban remote sensing images. The model consists of two paths, namely dependency path and remote-local path. The dependency path utilizes large kernel attention to acquire long-range dependencies in the image. Besides, multi-scale local attention and efficient remote attention are designed to construct remote-local path. Finally, a feature aggregation module is designed to effectively utilize the different features of the two paths. Our proposed method was tested on public high-resolution urban remote sensing datasets Vaihingen and Potsdam, with mIoU reaching 83.20% and 86.53%, respectively. As a lightweight semantic segmentation model, BAFNet not only outperforms advanced lightweight models in accuracy but also demonstrates comparable performance to non-lightweight state-of-the-art methods on two datasets, despite a tenfold variance in floating-point operations and a fifteenfold difference in network parameters.
Read more9/17/2024