A CT Image Denoising Method with Residual Encoder-Decoder Network
2404.01553
0
0
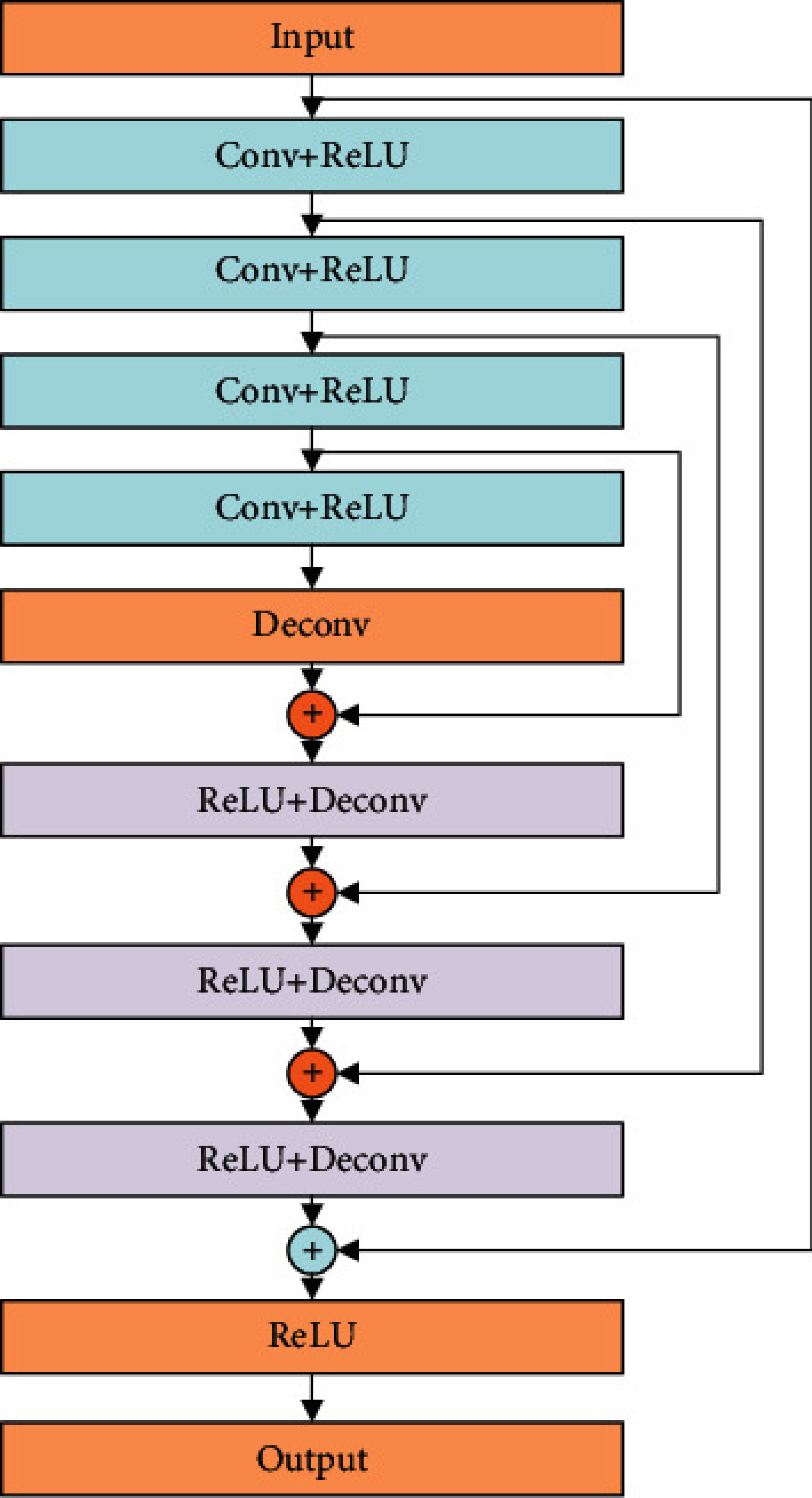
Abstract
Utilizing a low-dose CT approach significantly reduces the radiation exposure for patients, yet it introduces challenges, such as increased noise and artifacts in the resultant images, which can hinder accurate medical diagnostics. Traditional methods for noise reduction struggle with preserving image textures due to the complexity of modeling statistical properties directly within the image domain. To address these limitations, this study introduces an enhanced noise-reduction technique centered around an advanced residual encoder-decoder network. By incorporating recursive processing into the foundational network, this method reduces computational complexity and enhances the effectiveness of noise reduction. Furthermore, the introduction of a root-mean-square error and perceptual loss functions aims to retain the integrity of the images' textural details. The enhanced technique also includes optimized tissue segmentation, improving artifact management post-improvement. Validation using the TCGA-COAD clinical dataset demonstrates superior performance in both noise reduction and image quality, as measured by post-denoising PSNR and SSIM, compared to the existing WGAN approach. This advancement in CT image processing offers a practical solution for clinical applications, achieving lower computational demands and faster processing times without compromising image quality.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a new method for denoising CT images using a residual encoder-decoder network.
- The goal is to improve the quality of low-dose CT images, which can suffer from high levels of noise.
- The proposed model leverages the power of residual learning and a U-Net-like architecture to effectively remove noise while preserving important image details.
Plain English Explanation
Computed Tomography (CT) scans are a widely used medical imaging technique that allow doctors to see detailed images of the body's internal structures. However, low-dose CT scans, which use less radiation, can sometimes result in noisy, lower-quality images. This can make it harder for doctors to accurately diagnose and treat medical conditions.
The authors of this paper have developed a new machine learning model to address this problem. Their "residual encoder-decoder network" is designed to take a low-quality, noisy CT image as input and output a clean, high-quality version of the same image.
The key ideas behind this model are:
-
Residual Learning: The model is built on the concept of "residual learning," which allows it to focus on learning the difference between the noisy input image and the clean target image, rather than trying to learn the entire clean image from scratch. This makes the model more efficient and effective.
-
Encoder-Decoder Architecture: The model uses an "encoder-decoder" structure, similar to the popular U-Net architecture [link to "Imaging Transformer for MRI Denoising" paper]. The encoder part of the model analyzes the input image and extracts important features, while the decoder part uses these features to reconstruct a clean output image.
-
Noise Removal: By combining residual learning and the encoder-decoder structure, the model is able to effectively identify and remove noise from the input CT images, while preserving important details that are crucial for medical diagnosis.
Overall, this new CT image denoising method has the potential to significantly improve the quality of low-dose CT scans, making them more useful for doctors and patients without the need for higher radiation doses.
Technical Explanation
The proposed method, known as a "Residual Encoder-Decoder Network" (REDN), is a deep learning-based approach for CT image denoising. The model follows a U-Net-like [link to "DRCT: Saving Image Super-Resolution Away from Global Operations"] architecture, with an encoder network that extracts features from the input image and a decoder network that reconstructs the clean output image.
The key innovation of the REDN model is the use of residual learning. Instead of directly learning the mapping between the noisy input and the clean target image, the model learns the residual, or difference, between the two. This residual learning approach has been shown to improve the model's efficiency and effectiveness in various image-to-image translation tasks.
The encoder part of the REDN model consists of multiple convolutional blocks, each followed by batch normalization and a ReLU activation function. The decoder part mirrors the encoder, with upsampling and skip connections to enable the model to recover fine details from the input. The final output of the model is the denoised CT image.
The authors train and evaluate the REDN model on a dataset of low-dose and normal-dose CT images, demonstrating significant improvements in image quality metrics such as PSNR and SSIM compared to other state-of-the-art denoising methods [link to "Real-Time Noise Source Estimation for Camera System" paper]. They also show that the REDN model can effectively preserve important diagnostic features in the denoised images.
Critical Analysis
The authors have provided a comprehensive evaluation of their proposed REDN model, including comparisons to other leading denoising approaches. The results demonstrate the effectiveness of the residual learning and encoder-decoder architecture in addressing the challenges of low-dose CT image denoising.
However, the paper does not address some potential limitations of the method. For example, it is unclear how the REDN model would perform on a wider range of CT image characteristics, such as different anatomical regions or imaging protocols. Additionally, the paper does not discuss the computational complexity and inference time of the model, which are important factors for real-world medical imaging applications [link to "Dynamic Pre-Training Towards Efficient Scalable All" paper].
Further research could explore the generalization of the REDN model, as well as investigate ways to optimize its efficiency and deployability in clinical settings. Incorporating additional training data, such as images from different CT scanners or hospitals, could also help to improve the model's robustness and versatility.
Conclusion
The proposed Residual Encoder-Decoder Network (REDN) is a promising approach for improving the quality of low-dose CT images. By leveraging the power of residual learning and a U-Net-like architecture, the REDN model is able to effectively remove noise while preserving important diagnostic details.
This work has the potential to significantly enhance the usefulness of low-dose CT scans, which could lead to reduced radiation exposure for patients and improved medical diagnosis and treatment. While further research is needed to fully understand the limitations and potential of the REDN model, this paper represents an important step forward in the field of medical image denoising.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Assessing The Impact of CNN Auto Encoder-Based Image Denoising on Image Classification Tasks
Mohsen Hami, Mahdi JameBozorg
0
0
Images captured from the real world are often affected by different types of noise, which can significantly impact the performance of Computer Vision systems and the quality of visual data. This study presents a novel approach for defect detection in casting product noisy images, specifically focusing on submersible pump impellers. The methodology involves utilizing deep learning models such as VGG16, InceptionV3, and other models in both the spatial and frequency domains to identify noise types and defect status. The research process begins with preprocessing images, followed by applying denoising techniques tailored to specific noise categories. The goal is to enhance the accuracy and robustness of defect detection by integrating noise detection and denoising into the classification pipeline. The study achieved remarkable results using VGG16 for noise type classification in the frequency domain, achieving an accuracy of over 99%. Removal of salt and pepper noise resulted in an average SSIM of 87.9, while Gaussian noise removal had an average SSIM of 64.0, and periodic noise removal yielded an average SSIM of 81.6. This comprehensive approach showcases the effectiveness of the deep AutoEncoder model and median filter, for denoising strategies in real-world industrial applications. Finally, our study reports significant improvements in binary classification accuracy for defect detection compared to previous methods. For the VGG16 classifier, accuracy increased from 94.6% to 97.0%, demonstrating the effectiveness of the proposed noise detection and denoising approach. Similarly, for the InceptionV3 classifier, accuracy improved from 84.7% to 90.0%, further validating the benefits of integrating noise analysis into the classification pipeline.
5/14/2024
🎯
Imaging transformer for MRI denoising with the SNR unit training: enabling generalization across field-strengths, imaging contrasts, and anatomy
Hui Xue, Sarah Hooper, Azaan Rehman, Iain Pierce, Thomas Treibel, Rhodri Davies, W Patricia Bandettini, Rajiv Ramasawmy, Ahsan Javed, Zheren Zhu, Yang Yang, James Moon, Adrienne Campbell, Peter Kellman
0
0
The ability to recover MRI signal from noise is key to achieve fast acquisition, accurate quantification, and high image quality. Past work has shown convolutional neural networks can be used with abundant and paired low and high-SNR images for training. However, for applications where high-SNR data is difficult to produce at scale (e.g. with aggressive acceleration, high resolution, or low field strength), training a new denoising network using a large quantity of high-SNR images can be infeasible. In this study, we overcome this limitation by improving the generalization of denoising models, enabling application to many settings beyond what appears in the training data. Specifically, we a) develop a training scheme that uses complex MRIs reconstructed in the SNR units (i.e., the images have a fixed noise level, SNR unit training) and augments images with realistic noise based on coil g-factor, and b) develop a novel imaging transformer (imformer) to handle 2D, 2D+T, and 3D MRIs in one model architecture. Through empirical evaluation, we show this combination improves performance compared to CNN models and improves generalization, enabling a denoising model to be used across field-strengths, image contrasts, and anatomy.
4/4/2024
🤿
Denoising: from classical methods to deep CNNs
Jean-Eric Campagne
0
0
This paper aims to explore the evolution of image denoising in a pedagological way. We briefly review classical methods such as Fourier analysis and wavelet bases, highlighting the challenges they faced until the emergence of neural networks, notably the U-Net, in the 2010s. The remarkable performance of these networks has been demonstrated in studies such as Kadkhodaie et al. (2024). They exhibit adaptability to various image types, including those with fixed regularity, facial images, and bedroom scenes, achieving optimal results and biased towards geometry-adaptive harmonic basis. The introduction of score diffusion has played a crucial role in image generation. In this context, denoising becomes essential as it facilitates the estimation of probability density scores. We discuss the prerequisites for genuine learning of probability densities, offering insights that extend from mathematical research to the implications of universal structures.
4/30/2024
✨
WiTUnet: A U-Shaped Architecture Integrating CNN and Transformer for Improved Feature Alignment and Local Information Fusion
Bin Wang, Fei Deng, Peifan Jiang, Shuang Wang, Xiao Han, Zhixuan Zhang
0
0
Low-dose computed tomography (LDCT) has become the technology of choice for diagnostic medical imaging, given its lower radiation dose compared to standard CT, despite increasing image noise and potentially affecting diagnostic accuracy. To address this, advanced deep learning-based LDCT denoising algorithms have been developed, primarily using Convolutional Neural Networks (CNNs) or Transformer Networks with the Unet architecture. This architecture enhances image detail by integrating feature maps from the encoder and decoder via skip connections. However, current methods often overlook enhancements to the Unet architecture itself, focusing instead on optimizing encoder and decoder structures. This approach can be problematic due to the significant differences in feature map characteristics between the encoder and decoder, where simple fusion strategies may not effectively reconstruct images.In this paper, we introduce WiTUnet, a novel LDCT image denoising method that utilizes nested, dense skip pathways instead of traditional skip connections to improve feature integration. WiTUnet also incorporates a windowed Transformer structure to process images in smaller, non-overlapping segments, reducing computational load. Additionally, the integration of a Local Image Perception Enhancement (LiPe) module in both the encoder and decoder replaces the standard multi-layer perceptron (MLP) in Transformers, enhancing local feature capture and representation. Through extensive experimental comparisons, WiTUnet has demonstrated superior performance over existing methods in key metrics such as Peak Signal-to-Noise Ratio (PSNR), Structural Similarity (SSIM), and Root Mean Square Error (RMSE), significantly improving noise removal and image quality.
4/30/2024