CVT-Occ: Cost Volume Temporal Fusion for 3D Occupancy Prediction

0
Sign in to get full access
Overview
- Cost Volume Temporal Fusion for 3D Occupancy Prediction (CVT-Occ) is a research paper that proposes a novel approach for predicting 3D occupancy maps from sequential RGB-D data.
- The key idea is to leverage temporal information by fusing cost volumes across multiple frames, enabling more accurate and consistent 3D occupancy predictions.
- The paper presents a detailed architecture and experimental evaluation, demonstrating the effectiveness of the proposed method.
Plain English Explanation
The paper focuses on the problem of 3D Semantic Occupancy Prediction, which aims to predict a 3D map of occupied and free space in a scene based on sensor data. This is an important task for applications like robot navigation and autonomous driving.
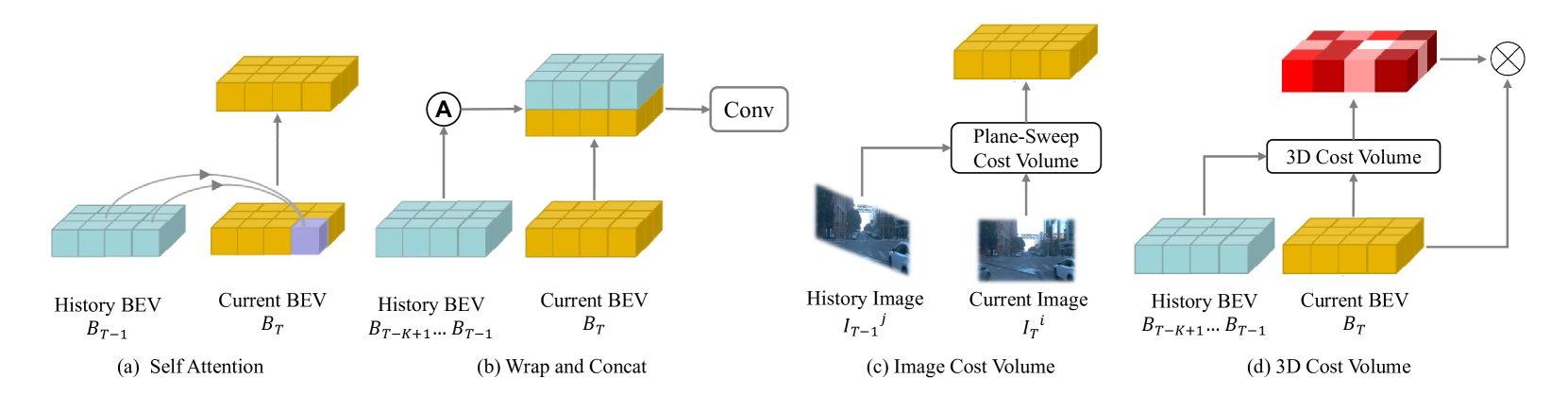
The authors of the CVT-Occ paper propose a new method that takes advantage of the temporal information in a sequence of RGB-D (color and depth) frames. Their key insight is that by fusing the "cost volumes" (a representation of the occupancy likelihood) across multiple frames, they can make more accurate and consistent 3D occupancy predictions.
The cost volumes capture the occupancy likelihood at different depths in the scene, and the temporal fusion helps resolve ambiguities and smooth out inconsistencies that might occur in individual frames. This allows the model to better track and predict the 3D structure of the environment over time.
The paper presents a detailed neural network architecture that implements this cost volume temporal fusion approach, along with comprehensive experimental evaluations demonstrating its advantages over previous methods. The results show that CVT-Occ outperforms other state-of-the-art techniques for 3D occupancy prediction, making it a promising approach for real-world applications.
Technical Explanation
The CVT-Occ method takes a sequence of RGB-D frames as input and produces a 3D occupancy map as output. The core of the approach is a neural network architecture that consists of several key components:
- Cost Volume Computation: The network first computes a cost volume for each input frame, which represents the likelihood of occupancy at different depths in the scene.
- Temporal Fusion: The cost volumes from multiple frames are then fused together using a series of 3D convolutional layers and attention mechanisms. This allows the model to leverage the temporal information to make more consistent and accurate occupancy predictions.
- Occupancy Prediction: The fused cost volume is then used to predict the final 3D occupancy map, which indicates the occupied and free space in the scene.
The authors conducted extensive experiments to evaluate the performance of CVT-Occ on several benchmark datasets for 3D occupancy prediction. They compared their approach to a variety of baseline methods and found that CVT-Occ consistently outperformed the state of the art, demonstrating the value of the temporal fusion strategy.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the CVT-Occ method, with comparisons to multiple baselines on several standard benchmarks. The results clearly demonstrate the advantages of the proposed approach over previous techniques.
However, the paper does not discuss any significant limitations or caveats of the method. For example, it would be helpful to know how the performance of CVT-Occ scales with the length of the input sequence, or how it might be affected by sensor noise or occlusions in the real world.
Additionally, while the paper provides detailed technical explanations, it could benefit from more intuitive explanations or analogies to help a general audience understand the key insights and contributions of the work.
Conclusion
The CVT-Occ paper presents a novel and effective approach for 3D occupancy prediction that leverages the temporal information in RGB-D sequences. By fusing cost volumes across multiple frames, the method is able to make more accurate and consistent predictions of the 3D structure of the environment.
The technical contributions and experimental results demonstrate the value of this approach, which could have important applications in areas like robot navigation, autonomous driving, and scene understanding. While the paper could benefit from a more thorough discussion of the method's limitations and potential future directions, it represents a significant advance in the field of 3D semantic occupancy prediction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
CVT-Occ: Cost Volume Temporal Fusion for 3D Occupancy Prediction
Zhangchen Ye, Tao Jiang, Chenfeng Xu, Yiming Li, Hang Zhao
Vision-based 3D occupancy prediction is significantly challenged by the inherent limitations of monocular vision in depth estimation. This paper introduces CVT-Occ, a novel approach that leverages temporal fusion through the geometric correspondence of voxels over time to improve the accuracy of 3D occupancy predictions. By sampling points along the line of sight of each voxel and integrating the features of these points from historical frames, we construct a cost volume feature map that refines current volume features for improved prediction outcomes. Our method takes advantage of parallax cues from historical observations and employs a data-driven approach to learn the cost volume. We validate the effectiveness of CVT-Occ through rigorous experiments on the Occ3D-Waymo dataset, where it outperforms state-of-the-art methods in 3D occupancy prediction with minimal additional computational cost. The code is released at url{https://github.com/Tsinghua-MARS-Lab/CVT-Occ}.
Read more9/26/2024

0
Co-Occ: Coupling Explicit Feature Fusion with Volume Rendering Regularization for Multi-Modal 3D Semantic Occupancy Prediction
Jingyi Pan, Zipeng Wang, Lin Wang
3D semantic occupancy prediction is a pivotal task in the field of autonomous driving. Recent approaches have made great advances in 3D semantic occupancy predictions on a single modality. However, multi-modal semantic occupancy prediction approaches have encountered difficulties in dealing with the modality heterogeneity, modality misalignment, and insufficient modality interactions that arise during the fusion of different modalities data, which may result in the loss of important geometric and semantic information. This letter presents a novel multi-modal, i.e., LiDAR-camera 3D semantic occupancy prediction framework, dubbed Co-Occ, which couples explicit LiDAR-camera feature fusion with implicit volume rendering regularization. The key insight is that volume rendering in the feature space can proficiently bridge the gap between 3D LiDAR sweeps and 2D images while serving as a physical regularization to enhance LiDAR-camera fused volumetric representation. Specifically, we first propose a Geometric- and Semantic-aware Fusion (GSFusion) module to explicitly enhance LiDAR features by incorporating neighboring camera features through a K-nearest neighbors (KNN) search. Then, we employ volume rendering to project the fused feature back to the image planes for reconstructing color and depth maps. These maps are then supervised by input images from the camera and depth estimations derived from LiDAR, respectively. Extensive experiments on the popular nuScenes and SemanticKITTI benchmarks verify the effectiveness of our Co-Occ for 3D semantic occupancy prediction. The project page is available at https://rorisis.github.io/Co-Occ_project-page/.
Read more5/24/2024

0
COTR: Compact Occupancy TRansformer for Vision-based 3D Occupancy Prediction
Qihang Ma, Xin Tan, Yanyun Qu, Lizhuang Ma, Zhizhong Zhang, Yuan Xie
The autonomous driving community has shown significant interest in 3D occupancy prediction, driven by its exceptional geometric perception and general object recognition capabilities. To achieve this, current works try to construct a Tri-Perspective View (TPV) or Occupancy (OCC) representation extending from the Bird-Eye-View perception. However, compressed views like TPV representation lose 3D geometry information while raw and sparse OCC representation requires heavy but redundant computational costs. To address the above limitations, we propose Compact Occupancy TRansformer (COTR), with a geometry-aware occupancy encoder and a semantic-aware group decoder to reconstruct a compact 3D OCC representation. The occupancy encoder first generates a compact geometrical OCC feature through efficient explicit-implicit view transformation. Then, the occupancy decoder further enhances the semantic discriminability of the compact OCC representation by a coarse-to-fine semantic grouping strategy. Empirical experiments show that there are evident performance gains across multiple baselines, e.g., COTR outperforms baselines with a relative improvement of 8%-15%, demonstrating the superiority of our method.
Read more4/12/2024

0
OccFusion: Depth Estimation Free Multi-sensor Fusion for 3D Occupancy Prediction
Ji Zhang, Yiran Ding, Zixin Liu
3D occupancy prediction based on multi-sensor fusion,crucial for a reliable autonomous driving system, enables fine-grained understanding of 3D scenes. Previous fusion-based 3D occupancy predictions relied on depth estimation for processing 2D image features. However, depth estimation is an ill-posed problem, hindering the accuracy and robustness of these methods. Furthermore, fine-grained occupancy prediction demands extensive computational resources. To address these issues, we propose OccFusion, a depth estimation free multi-modal fusion framework. Additionally, we introduce a generalizable active training method and an active decoder that can be applied to any occupancy prediction model, with the potential to enhance their performance. Experiments conducted on nuScenes-Occupancy and nuScenes-Occ3D demonstrate our framework's superior performance. Detailed ablation studies highlight the effectiveness of each proposed method.
Read more7/11/2024