D2SL: Decouple Defogging and Semantic Learning for Foggy Domain-Adaptive Segmentation

0
Sign in to get full access
Overview
- The paper presents a novel approach called D²SL (Decouple Defogging and Semantic Learning) for foggy domain-adaptive segmentation.
- It aims to decouple the tasks of defogging and semantic learning to improve the performance of semantic segmentation in foggy conditions.
- The proposed method outperforms existing state-of-the-art approaches on several benchmark datasets.
Plain English Explanation
Semantic segmentation is the task of categorizing every pixel in an image into different meaningful objects or classes, such as cars, people, buildings, and so on. However, this can be challenging in real-world scenarios where images may be affected by foggy or hazy conditions, which can degrade the performance of segmentation models.
The D²SL approach presented in this paper tries to address this problem by separating the tasks of "defogging" the image and "learning the semantics" (i.e., the object categories) into two distinct components. The idea is that by decoupling these two tasks, the model can focus on each one more effectively, leading to better overall segmentation performance in foggy conditions.
The defogging component is responsible for removing the hazy or foggy effects from the input image, while the semantic learning component then processes the "de-fogged" image to accurately identify the different objects and their locations. By breaking down the problem in this way, the model can learn more robust and generalized representations, which can then be applied to segmentation tasks in various real-world foggy environments.
The researchers demonstrate the effectiveness of their D²SL approach through extensive experiments on several benchmark datasets, showing that it outperforms existing state-of-the-art methods for foggy domain-adaptive segmentation.
Technical Explanation
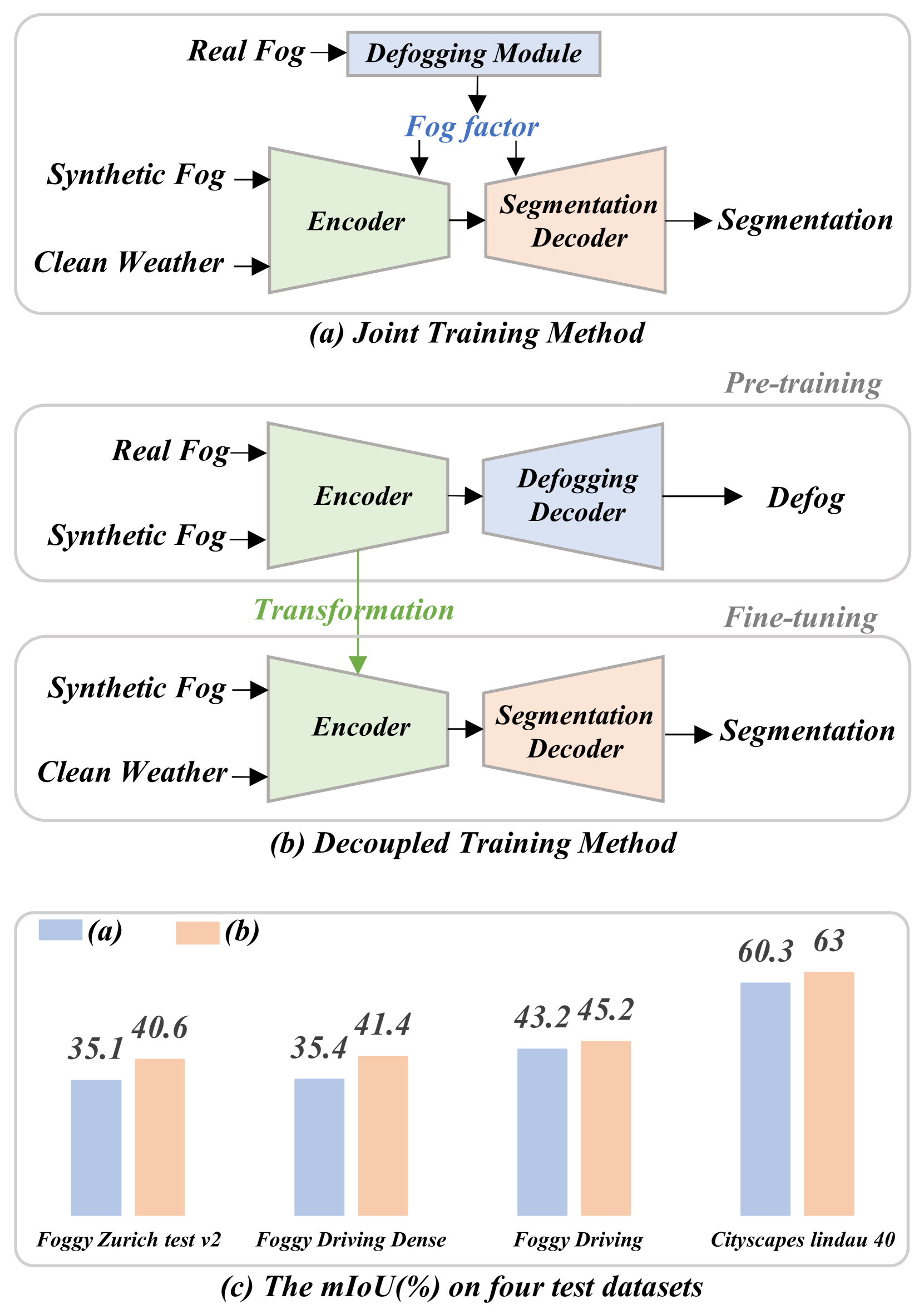
The D²SL (Decouple Defogging and Semantic Learning) approach presented in this paper aims to address the challenge of semantic segmentation in foggy conditions. The key idea is to decouple the tasks of defogging the input image and learning the semantic representations, rather than attempting to solve both problems simultaneously.
The proposed architecture consists of two main components: a defogging module and a semantic learning module. The defogging module is responsible for removing the hazy or foggy effects from the input image, while the semantic learning module then processes the "de-fogged" image to perform the semantic segmentation task.
By separating these two tasks, the model can focus on each one more effectively. The defogging module can learn to enhance the visual clarity of the input, while the semantic learning module can specialize in recognizing and localizing the different objects and classes in the scene.
The researchers also introduce a domain adversarial training strategy, which helps the model learn domain-invariant representations that can generalize well to different foggy environments. This is achieved by adding a domain discriminator that tries to predict the domain of the input image (e.g., clear vs. foggy), while the main segmentation model is trained to fool the discriminator, effectively learning features that are not specific to a particular domain.
The experiments conducted on several benchmark datasets, including Cityscapes, BDDS, and Foggy Driving, demonstrate the effectiveness of the D²SL approach. The results show that it outperforms existing state-of-the-art methods for foggy domain-adaptive semantic segmentation, highlighting the benefits of decoupling the defogging and semantic learning tasks.
Critical Analysis
The D²SL approach presented in this paper addresses an important problem in the field of semantic segmentation, where real-world images can be affected by various environmental conditions, such as fog or haze, which can degrade the performance of segmentation models.
One of the key strengths of the proposed method is the decoupling of the defogging and semantic learning tasks, which allows the model to focus on each component more effectively. This design choice is well-justified and the experimental results demonstrate the advantages of this approach over existing techniques.
However, the paper does not provide a detailed analysis of the computational and memory requirements of the D²SL model, which could be an important consideration for practical deployment, especially in resource-constrained environments. Additionally, the researchers could have explored the sensitivity of the model to different levels of fog or haze, as real-world conditions can vary greatly.
Furthermore, the paper does not discuss the potential limitations or failure cases of the proposed approach. It would be valuable to understand the scenarios where the D²SL model might struggle, as this could guide future research directions and improvements.
Despite these minor limitations, the D²SL approach represents a significant contribution to the field of foggy domain-adaptive semantic segmentation, and the ideas presented in this paper could inspire further research and development in this area.
Conclusion
The D²SL (Decouple Defogging and Semantic Learning) method proposed in this paper offers a novel and effective solution for improving semantic segmentation performance in the presence of foggy or hazy conditions. By decoupling the tasks of defogging and semantic learning, the model can focus on each component more effectively, leading to improved generalization and robustness to various real-world environmental factors.
The extensive experiments conducted on benchmark datasets demonstrate the superiority of the D²SL approach over existing state-of-the-art methods, highlighting its potential for practical applications in areas such as autonomous driving, surveillance, and scene understanding. The insights and techniques presented in this paper could also inspire further research and development in the broader field of domain-adaptive computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
D2SL: Decouple Defogging and Semantic Learning for Foggy Domain-Adaptive Segmentation
Xuan Sun, Zhanfu An, Yuyu Liu
We investigated domain adaptive semantic segmentation in foggy weather scenarios, which aims to enhance the utilization of unlabeled foggy data and improve the model's adaptability to foggy conditions. Current methods rely on clear images as references, jointly learning defogging and segmentation for foggy images. Despite making some progress, there are still two main drawbacks: (1) the coupling of segmentation and defogging feature representations, resulting in a decrease in semantic representation capability, and (2) the failure to leverage real fog priors in unlabeled foggy data, leading to insufficient model generalization ability. To address these issues, we propose a novel training framework, Decouple Defogging and Semantic learning, called D2SL, aiming to alleviate the adverse impact of defogging tasks on the final segmentation task. In this framework, we introduce a domain-consistent transfer strategy to establish a connection between defogging and segmentation tasks. Furthermore, we design a real fog transfer strategy to improve defogging effects by fully leveraging the fog priors from real foggy images. Our approach enhances the semantic representations required for segmentation during the defogging learning process and maximizes the representation capability of fog invariance by effectively utilizing real fog data. Comprehensive experiments validate the effectiveness of the proposed method.
Read more4/9/2024

0
WeatherProof: Leveraging Language Guidance for Semantic Segmentation in Adverse Weather
Blake Gella, Howard Zhang, Rishi Upadhyay, Tiffany Chang, Nathan Wei, Matthew Waliman, Yunhao Ba, Celso de Melo, Alex Wong, Achuta Kadambi
We propose a method to infer semantic segmentation maps from images captured under adverse weather conditions. We begin by examining existing models on images degraded by weather conditions such as rain, fog, or snow, and found that they exhibit a large performance drop as compared to those captured under clear weather. To control for changes in scene structures, we propose WeatherProof, the first semantic segmentation dataset with accurate clear and adverse weather image pairs that share an underlying scene. Through this dataset, we analyze the error modes in existing models and found that they were sensitive to the highly complex combination of different weather effects induced on the image during capture. To improve robustness, we propose a way to use language as guidance by identifying contributions of adverse weather conditions and injecting that as side information. Models trained using our language guidance exhibit performance gains by up to 10.2% in mIoU on WeatherProof, up to 8.44% in mIoU on the widely used ACDC dataset compared to standard training techniques, and up to 6.21% in mIoU on the ACDC dataset as compared to previous SOTA methods.
Read more5/9/2024
🖼️
0
Enhancing Autonomous Vehicle Perception in Adverse Weather through Image Augmentation during Semantic Segmentation Training
Ethan Kou, Noah Curran
Robust perception is crucial in autonomous vehicle navigation and localization. Visual processing tasks, like semantic segmentation, should work in varying weather conditions and during different times of day. Semantic segmentation is where each pixel is assigned a class, which is useful for locating overall features (1). Training a segmentation model requires large amounts of data, and the labeling process for segmentation data is especially tedious. Additionally, many large datasets include only images taken in clear weather. This is a problem because training a model exclusively on clear weather data hinders performance in adverse weather conditions like fog or rain. We hypothesize that given a dataset of only clear days images, applying image augmentation (such as random rain, fog, and brightness) during training allows for domain adaptation to diverse weather conditions. We used CARLA, a 3D realistic autonomous vehicle simulator, to collect 1200 images in clear weather composed of 29 classes from 10 different towns (2). We also collected 1200 images of random weather effects. We trained encoder-decoder UNet models to perform semantic segmentation. Applying augmentations significantly improved segmentation under weathered night conditions (p < 0.001). However, models trained on weather data have significantly lower losses than those trained on augmented data in all conditions except for clear days. This shows there is room for improvement in the domain adaptation approach. Future work should test more types of augmentations and also use real-life images instead of CARLA. Ideally, the augmented model meets or exceeds the performance of the weather model.
Read more8/15/2024
🔎
0
Domain Adaptation based Object Detection for Autonomous Driving in Foggy and Rainy Weather
Jinlong Li, Runsheng Xu, Xinyu Liu, Jin Ma, Baolu Li, Qin Zou, Jiaqi Ma, Hongkai Yu
Typically, object detection methods for autonomous driving that rely on supervised learning make the assumption of a consistent feature distribution between the training and testing data, this such assumption may fail in different weather conditions. Due to the domain gap, a detection model trained under clear weather may not perform well in foggy and rainy conditions. Overcoming detection bottlenecks in foggy and rainy weather is a real challenge for autonomous vehicles deployed in the wild. To bridge the domain gap and improve the performance of object detection in foggy and rainy weather, this paper presents a novel framework for domain-adaptive object detection. The adaptations at both the image-level and object-level are intended to minimize the differences in image style and object appearance between domains. Furthermore, in order to improve the model's performance on challenging examples, we introduce a novel adversarial gradient reversal layer that conducts adversarial mining on difficult instances in addition to domain adaptation. Additionally, we suggest generating an auxiliary domain through data augmentation to enforce a new domain-level metric regularization. Experimental findings on public benchmark exhibit a substantial enhancement in object detection specifically for foggy and rainy driving scenarios.
Read more8/22/2024