Data Augmentation for Supervised Graph Outlier Detection with Latent Diffusion Models

0

Sign in to get full access
Overview
- Data augmentation techniques can help improve the performance of supervised graph outlier detection models.
- This paper proposes using latent diffusion models for data augmentation to address class imbalance in graph outlier detection tasks.
- The approach aims to generate synthetic outlier samples to balance the training data and improve the model's ability to detect outliers.
Plain English Explanation
[object Object] is the task of identifying nodes or edges in a graph that are significantly different from the majority of the data. This is an important problem in many applications, such as fraud detection, network anomaly identification, and cybersecurity.
One challenge with graph outlier detection is that outlier samples are often rare, resulting in a class imbalance problem where the model has difficulty learning to identify the minority class of outliers. Data Augmentation is a technique that can help address this by generating synthetic samples to balance the training data.
In this paper, the authors propose using Latent Diffusion Models for data augmentation in supervised graph outlier detection. Diffusion models are a type of generative model that can learn to generate new samples by adding and then removing noise from the data. By learning a diffusion process in the latent space of the graph, the authors can generate synthetic outlier samples to improve the model's performance.
The key idea is to train a latent diffusion model on the graph data, condition it on the outlier label, and then use it to generate new outlier samples. These synthetic outliers can then be added to the training data to help the supervised outlier detection model learn more effectively.
Technical Explanation
The authors propose a [object Object], which consists of two main components:
-
Latent Diffusion Model: This is a generative model that learns a diffusion process in the latent space of the graph data. The model takes a graph as input, encodes it into a latent representation, and then applies a sequence of noise addition and removal steps to generate new samples.
-
Supervised Outlier Detection Model: This is a supervised model that takes a graph as input and predicts whether each node or edge is an outlier or not. The authors use the latent diffusion model to generate synthetic outlier samples, which are then added to the training data to improve the supervised model's performance.
The key technical contributions of the paper include:
-
Latent Diffusion Model Architecture: The authors design a specific architecture for the latent diffusion model that is tailored to graph data, including the use of graph neural networks and a novel conditioning mechanism to generate outlier samples.
-
Training Procedure: The authors propose a training procedure that alternates between training the latent diffusion model and the supervised outlier detection model, allowing the two components to benefit from each other.
-
Experiments: The authors evaluate their approach on several real-world graph datasets and show that it outperforms existing data augmentation techniques for graph outlier detection.
Critical Analysis
The paper presents a promising approach for addressing the class imbalance problem in supervised graph outlier detection. The use of latent diffusion models for data augmentation is a novel and interesting idea that could have broader applications beyond this specific task.
However, the paper does not explore the potential limitations or caveats of the proposed approach. For example, it is unclear how the method would perform on graphs with different characteristics, such as different scales, densities, or types of outliers. Additionally, the paper does not discuss the computational complexity or runtime of the approach, which could be an important consideration for real-world applications.
Further research could explore the robustness and generalizability of the latent diffusion model-based data augmentation approach, as well as investigate ways to make it more computationally efficient. Comparing the performance to other data augmentation techniques, such as graph-specific methods, could also provide valuable insights.
Conclusion
This paper presents a novel approach to address the class imbalance problem in supervised graph outlier detection by using latent diffusion models for data augmentation. The key idea is to train a latent diffusion model to generate synthetic outlier samples, which are then used to improve the performance of a supervised outlier detection model.
The results demonstrate the effectiveness of this approach, which could have important implications for a wide range of applications that rely on graph-based anomaly detection. While the paper provides a solid technical foundation, further research is needed to explore the limitations and potential avenues for improvement of the proposed method.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Data Augmentation for Supervised Graph Outlier Detection with Latent Diffusion Models
Kay Liu, Hengrui Zhang, Ziqing Hu, Fangxin Wang, Philip S. Yu
Graph outlier detection is a prominent task of research and application in the realm of graph neural networks. It identifies the outlier nodes that exhibit deviation from the majority in the graph. One of the fundamental challenges confronting supervised graph outlier detection algorithms is the prevalent issue of class imbalance, where the scarcity of outlier instances compared to normal instances often results in suboptimal performance. Conventional methods mitigate the imbalance by reweighting instances in the estimation of the loss function, assigning higher weights to outliers and lower weights to inliers. Nonetheless, these strategies are prone to overfitting and underfitting, respectively. Recently, generative models, especially diffusion models, have demonstrated their efficacy in synthesizing high-fidelity images. Despite their extraordinary generation quality, their potential in data augmentation for supervised graph outlier detection remains largely underexplored. To bridge this gap, we introduce GODM, a novel data augmentation for mitigating class imbalance in supervised Graph Outlier detection with latent Diffusion Models. Specifically, our proposed method consists of three key components: (1) Variantioanl Encoder maps the heterogeneous information inherent within the graph data into a unified latent space. (2) Graph Generator synthesizes graph data that are statistically similar to real outliers from latent space, and (3) Latent Diffusion Model learns the latent space distribution of real organic data by iterative denoising. Extensive experiments conducted on multiple datasets substantiate the effectiveness and efficiency of GODM. The case study further demonstrated the generation quality of our synthetic data. To foster accessibility and reproducibility, we encapsulate GODM into a plug-and-play package and release it at the Python Package Index (PyPI).
Read more9/14/2024

0
Hyperbolic Geometric Latent Diffusion Model for Graph Generation
Xingcheng Fu, Yisen Gao, Yuecen Wei, Qingyun Sun, Hao Peng, Jianxin Li, Xianxian Li
Diffusion models have made significant contributions to computer vision, sparking a growing interest in the community recently regarding the application of them to graph generation. Existing discrete graph diffusion models exhibit heightened computational complexity and diminished training efficiency. A preferable and natural way is to directly diffuse the graph within the latent space. However, due to the non-Euclidean structure of graphs is not isotropic in the latent space, the existing latent diffusion models effectively make it difficult to capture and preserve the topological information of graphs. To address the above challenges, we propose a novel geometrically latent diffusion framework HypDiff. Specifically, we first establish a geometrically latent space with interpretability measures based on hyperbolic geometry, to define anisotropic latent diffusion processes for graphs. Then, we propose a geometrically latent diffusion process that is constrained by both radial and angular geometric properties, thereby ensuring the preservation of the original topological properties in the generative graphs. Extensive experimental results demonstrate the superior effectiveness of HypDiff for graph generation with various topologies.
Read more5/7/2024

0
Leveraging Latent Diffusion Models for Training-Free In-Distribution Data Augmentation for Surface Defect Detection
Federico Girella, Ziyue Liu, Franco Fummi, Francesco Setti, Marco Cristani, Luigi Capogrosso
Defect detection is the task of identifying defects in production samples. Usually, defect detection classifiers are trained on ground-truth data formed by normal samples (negative data) and samples with defects (positive data), where the latter are consistently fewer than normal samples. State-of-the-art data augmentation procedures add synthetic defect data by superimposing artifacts to normal samples to mitigate problems related to unbalanced training data. These techniques often produce out-of-distribution images, resulting in systems that learn what is not a normal sample but cannot accurately identify what a defect looks like. In this work, we introduce DIAG, a training-free Diffusion-based In-distribution Anomaly Generation pipeline for data augmentation. Unlike conventional image generation techniques, we implement a human-in-the-loop pipeline, where domain experts provide multimodal guidance to the model through text descriptions and region localization of the possible anomalies. This strategic shift enhances the interpretability of results and fosters a more robust human feedback loop, facilitating iterative improvements of the generated outputs. Remarkably, our approach operates in a zero-shot manner, avoiding time-consuming fine-tuning procedures while achieving superior performance. We demonstrate the efficacy and versatility of DIAG with respect to state-of-the-art data augmentation approaches on the challenging KSDD2 dataset, with an improvement in AP of approximately 18% when positive samples are available and 28% when they are missing. The source code is available at https://github.com/intelligolabs/DIAG.
Read more7/12/2024
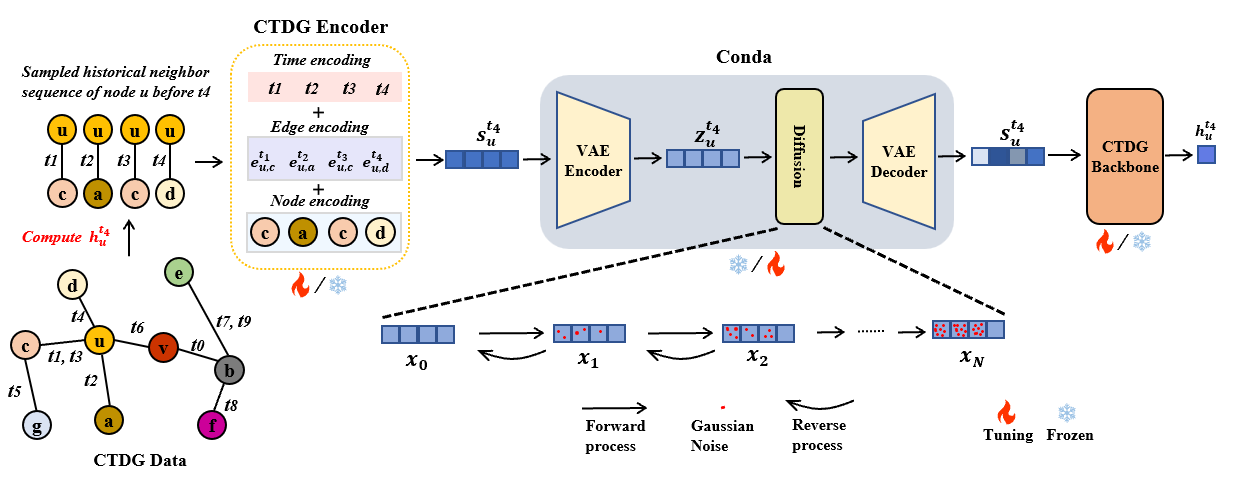
0
Latent Conditional Diffusion-based Data Augmentation for Continuous-Time Dynamic Graph Mode
Yuxing Tian, Yiyan Qi, Aiwen Jiang, Qi Huang, Jian Guo
Continuous-Time Dynamic Graph (CTDG) precisely models evolving real-world relationships, drawing heightened interest in dynamic graph learning across academia and industry. However, existing CTDG models encounter challenges stemming from noise and limited historical data. Graph Data Augmentation (GDA) emerges as a critical solution, yet current approaches primarily focus on static graphs and struggle to effectively address the dynamics inherent in CTDGs. Moreover, these methods often demand substantial domain expertise for parameter tuning and lack theoretical guarantees for augmentation efficacy. To address these issues, we propose Conda, a novel latent diffusion-based GDA method tailored for CTDGs. Conda features a sandwich-like architecture, incorporating a Variational Auto-Encoder (VAE) and a conditional diffusion model, aimed at generating enhanced historical neighbor embeddings for target nodes. Unlike conventional diffusion models trained on entire graphs via pre-training, Conda requires historical neighbor sequence embeddings of target nodes for training, thus facilitating more targeted augmentation. We integrate Conda into the CTDG model and adopt an alternating training strategy to optimize performance. Extensive experimentation across six widely used real-world datasets showcases the consistent performance improvement of our approach, particularly in scenarios with limited historical data.
Read more7/23/2024