Data-dependent and Oracle Bounds on Forgetting in Continual Learning
2406.09370
0
0

Abstract
In continual learning, knowledge must be preserved and re-used between tasks, maintaining good transfer to future tasks and minimizing forgetting of previously learned ones. While several practical algorithms have been devised for this setting, there have been few theoretical works aiming to quantify and bound the degree of Forgetting in general settings. We provide both data-dependent and oracle upper bounds that apply regardless of model and algorithm choice, as well as bounds for Gibbs posteriors. We derive an algorithm inspired by our bounds and demonstrate empirically that our approach yields improved forward and backward transfer.
Create account to get full access
Overview
- This paper investigates the problem of forgetting in continual learning, where an AI model is trained on a sequence of tasks and must learn to adapt without forgetting previous knowledge.
- The authors derive theoretical bounds on the forgetting that can occur in continual learning, providing insights into the fundamental limits of this challenge.
- They consider both data-dependent and oracle bounds, shedding light on how the data distribution and an "oracle" with perfect knowledge can impact forgetting.
Plain English Explanation
Continual learning is a crucial challenge in AI, where models need to adapt to new information without completely forgetting what they've learned before. Imagine a model trained to recognize different types of animals. As it learns to identify more animals over time, it's important that it doesn't forget how to recognize the animals it learned about initially.
This paper takes a deep dive into the problem of forgetting in continual learning. The authors develop mathematical bounds that describe the limits of how much a model can forget as it learns new tasks. These bounds come in two flavors: data-dependent bounds that depend on the specific data the model is trained on, and oracle bounds that represent the best possible scenario where the model has perfect knowledge.
By understanding these theoretical limits, the researchers hope to provide insights that can guide the development of continual learning algorithms and architectures to mitigate forgetting and enable more robust and adaptable AI systems.
Technical Explanation
The paper formulates the continual learning problem in terms of a sequence of regression tasks, where the model must learn to predict the outputs for each task without forgetting its performance on previous tasks. The authors derive two types of bounds on the model's forgetting:
-
Data-dependent bounds: These bounds depend on the specific data distribution the model is trained on, and provide a way to quantify how the model's forgetting is influenced by the task data.
-
Oracle bounds: These bounds represent the minimum possible forgetting that can be achieved by an "oracle" model with perfect knowledge of the task relationships and parameters. This provides a theoretical limit on the best-case forgetting performance.
The authors analyze the properties of these bounds, showing how they scale with the number of tasks, the task similarities, and other key problem parameters. They also discuss how these bounds can be used to guide the design of continual learning algorithms and architectures to mitigate forgetting.
Critical Analysis
The theoretical bounds derived in this paper provide valuable insights into the fundamental limits of continual learning, but they also have some important caveats and limitations:
- The bounds are based on specific assumptions about the task structure and data distributions, which may not always hold in real-world continual learning scenarios.
- The analysis focuses on regression tasks, and it's unclear how the results would generalize to other problem settings like classification or reinforcement learning.
- The paper does not address practical challenges in implementing continual learning systems, such as the computational and memory overhead required to maintain performance on past tasks.
Additionally, while the oracle bounds provide a useful theoretical limit, it's not clear how to actually construct an oracle model in practice. More research is needed to understand how to design continual learning algorithms that can approach these optimal performance levels.
Conclusion
This paper makes an important theoretical contribution to the field of continual learning by deriving bounds on the forgetting that can occur as a model adapts to new tasks. The data-dependent and oracle bounds provide a framework for understanding the fundamental limits of this challenge and can help guide the development of more robust and adaptable AI systems. However, further research is needed to address the practical challenges of implementing continual learning in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Controlling Forgetting with Test-Time Data in Continual Learning
Vaibhav Singh, Rahaf Aljundi, Eugene Belilovsky
0
0
Foundational vision-language models have shown impressive performance on various downstream tasks. Yet, there is still a pressing need to update these models later as new tasks or domains become available. Ongoing Continual Learning (CL) research provides techniques to overcome catastrophic forgetting of previous information when new knowledge is acquired. To date, CL techniques focus only on the supervised training sessions. This results in significant forgetting yielding inferior performance to even the prior model zero shot performance. In this work, we argue that test-time data hold great information that can be leveraged in a self supervised manner to refresh the model's memory of previous learned tasks and hence greatly reduce forgetting at no extra labelling cost. We study how unsupervised data can be employed online to improve models' performance on prior tasks upon encountering representative samples. We propose a simple yet effective student-teacher model with gradient based sparse parameters updates and show significant performance improvements and reduction in forgetting, which could alleviate the role of an offline episodic memory/experience replay buffer.
6/21/2024

Understanding Forgetting in Continual Learning with Linear Regression
Meng Ding, Kaiyi Ji, Di Wang, Jinhui Xu
0
0
Continual learning, focused on sequentially learning multiple tasks, has gained significant attention recently. Despite the tremendous progress made in the past, the theoretical understanding, especially factors contributing to catastrophic forgetting, remains relatively unexplored. In this paper, we provide a general theoretical analysis of forgetting in the linear regression model via Stochastic Gradient Descent (SGD) applicable to both underparameterized and overparameterized regimes. Our theoretical framework reveals some interesting insights into the intricate relationship between task sequence and algorithmic parameters, an aspect not fully captured in previous studies due to their restrictive assumptions. Specifically, we demonstrate that, given a sufficiently large data size, the arrangement of tasks in a sequence, where tasks with larger eigenvalues in their population data covariance matrices are trained later, tends to result in increased forgetting. Additionally, our findings highlight that an appropriate choice of step size will help mitigate forgetting in both underparameterized and overparameterized settings. To validate our theoretical analysis, we conducted simulation experiments on both linear regression models and Deep Neural Networks (DNNs). Results from these simulations substantiate our theoretical findings.
5/29/2024

The Empirical Impact of Forgetting and Transfer in Continual Visual Odometry
Paolo Cudrano, Xiaoyu Luo, Matteo Matteucci
0
0
As robotics continues to advance, the need for adaptive and continuously-learning embodied agents increases, particularly in the realm of assistance robotics. Quick adaptability and long-term information retention are essential to operate in dynamic environments typical of humans' everyday lives. A lifelong learning paradigm is thus required, but it is scarcely addressed by current robotics literature. This study empirically investigates the impact of catastrophic forgetting and the effectiveness of knowledge transfer in neural networks trained continuously in an embodied setting. We focus on the task of visual odometry, which holds primary importance for embodied agents in enabling their self-localization. We experiment on the simple continual scenario of discrete transitions between indoor locations, akin to a robot navigating different apartments. In this regime, we observe initial satisfactory performance with high transferability between environments, followed by a specialization phase where the model prioritizes current environment-specific knowledge at the expense of generalization. Conventional regularization strategies and increased model capacity prove ineffective in mitigating this phenomenon. Rehearsal is instead mildly beneficial but with the addition of a substantial memory cost. Incorporating action information, as commonly done in embodied settings, facilitates quicker convergence but exacerbates specialization, making the model overly reliant on its motion expectations and less adept at correctly interpreting visual cues. These findings emphasize the open challenges of balancing adaptation and memory retention in lifelong robotics and contribute valuable insights into the application of a lifelong paradigm on embodied agents.
6/5/2024
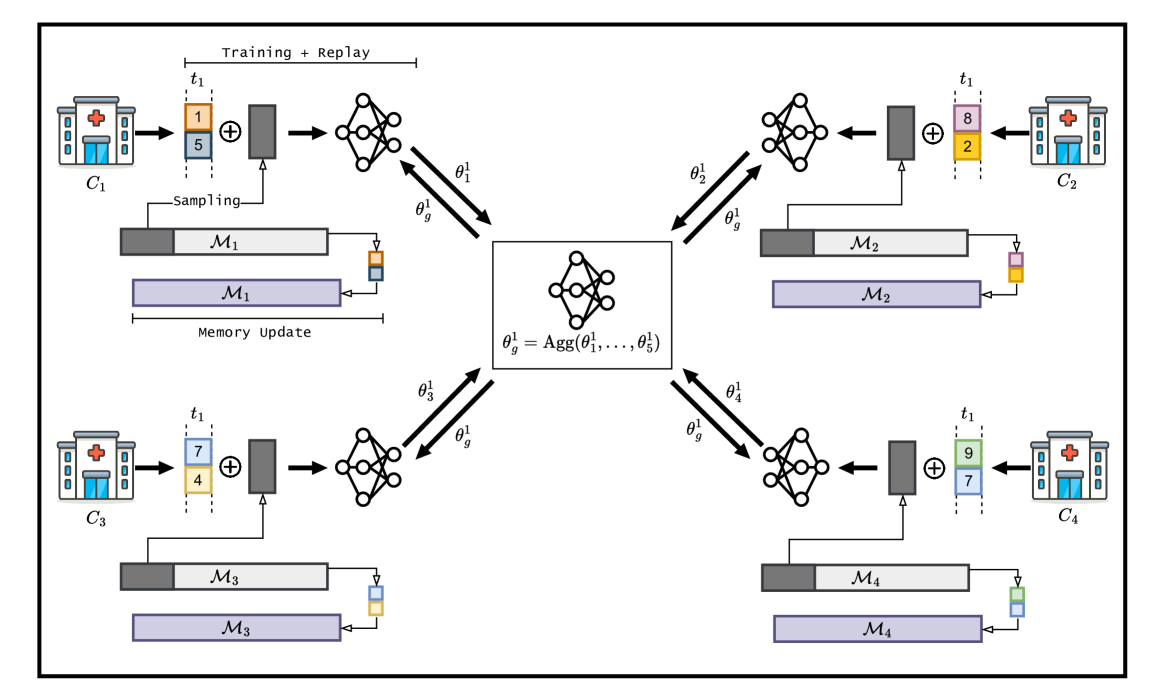
Federated Continual Learning Goes Online: Leveraging Uncertainty for Modality-Agnostic Class-Incremental Learning
Giuseppe Serra, Florian Buettner
0
0
Given the ability to model more realistic and dynamic problems, Federated Continual Learning (FCL) has been increasingly investigated recently. A well-known problem encountered in this setting is the so-called catastrophic forgetting, for which the learning model is inclined to focus on more recent tasks while forgetting the previously learned knowledge. The majority of the current approaches in FCL propose generative-based solutions to solve said problem. However, this setting requires multiple training epochs over the data, implying an offline setting where datasets are stored locally and remain unchanged over time. Furthermore, the proposed solutions are tailored for vision tasks solely. To overcome these limitations, we propose a new modality-agnostic approach to deal with the online scenario where new data arrive in streams of mini-batches that can only be processed once. To solve catastrophic forgetting, we propose an uncertainty-aware memory-based approach. In particular, we suggest using an estimator based on the Bregman Information (BI) to compute the model's variance at the sample level. Through measures of predictive uncertainty, we retrieve samples with specific characteristics, and - by retraining the model on such samples - we demonstrate the potential of this approach to reduce the forgetting effect in realistic settings.
5/30/2024