Data-independent Module-aware Pruning for Hierarchical Vision Transformers
2404.13648
0
0
Abstract
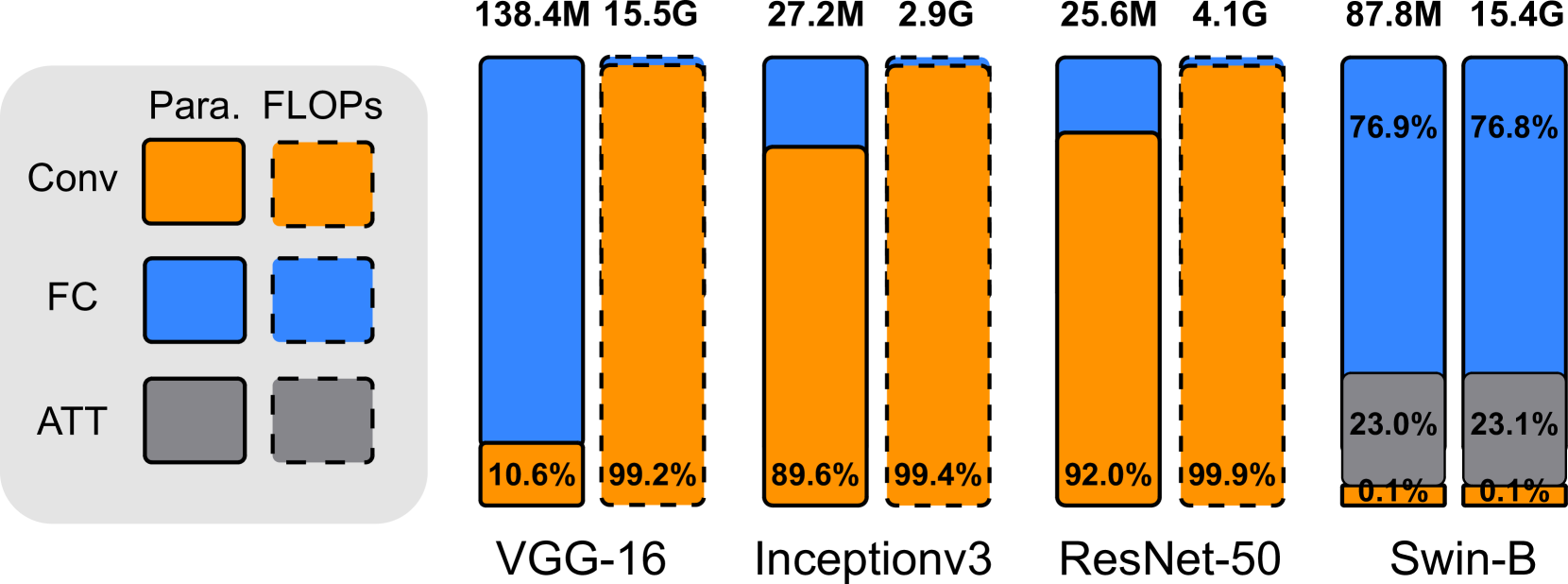
Hierarchical vision transformers (ViTs) have two advantages over conventional ViTs. First, hierarchical ViTs achieve linear computational complexity with respect to image size by local self-attention. Second, hierarchical ViTs create hierarchical feature maps by merging image patches in deeper layers for dense prediction. However, existing pruning methods ignore the unique properties of hierarchical ViTs and use the magnitude value as the weight importance. This approach leads to two main drawbacks. First, the local attention weights are compared at a global level, which may cause some locally important weights to be pruned due to their relatively small magnitude globally. The second issue with magnitude pruning is that it fails to consider the distinct weight distributions of the network, which are essential for extracting coarse to fine-grained features at various hierarchical levels. To solve the aforementioned issues, we have developed a Data-independent Module-Aware Pruning method (DIMAP) to compress hierarchical ViTs. To ensure that local attention weights at different hierarchical levels are compared fairly in terms of their contribution, we treat them as a module and examine their contribution by analyzing their information distortion. Furthermore, we introduce a novel weight metric that is solely based on weights and does not require input images, thereby eliminating the dependence on the patch merging process. Our method validates its usefulness and strengths on Swin Transformers of different sizes on ImageNet-1k classification. Notably, the top-5 accuracy drop is only 0.07% when we remove 52.5% FLOPs and 52.7% parameters of Swin-B. When we reduce 33.2% FLOPs and 33.2% parameters of Swin-S, we can even achieve a 0.8% higher relative top-5 accuracy than the original model. Code is available at: https://github.com/he-y/Data-independent-Module-Aware-Pruning
Create account to get full access
Overview
- Presents a novel pruning method for hierarchical vision transformers (HVTs) called Data-independent Module-aware Pruning (DIMP)
- DIMP prunes HVTs without relying on training data, improving inference efficiency while maintaining accuracy
- Leverages the modular structure of HVTs to identify and prune less critical modules
Plain English Explanation
This paper introduces a new way to make vision transformer models more efficient, without losing their accuracy. Vision transformers are a type of AI model that has been very successful in tasks like image recognition. However, these models can be large and slow, which can make them difficult to use in real-world applications.
The researchers developed a technique called Data-independent Module-aware Pruning (DIMP) that can prune, or remove, parts of the vision transformer model without needing to use the training data. This is important because it means the pruning can be done quickly and efficiently, without the need for expensive data processing.
The key insight behind DIMP is that vision transformer models have a modular structure, with different components responsible for different parts of the task. DIMP analyzes these modules and identifies the ones that are less critical to the model's performance. It then removes or "prunes" these less important modules, resulting in a smaller and faster model that still maintains high accuracy.
By not relying on the training data, DIMP is able to prune the model much more quickly and efficiently than previous methods. This makes it a very practical solution for deploying vision transformers in real-world applications where speed and efficiency are important.
Technical Explanation
The paper presents a novel pruning method for Hierarchical Vision Transformers (HVTs) called Data-independent Module-aware Pruning (DIMP). DIMP is designed to improve the inference efficiency of HVTs without significantly compromising their accuracy.
Unlike previous pruning approaches that rely on training data, DIMP is a data-independent pruning method. This means it can prune the model without the need for expensive data processing or finetuning.
The key insight behind DIMP is that HVTs have a modular structure, with different components responsible for different aspects of the task. DIMP leverages this modular design to identify and prune less critical modules, reducing the model's overall complexity while maintaining its performance.
The paper conducts extensive experiments on various HVT architectures, including FasterViT and ViT. The results demonstrate that DIMP can achieve significant model compression and speedup without compromising accuracy, outperforming state-of-the-art pruning methods.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the DIMP method, with experiments on multiple HVT architectures and comparisons to state-of-the-art pruning techniques. The data-independent nature of DIMP is a significant advantage, as it avoids the need for costly data processing and finetuning required by previous approaches.
One potential limitation of the DIMP method is that it relies on the modular structure of HVTs, which may not be present in all types of transformer models. Additionally, the paper does not explore the impact of DIMP on the model's inference latency, which can be an important consideration for real-world applications.
Further research could investigate the applicability of DIMP to other transformer-based models, as well as the trade-offs between model compression, inference speed, and accuracy. Exploring the robustness of DIMP to different types of input data or tasks could also provide valuable insights.
Conclusion
The Data-independent Module-aware Pruning (DIMP) method presented in this paper is a significant advancement in the field of model compression for vision transformers. By leveraging the modular structure of HVTs, DIMP is able to achieve impressive model compression and speedup without compromising accuracy, making it a highly practical solution for deploying these powerful models in real-world applications.
The data-independent nature of DIMP is a key strength, as it avoids the need for expensive data processing and finetuning required by previous pruning approaches. This makes DIMP a versatile and efficient tool for optimizing the performance of HVTs and other transformer-based models, with potential applications in a wide range of computer vision tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Automatic Channel Pruning for Multi-Head Attention
Eunho Lee, Youngbae Hwang
0
0
Despite the strong performance of Transformers, their quadratic computation complexity presents challenges in applying them to vision tasks. Automatic pruning is one of effective methods for reducing computation complexity without heuristic approaches. However, directly applying it to multi-head attention is not straightforward due to channel misalignment. In this paper, we propose an automatic channel pruning method to take into account the multi-head attention mechanism. First, we incorporate channel similarity-based weights into the pruning indicator to preserve more informative channels in each head. Then, we adjust pruning indicator to enforce removal of channels in equal proportions across all heads, preventing the channel misalignment. We also add a reweight module to compensate for information loss resulting from channel removal, and an effective initialization step for pruning indicator based on difference of attention between original structure and each channel. Our proposed method can be used to not only original attention, but also linear attention, which is more efficient as linear complexity with respect to the number of tokens. On ImageNet-1K, applying our pruning method to the FLattenTransformer, which includes both attention mechanisms, shows outperformed accuracy for several MACs compared with previous state-of-the-art efficient models and pruned methods. Code will be available soon.
6/3/2024
🗣️
VTrans: Accelerating Transformer Compression with Variational Information Bottleneck based Pruning
Oshin Dutta, Ritvik Gupta, Sumeet Agarwal
0
0
In recent years, there has been a growing emphasis on compressing large pre-trained transformer models for resource-constrained devices. However, traditional pruning methods often leave the embedding layer untouched, leading to model over-parameterization. Additionally, they require extensive compression time with large datasets to maintain performance in pruned models. To address these challenges, we propose VTrans, an iterative pruning framework guided by the Variational Information Bottleneck (VIB) principle. Our method compresses all structural components, including embeddings, attention heads, and layers using VIB-trained masks. This approach retains only essential weights in each layer, ensuring compliance with specified model size or computational constraints. Notably, our method achieves upto 70% more compression than prior state-of-the-art approaches, both task-agnostic and task-specific. We further propose faster variants of our method: Fast-VTrans utilizing only 3% of the data and Faster-VTrans, a time efficient alternative that involves exclusive finetuning of VIB masks, accelerating compression by upto 25 times with minimal performance loss compared to previous methods. Extensive experiments on BERT, ROBERTa, and GPT-2 models substantiate the efficacy of our method. Moreover, our method demonstrates scalability in compressing large models such as LLaMA-2-7B, achieving superior performance compared to previous pruning methods. Additionally, we use attention-based probing to qualitatively assess model redundancy and interpret the efficiency of our approach. Notably, our method considers heads with high attention to special and current tokens in un-pruned model as foremost candidates for pruning while retained heads are observed to attend more to task-critical keywords.
6/13/2024
SNP: Structured Neuron-level Pruning to Preserve Attention Scores
Kyunghwan Shim, Jaewoong Yun, Shinkook Choi
0
0
Multi-head self-attention (MSA) is a key component of Vision Transformers (ViTs), which have achieved great success in various vision tasks. However, their high computational cost and memory footprint hinder their deployment on resource-constrained devices. Conventional pruning approaches can only compress and accelerate the MSA module using head pruning, although the head is not an atomic unit. To address this issue, we propose a novel graph-aware neuron-level pruning method, Structured Neuron-level Pruning (SNP). SNP prunes neurons with less informative attention scores and eliminates redundancy among heads. Specifically, it prunes graphically connected query and key layers having the least informative attention scores while preserving the overall attention scores. Value layers, which can be pruned independently, are pruned to eliminate inter-head redundancy. Our proposed method effectively compresses and accelerates Transformer-based models for both edge devices and server processors. For instance, the DeiT-Small with SNP runs 3.1$times$ faster than the original model and achieves performance that is 21.94% faster and 1.12% higher than the DeiT-Tiny. Additionally, SNP combine successfully with conventional head or block pruning approaches. SNP with head pruning could compress the DeiT-Base by 80% of the parameters and computational costs and achieve 3.85$times$ faster inference speed on RTX3090 and 4.93$times$ on Jetson Nano.
4/19/2024

Accelerating ViT Inference on FPGA through Static and Dynamic Pruning
Dhruv Parikh, Shouyi Li, Bingyi Zhang, Rajgopal Kannan, Carl Busart, Viktor Prasanna
0
0
Vision Transformers (ViTs) have achieved state-of-the-art accuracy on various computer vision tasks. However, their high computational complexity prevents them from being applied to many real-world applications. Weight and token pruning are two well-known methods for reducing complexity: weight pruning reduces the model size and associated computational demands, while token pruning further dynamically reduces the computation based on the input. Combining these two techniques should significantly reduce computation complexity and model size; however, naively integrating them results in irregular computation patterns, leading to significant accuracy drops and difficulties in hardware acceleration. Addressing the above challenges, we propose a comprehensive algorithm-hardware codesign for accelerating ViT on FPGA through simultaneous pruning -combining static weight pruning and dynamic token pruning. For algorithm design, we systematically combine a hardware-aware structured block-pruning method for pruning model parameters and a dynamic token pruning method for removing unimportant token vectors. Moreover, we design a novel training algorithm to recover the model's accuracy. For hardware design, we develop a novel hardware accelerator for executing the pruned model. The proposed hardware design employs multi-level parallelism with load balancing strategy to efficiently deal with the irregular computation pattern led by the two pruning approaches. Moreover, we develop an efficient hardware mechanism for efficiently executing the on-the-fly token pruning.
4/15/2024