FasterViT: Fast Vision Transformers with Hierarchical Attention
2306.06189
0
0
👀
Abstract
We design a new family of hybrid CNN-ViT neural networks, named FasterViT, with a focus on high image throughput for computer vision (CV) applications. FasterViT combines the benefits of fast local representation learning in CNNs and global modeling properties in ViT. Our newly introduced Hierarchical Attention (HAT) approach decomposes global self-attention with quadratic complexity into a multi-level attention with reduced computational costs. We benefit from efficient window-based self-attention. Each window has access to dedicated carrier tokens that participate in local and global representation learning. At a high level, global self-attentions enable the efficient cross-window communication at lower costs. FasterViT achieves a SOTA Pareto-front in terms of accuracy and image throughput. We have extensively validated its effectiveness on various CV tasks including classification, object detection and segmentation. We also show that HAT can be used as a plug-and-play module for existing networks and enhance them. We further demonstrate significantly faster and more accurate performance than competitive counterparts for images with high resolution. Code is available at https://github.com/NVlabs/FasterViT.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Researchers have developed a new family of hybrid neural networks called FasterViT that combines the strengths of convolutional neural networks (CNNs) and vision transformers (ViTs).
- FasterViT aims to achieve high image throughput for computer vision applications.
- The key innovation is a Hierarchical Attention (HAT) approach that decomposes global self-attention into a more efficient multi-level attention mechanism.
- FasterViT achieves state-of-the-art performance in terms of accuracy and image throughput across various computer vision tasks.
Plain English Explanation
The researchers have created a new type of neural network that brings together the best features of two popular approaches - convolutional neural networks (CNNs) and vision transformers (ViTs). CNNs are known for their ability to quickly learn local visual patterns, while ViTs excel at modeling global relationships in images.
The new FasterViT model combines these strengths by using a novel "Hierarchical Attention" mechanism. This approach breaks down the computationally expensive global self-attention used in ViTs into a more efficient multi-level attention process. FasterViT can therefore capture both local and global information in the images, but at a much lower computational cost.
As a result, FasterViT is able to process images very quickly while still maintaining high accuracy. The researchers show that FasterViT outperforms other state-of-the-art models on a variety of computer vision benchmarks, including image classification, object detection, and image segmentation.
The key innovation here is the Hierarchical Attention mechanism, which allows FasterViT to get the best of both CNNs and ViTs. By decomposing the global attention into a more efficient multi-scale approach, the model can run quickly while still understanding the broader context of the image. This makes FasterViT well-suited for real-world computer vision applications that require high throughput.
Technical Explanation
The core of the FasterViT architecture is the Hierarchical Attention (HAT) module, which decomposes the global self-attention used in typical ViT models into a more efficient multi-level attention mechanism.
In HAT, the input image is first split into smaller "windows", each of which has dedicated "carrier tokens" that participate in both local and global representation learning. The local attention within each window is computed efficiently using a window-based self-attention approach.
To enable cross-window communication, HAT also computes global attention, but does so in a hierarchical manner - first attending to broader regions, then progressively refining the attention at smaller scales. This hierarchical attention has significantly lower computational complexity compared to a single global self-attention layer.
By combining the local window-based attention and the global hierarchical attention, HAT allows FasterViT to capture both fine-grained and high-level visual features, leading to strong performance on a range of computer vision tasks. The researchers validate FasterViT's effectiveness through extensive experiments on image classification, object detection, and semantic segmentation, demonstrating state-of-the-art accuracy and inference speed.
Critical Analysis
The paper provides a thorough evaluation of the FasterViT architecture, highlighting its advantages over existing CNN and ViT models. However, a few potential limitations and areas for further research are worth noting:
The authors do not provide an in-depth analysis of the memory and storage requirements of FasterViT compared to other models. As the Hierarchical Attention mechanism adds additional complexity, it would be helpful to understand the trade-offs in terms of model size and memory footprint.
Additionally, while the paper demonstrates the effectiveness of FasterViT on standard benchmark datasets, it would be valuable to see how the model performs on more diverse and challenging real-world computer vision tasks. Further evaluation in such scenarios could uncover additional strengths or weaknesses of the approach.
Finally, the authors mention that the HAT module can be used as a plug-and-play component to enhance existing networks. However, the paper does not provide a detailed analysis of how much improvement can be expected when integrating HAT into different model architectures. Exploring this aspect further could help researchers and practitioners better understand the broader applicability of the proposed techniques.
Conclusion
The FasterViT model developed by the researchers represents an exciting advancement in the field of computer vision. By combining the localized feature learning of CNNs with the global modeling capabilities of ViTs, FasterViT achieves an impressive balance of accuracy and inference speed.
The key innovation of the Hierarchical Attention mechanism is a clever way to make the computationally expensive self-attention in ViTs much more efficient, without sacrificing its expressive power. This allows FasterViT to excel on a variety of computer vision tasks, making it a promising candidate for real-world applications that demand both high performance and high throughput.
While the paper presents a thorough evaluation of FasterViT, further exploration of its memory and storage requirements, as well as its performance on diverse real-world scenarios, could provide additional insights. Overall, this research represents a significant step forward in developing powerful and practical computer vision models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
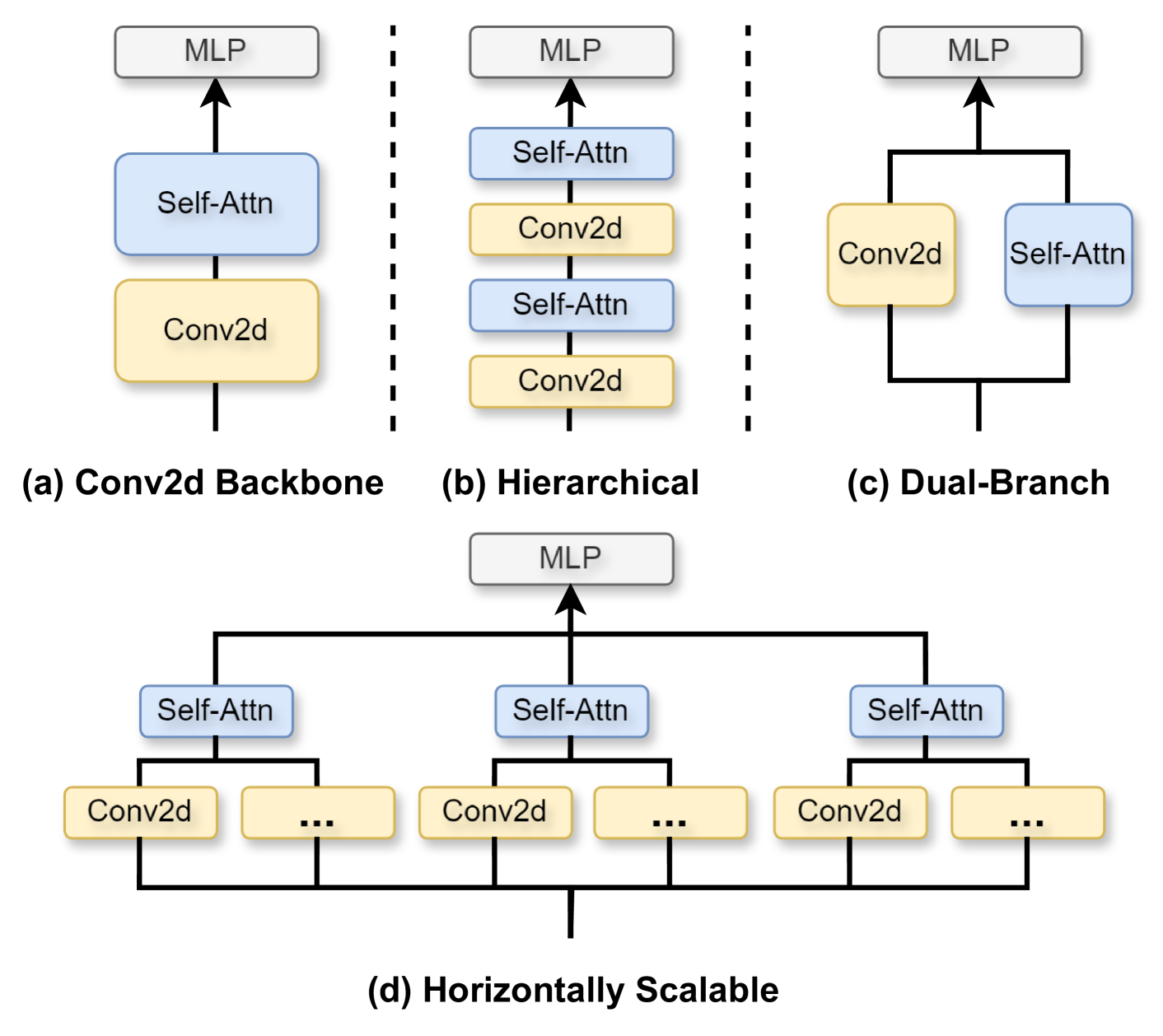
HSViT: Horizontally Scalable Vision Transformer
Chenhao Xu, Chang-Tsun Li, Chee Peng Lim, Douglas Creighton
0
0
While the Vision Transformer (ViT) architecture gains prominence in computer vision and attracts significant attention from multimedia communities, its deficiency in prior knowledge (inductive bias) regarding shift, scale, and rotational invariance necessitates pre-training on large-scale datasets. Furthermore, the growing layers and parameters in both ViT and convolutional neural networks (CNNs) impede their applicability to mobile multimedia services, primarily owing to the constrained computational resources on edge devices. To mitigate the aforementioned challenges, this paper introduces a novel horizontally scalable vision transformer (HSViT). Specifically, a novel image-level feature embedding allows ViT to better leverage the inductive bias inherent in the convolutional layers. Based on this, an innovative horizontally scalable architecture is designed, which reduces the number of layers and parameters of the models while facilitating collaborative training and inference of ViT models across multiple nodes. The experimental results depict that, without pre-training on large-scale datasets, HSViT achieves up to 10% higher top-1 accuracy than state-of-the-art schemes, ascertaining its superior preservation of inductive bias. The code is available at https://github.com/xuchenhao001/HSViT.
4/9/2024

Nested-TNT: Hierarchical Vision Transformers with Multi-Scale Feature Processing
Yuang Liu, Zhiheng Qiu, Xiaokai Qin
0
0
Transformer has been applied in the field of computer vision due to its excellent performance in natural language processing, surpassing traditional convolutional neural networks and achieving new state-of-the-art. ViT divides an image into several local patches, known as visual sentences. However, the information contained in the image is vast and complex, and focusing only on the features at the visual sentence level is not enough. The features between local patches should also be taken into consideration. In order to achieve further improvement, the TNT model is proposed, whose algorithm further divides the image into smaller patches, namely visual words, achieving more accurate results. The core of Transformer is the Multi-Head Attention mechanism, and traditional attention mechanisms ignore interactions across different attention heads. In order to reduce redundancy and improve utilization, we introduce the nested algorithm and apply the Nested-TNT to image classification tasks. The experiment confirms that the proposed model has achieved better classification performance over ViT and TNT, exceeding 2.25%, 1.1% on dataset CIFAR10 and 2.78%, 0.25% on dataset FLOWERS102 respectively.
4/23/2024
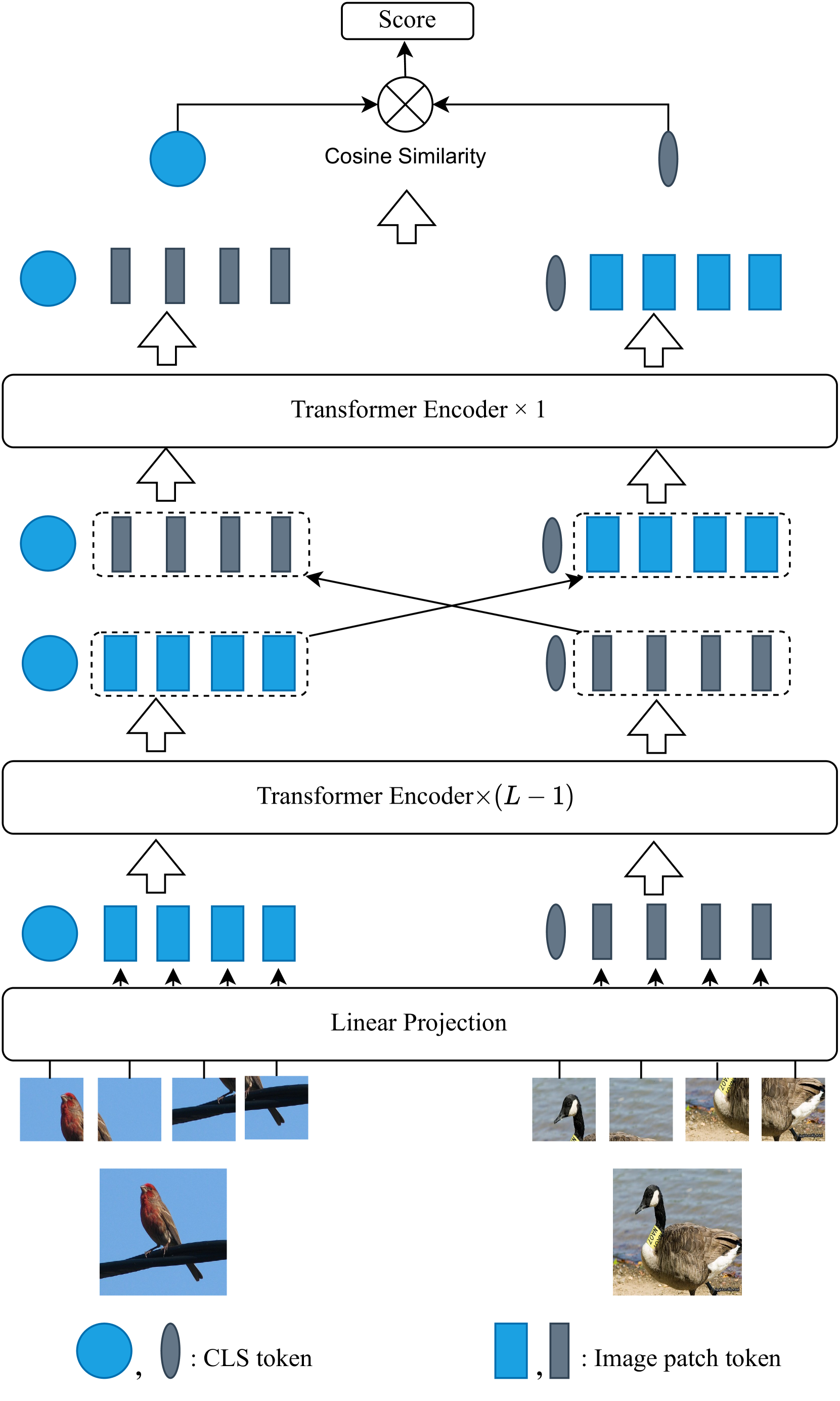
Intra-task Mutual Attention based Vision Transformer for Few-Shot Learning
Weihao Jiang, Chang Liu, Kun He
0
0
Humans possess remarkable ability to accurately classify new, unseen images after being exposed to only a few examples. Such ability stems from their capacity to identify common features shared between new and previously seen images while disregarding distractions such as background variations. However, for artificial neural network models, determining the most relevant features for distinguishing between two images with limited samples presents a challenge. In this paper, we propose an intra-task mutual attention method for few-shot learning, that involves splitting the support and query samples into patches and encoding them using the pre-trained Vision Transformer (ViT) architecture. Specifically, we swap the class (CLS) token and patch tokens between the support and query sets to have the mutual attention, which enables each set to focus on the most useful information. This facilitates the strengthening of intra-class representations and promotes closer proximity between instances of the same class. For implementation, we adopt the ViT-based network architecture and utilize pre-trained model parameters obtained through self-supervision. By leveraging Masked Image Modeling as a self-supervised training task for pre-training, the pre-trained model yields semantically meaningful representations while successfully avoiding supervision collapse. We then employ a meta-learning method to fine-tune the last several layers and CLS token modules. Our strategy significantly reduces the num- ber of parameters that require fine-tuning while effectively uti- lizing the capability of pre-trained model. Extensive experiments show that our framework is simple, effective and computationally efficient, achieving superior performance as compared to the state-of-the-art baselines on five popular few-shot classification benchmarks under the 5-shot and 1-shot scenarios
5/7/2024
👀
Enhancing Efficiency in Vision Transformer Networks: Design Techniques and Insights
Moein Heidari, Reza Azad, Sina Ghorbani Kolahi, Ren'e Arimond, Leon Niggemeier, Alaa Sulaiman, Afshin Bozorgpour, Ehsan Khodapanah Aghdam, Amirhossein Kazerouni, Ilker Hacihaliloglu, Dorit Merhof
0
0
Intrigued by the inherent ability of the human visual system to identify salient regions in complex scenes, attention mechanisms have been seamlessly integrated into various Computer Vision (CV) tasks. Building upon this paradigm, Vision Transformer (ViT) networks exploit attention mechanisms for improved efficiency. This review navigates the landscape of redesigned attention mechanisms within ViTs, aiming to enhance their performance. This paper provides a comprehensive exploration of techniques and insights for designing attention mechanisms, systematically reviewing recent literature in the field of CV. This survey begins with an introduction to the theoretical foundations and fundamental concepts underlying attention mechanisms. We then present a systematic taxonomy of various attention mechanisms within ViTs, employing redesigned approaches. A multi-perspective categorization is proposed based on their application, objectives, and the type of attention applied. The analysis includes an exploration of the novelty, strengths, weaknesses, and an in-depth evaluation of the different proposed strategies. This culminates in the development of taxonomies that highlight key properties and contributions. Finally, we gather the reviewed studies along with their available open-source implementations at our href{https://github.com/mindflow-institue/Awesome-Attention-Mechanism-in-Medical-Imaging}{GitHub}footnote{url{https://github.com/xmindflow/Awesome-Attention-Mechanism-in-Medical-Imaging}}. We aim to regularly update it with the most recent relevant papers.
4/1/2024