A Data-to-Product Multimodal Conceptual Framework to Achieve Automated Software Evolution for Context-rich Intelligent Applications
2404.04821
0
0
Abstract
While AI is extensively transforming Software Engineering (SE) fields, SE is still in need of a framework to overall consider all phases to facilitate Automated Software Evolution (ASEv), particularly for intelligent applications that are context-rich, instead of conquering each division independently. Its complexity comes from the intricacy of the intelligent applications, the heterogeneity of the data sources, and the constant changes in the context. This study proposes a conceptual framework for achieving automated software evolution, emphasizing the importance of multimodality learning. A Selective Sequential Scope Model (3S) model is developed based on the conceptual framework, and it can be used to categorize existing and future research when it covers different SE phases and multimodal learning tasks. This research is a preliminary step toward the blueprint of a higher-level ASEv. The proposed conceptual framework can act as a practical guideline for practitioners to prepare themselves for diving into this area. Although the study is about intelligent applications, the framework and analysis methods may be adapted for other types of software as AI brings more intelligence into their life cycles.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Presents a conceptual framework to enable automated software evolution for context-rich intelligent applications
- Integrates multiple data sources and modalities to generate product updates and adaptation
- Aims to address challenges in keeping software up-to-date with evolving user needs and environmental contexts
Plain English Explanation
This paper introduces a conceptual framework to help software systems automatically evolve and adapt over time. The key idea is to leverage a variety of data sources - such as user feedback, sensor data, and other contextual information - to continuously update and improve the software.
Rather than relying on manual maintenance by developers, the framework aims to enable software to autonomously detect changes in user needs or environmental conditions, and then modify itself accordingly. This could be useful for context-rich intelligent applications that need to stay closely aligned with dynamic user preferences and operating contexts.
The proposed approach integrates data from multiple modalities - such as text, images, and sensor readings - to build a comprehensive understanding of the software's operating environment. This multimodal information fusion is then used to drive automated software updates and adaptations.
Technical Explanation
The core of the framework is a data-to-product pipeline that ingests diverse data sources, extracts relevant features, and generates product updates to the software system. Key components include:
- Data Acquisition: Gathering user feedback, sensor data, and other contextual information from multiple channels
- Multimodal Feature Extraction: Analyzing the collected data to identify salient patterns and insights across different modalities
- Update Generation: Leveraging the extracted features to automatically generate software updates that address evolving user needs and environmental changes
- Deployment and Monitoring: Deploying the updated software and continuously monitoring its performance to inform future iterations
The authors demonstrate the feasibility of this approach through a series of case studies involving context-rich applications like smart home systems and intelligent virtual assistants. Their results indicate that the framework can effectively drive automated software evolution while maintaining high user satisfaction.
Critical Analysis
The proposed framework represents a promising step towards enabling more dynamic and responsive software systems. By tightly coupling software updates with rich, multimodal data about user needs and environmental contexts, it has the potential to improve the long-term relevance and usefulness of intelligent applications.
However, the authors acknowledge several challenges and limitations that warrant further investigation. For example, the framework relies on the availability and quality of the input data, which may not always be reliable or comprehensive. There are also open questions around the scalability and generalizability of the approach, as well as the potential privacy and security implications of continuously monitoring user data.
Additionally, the paper does not delve into the technical details of the machine learning models and algorithms used for feature extraction and update generation. More information on the specific methods and their performance characteristics would be helpful for assessing the viability of the framework.
Conclusion
This paper presents a conceptual framework that aims to address the challenge of keeping software systems up-to-date with evolving user needs and environmental conditions. By leveraging multimodal data sources and automated update generation, the framework has the potential to enable more context-aware and responsive intelligent applications.
While the proposed approach shows promise, further research is needed to address the identified challenges and limitations. Ongoing work in areas like robust data fusion, adaptive machine learning, and trustworthy autonomous systems may help to strengthen and refine the conceptual framework over time.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
Foundations of Multisensory Artificial Intelligence
Paul Pu Liang
0
0
Building multisensory AI systems that learn from multiple sensory inputs such as text, speech, video, real-world sensors, wearable devices, and medical data holds great promise for impact in many scientific areas with practical benefits, such as in supporting human health and well-being, enabling multimedia content processing, and enhancing real-world autonomous agents. By synthesizing a range of theoretical frameworks and application domains, this thesis aims to advance the machine learning foundations of multisensory AI. In the first part, we present a theoretical framework formalizing how modalities interact with each other to give rise to new information for a task. These interactions are the basic building blocks in all multimodal problems, and their quantification enables users to understand their multimodal datasets, design principled approaches to learn these interactions, and analyze whether their model has succeeded in learning. In the second part, we study the design of practical multimodal foundation models that generalize over many modalities and tasks, which presents a step toward grounding large language models to real-world sensory modalities. We introduce MultiBench, a unified large-scale benchmark across a wide range of modalities, tasks, and research areas, followed by the cross-modal attention and multimodal transformer architectures that now underpin many of today's multimodal foundation models. Scaling these architectures on MultiBench enables the creation of general-purpose multisensory AI systems, and we discuss our collaborative efforts in applying these models for real-world impact in affective computing, mental health, cancer prognosis, and robotics. Finally, we conclude this thesis by discussing how future work can leverage these ideas toward more general, interactive, and safe multisensory AI.
5/1/2024
A Framework to Model ML Engineering Processes
Sergio Morales, Robert Claris'o, Jordi Cabot
0
0
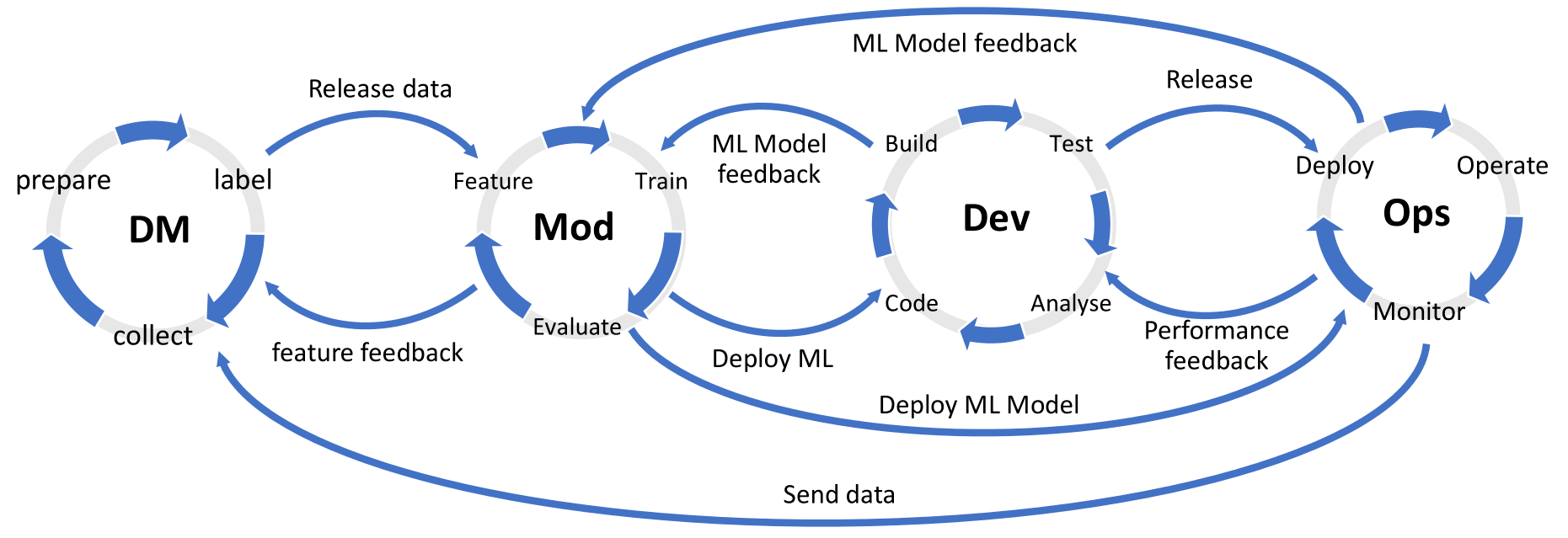
The development of Machine Learning (ML) based systems is complex and requires multidisciplinary teams with diverse skill sets. This may lead to communication issues or misapplication of best practices. Process models can alleviate these challenges by standardizing task orchestration, providing a common language to facilitate communication, and nurturing a collaborative environment. Unfortunately, current process modeling languages are not suitable for describing the development of such systems. In this paper, we introduce a framework for modeling ML-based software development processes, built around a domain-specific language and derived from an analysis of scientific and gray literature. A supporting toolkit is also available.
4/30/2024
📈
Rethinking Software Engineering in the Foundation Model Era: From Task-Driven AI Copilots to Goal-Driven AI Pair Programmers
Ahmed E. Hassan (Jack), Gustavo A. Oliva (Jack), Dayi Lin (Jack), Boyuan Chen (Jack), Zhen Ming (Jack), Jiang
0
0
The advent of Foundation Models (FMs) and AI-powered copilots has transformed the landscape of software development, offering unprecedented code completion capabilities and enhancing developer productivity. However, the current task-driven nature of these copilots falls short in addressing the broader goals and complexities inherent in software engineering (SE). In this paper, we propose a paradigm shift towards goal-driven AI-powered pair programmers that collaborate with human developers in a more holistic and context-aware manner. We envision AI pair programmers that are goal-driven, human partners, SE-aware, and self-learning. These AI partners engage in iterative, conversation-driven development processes, aligning closely with human goals and facilitating informed decision-making. We discuss the desired attributes of such AI pair programmers and outline key challenges that must be addressed to realize this vision. Ultimately, our work represents a shift from AI-augmented SE to AI-transformed SE by replacing code completion with a collaborative partnership between humans and AI that enhances both productivity and software quality.
4/17/2024
Open-Source AI-based SE Tools: Opportunities and Challenges of Collaborative Software Learning
Zhihao Lin, Wei Ma, Tao Lin, Yaowen Zheng, Jingquan Ge, Jun Wang, Jacques Klein, Tegawende Bissyande, Yang Liu, Li Li
0
0
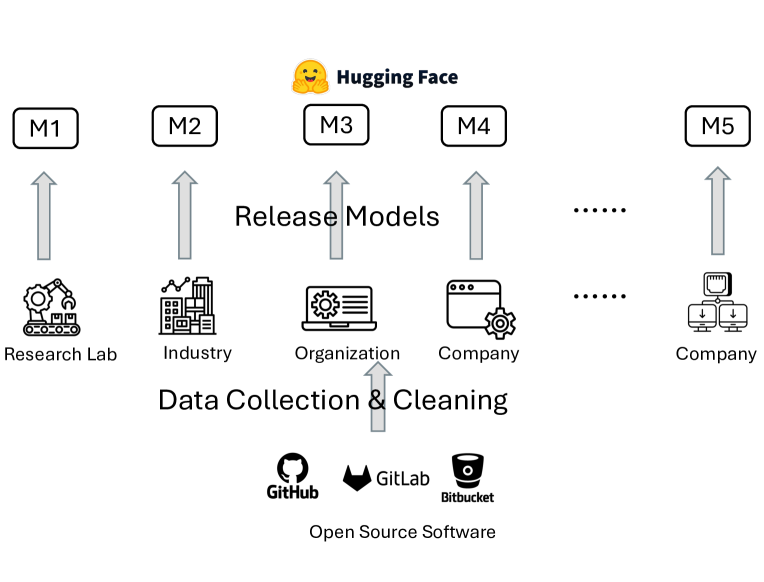
Large Language Models (LLMs) have become instrumental in advancing software engineering (SE) tasks, showcasing their efficacy in code understanding and beyond. Like traditional SE tools, open-source collaboration is key in realising the excellent products. However, with AI models, the essential need is in data. The collaboration of these AI-based SE models hinges on maximising the sources of high-quality data. However, data especially of high quality, often holds commercial or sensitive value, making it less accessible for open-source AI-based SE projects. This reality presents a significant barrier to the development and enhancement of AI-based SE tools within the software engineering community. Therefore, researchers need to find solutions for enabling open-source AI-based SE models to tap into resources by different organisations. Addressing this challenge, our position paper investigates one solution to facilitate access to diverse organizational resources for open-source AI models, ensuring privacy and commercial sensitivities are respected. We introduce a governance framework centered on federated learning (FL), designed to foster the joint development and maintenance of open-source AI code models while safeguarding data privacy and security. Additionally, we present guidelines for developers on AI-based SE tool collaboration, covering data requirements, model architecture, updating strategies, and version control. Given the significant influence of data characteristics on FL, our research examines the effect of code data heterogeneity on FL performance.
4/10/2024