Datasets of Visualization for Machine Learning

0

Sign in to get full access
Overview
- This paper provides an overview of datasets for visualization in machine learning applications.
- It covers a range of datasets that can be used to develop and evaluate visualization techniques for tasks such as data exploration, model interpretation, and autonomous driving.
- The paper also discusses how these datasets can be used to advance research in areas like information diffusion and collaborative perception.
Plain English Explanation
The paper presents a collection of datasets that can be used to develop and test visualization techniques for machine learning applications. These datasets cover a wide range of tasks, from exploring data to interpreting complex models and even supporting autonomous driving systems.
By using these datasets, researchers and developers can create visualizations that help humans better understand and interact with machine learning models. For example, a dataset on information diffusion could be used to develop visualizations that show how ideas or news spread through social networks. Similarly, a dataset on autonomous driving could be used to create visualizations that help humans monitor and trust the decisions made by self-driving cars.
The availability of these diverse datasets is important for advancing the field of visualization in machine learning. By providing a common set of benchmarks and test cases, researchers can more easily compare and improve their visualization techniques, ultimately leading to better tools for understanding and working with machine learning systems.
Technical Explanation
The paper begins by highlighting the growing importance of visualization in machine learning, as the field has become increasingly complex and opaque. To address this, the authors have compiled a comprehensive list of datasets that can be used to develop and evaluate visualization techniques for a variety of machine learning tasks.
The datasets covered in the paper span a range of applications, including:
- Data exploration: Datasets that can be used to create visualizations for exploring and understanding large, high-dimensional datasets.
- Model interpretation: Datasets that can be used to develop visualizations that help explain the inner workings of machine learning models, such as neural networks.
- Autonomous driving: Datasets that can be used to create visualizations for monitoring and understanding the behavior of autonomous vehicles.
- Information diffusion: Datasets that can be used to develop visualizations for tracking the spread of information, ideas, or rumors through social networks.
- Collaborative perception: Datasets that can be used to create visualizations for understanding how multiple agents, such as autonomous vehicles, can cooperate and share information.
The paper also discusses how these datasets can be used to advance research in visualization for machine learning, by providing common benchmarks and test cases that enable researchers to more easily compare and improve their techniques.
Critical Analysis
The paper provides a comprehensive overview of datasets that can be used to develop and evaluate visualization techniques for machine learning. By covering a wide range of applications, the authors have highlighted the growing importance of visualization in the field and the need for robust, diverse datasets to support this research.
One potential limitation of the paper is that it does not delve into the specific characteristics or quality of the individual datasets. While the authors have provided a broad survey, readers may still need to do additional research to understand the precise features, strengths, and weaknesses of each dataset before deciding which one is most appropriate for their needs.
Additionally, the paper does not address potential biases or limitations in the datasets themselves, which could influence the development and evaluation of visualization techniques. For example, if a dataset on autonomous driving is skewed towards certain geographic regions or driving conditions, the resulting visualizations may not generalize well to other scenarios.
Despite these minor limitations, the paper serves as a valuable resource for researchers and developers working on visualization techniques for machine learning. By highlighting the availability of these diverse datasets, the authors have opened the door for more focused and impactful research in this important area.
Conclusion
This paper provides a comprehensive overview of datasets that can be used to develop and evaluate visualization techniques for machine learning applications. By covering a wide range of tasks and use cases, the authors have highlighted the growing importance of visualization in the field and the need for robust, diverse datasets to support this research.
The availability of these datasets is a critical step forward, as it allows researchers and developers to more easily compare and improve their visualization techniques, ultimately leading to better tools for understanding and working with machine learning systems. As the field of machine learning continues to evolve, the insights and resources provided in this paper will be invaluable for advancing the state of the art in visualization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Datasets of Visualization for Machine Learning
Can Liu, Ruike Jiang, Shaocong Tan, Jiacheng Yu, Chaofan Yang, Hanning Shao, Xiaoru Yuan
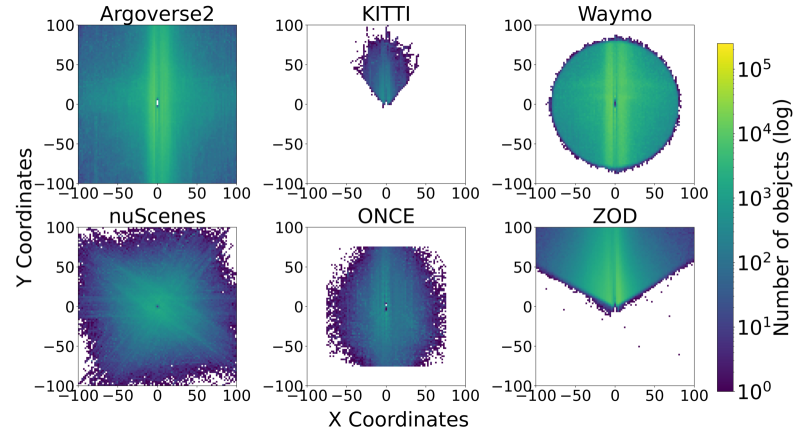
Datasets of visualization play a crucial role in automating data-driven visualization pipelines, serving as the foundation for supervised model training and algorithm benchmarking. In this paper, we survey the literature on visualization datasets and provide a comprehensive overview of existing visualization datasets, including their data types, formats, supported tasks, and openness. We propose a what-why-how model for visualization datasets, considering the content of the dataset (what), the supported tasks (why), and the dataset construction process (how). This model provides a clear understanding of the diversity and complexity of visualization datasets. Additionally, we highlight the challenges faced by existing visualization datasets, including the lack of standardization in data types and formats and the limited availability of large-scale datasets. To address these challenges, we suggest future research directions.
Read more7/24/2024
0
A Survey on Autonomous Driving Datasets: Statistics, Annotation Quality, and a Future Outlook
Mingyu Liu, Ekim Yurtsever, Jonathan Fossaert, Xingcheng Zhou, Walter Zimmer, Yuning Cui, Bare Luka Zagar, Alois C. Knoll
Autonomous driving has rapidly developed and shown promising performance due to recent advances in hardware and deep learning techniques. High-quality datasets are fundamental for developing reliable autonomous driving algorithms. Previous dataset surveys either focused on a limited number or lacked detailed investigation of dataset characteristics. To this end, we present an exhaustive study of 265 autonomous driving datasets from multiple perspectives, including sensor modalities, data size, tasks, and contextual conditions. We introduce a novel metric to evaluate the impact of datasets, which can also be a guide for creating new datasets. Besides, we analyze the annotation processes, existing labeling tools, and the annotation quality of datasets, showing the importance of establishing a standard annotation pipeline. On the other hand, we thoroughly analyze the impact of geographical and adversarial environmental conditions on the performance of autonomous driving systems. Moreover, we exhibit the data distribution of several vital datasets and discuss their pros and cons accordingly. Finally, we discuss the current challenges and the development trend of the future autonomous driving datasets.
Read more4/24/2024

0
AI Competitions and Benchmarks: Dataset Development
Romain Egele, Julio C. S. Jacques Junior, Jan N. van Rijn, Isabelle Guyon, Xavier Bar'o, Albert Clap'es, Prasanna Balaprakash, Sergio Escalera, Thomas Moeslund, Jun Wan
Machine learning is now used in many applications thanks to its ability to predict, generate, or discover patterns from large quantities of data. However, the process of collecting and transforming data for practical use is intricate. Even in today's digital era, where substantial data is generated daily, it is uncommon for it to be readily usable; most often, it necessitates meticulous manual data preparation. The haste in developing new models can frequently result in various shortcomings, potentially posing risks when deployed in real-world scenarios (eg social discrimination, critical failures), leading to the failure or substantial escalation of costs in AI-based projects. This chapter provides a comprehensive overview of established methodological tools, enriched by our practical experience, in the development of datasets for machine learning. Initially, we develop the tasks involved in dataset development and offer insights into their effective management (including requirements, design, implementation, evaluation, distribution, and maintenance). Then, we provide more details about the implementation process which includes data collection, transformation, and quality evaluation. Finally, we address practical considerations regarding dataset distribution and maintenance.
Read more4/16/2024

0
Do Text-to-Vis Benchmarks Test Real Use of Visualisations?
Hy Nguyen, Xuefei He, Andrew Reeson, Cecile Paris, Josiah Poon, Jonathan K. Kummerfeld
Large language models are able to generate code for visualisations in response to user requests. This is a useful application, and an appealing one for NLP research because plots of data provide grounding for language. However, there are relatively few benchmarks, and it is unknown whether those that exist are representative of what people do in practice. This paper aims to answer that question through an empirical study comparing benchmark datasets and code from public repositories. Our findings reveal a substantial gap in datasets, with evaluations not testing the same distribution of chart types, attributes, and the number of actions. The only representative dataset requires modification to become an end-to-end and practical benchmark. This shows that new, more benchmarks are needed to support the development of systems that truly address users' visualisation needs. These observations will guide future data creation, highlighting which features hold genuine significance for users.
Read more8/16/2024