DATTA: Towards Diversity Adaptive Test-Time Adaptation in Dynamic Wild World

0

Sign in to get full access
Overview
- Introduces DATTA, a novel approach for diversity-adaptive test-time adaptation in dynamic environments
- Highlights the importance of handling distribution shifts and diverse data during model deployment
- Proposes a framework that can dynamically adapt to various distribution shifts at test time
Plain English Explanation
The paper presents a new technique called DATTA (Diversity Adaptive Test-Time Adaptation) that aims to improve the performance of machine learning models in real-world, dynamic environments. When deploying a model, it's common for the data it encounters to differ from the data it was trained on, a phenomenon known as a "distribution shift." DATTA is designed to help models adapt to these shifts on-the-fly, during the testing or deployment phase.
The key insight behind DATTA is that real-world data can be highly diverse, with many different types of distribution shifts occurring. Rather than try to anticipate and handle each shift individually, DATTA takes a more general approach. It learns to dynamically adapt the model to whatever distribution shift is present, without requiring prior knowledge of the specific shift. This makes DATTA more robust and versatile compared to traditional test-time adaptation methods.
The paper demonstrates the effectiveness of DATTA through experiments on various computer vision tasks, showing that it can outperform other state-of-the-art techniques for handling distribution shifts. By making models more adaptable and resilient, DATTA has the potential to improve the real-world performance and deployability of machine learning systems.
Technical Explanation
The DATTA framework consists of two main components: a Diversity Estimator and a Diversity Adaptive Adapter. The Diversity Estimator learns to identify the degree of distribution shift in the test-time data, capturing the diversity of the encountered domain. The Diversity Adaptive Adapter then leverages this diversity information to dynamically adjust the model, performing test-time adaptation.
Specifically, the Diversity Estimator uses contrastive learning to learn a representation that encodes the degree of distribution shift. This representation is then used to predict a "diversity score" for each test sample, indicating how different it is from the training data. The Diversity Adaptive Adapter then uses this diversity score to modulate the model's activations, allowing it to adapt to the detected distribution shift.
The paper evaluates DATTA on several computer vision tasks, including image classification, object detection, and semantic segmentation. The results show that DATTA outperforms other test-time adaptation methods, particularly in scenarios with diverse and dynamic distribution shifts. The authors attribute this to DATTA's ability to capture and adapt to the full spectrum of distribution shifts, rather than targeting specific types of shifts.
Critical Analysis
The DATTA paper makes a compelling case for the importance of diversity-aware test-time adaptation, and the proposed framework represents a significant advance in this area. However, some potential limitations and areas for further research are worth considering:
- The paper focuses on computer vision tasks, and it's unclear how well DATTA would generalize to other domains, such as natural language processing or speech recognition.
- The diversity estimation component of DATTA relies on contrastive learning, which can be sensitive to hyperparameter tuning and the choice of data augmentation techniques. More robust diversity estimation methods could further improve DATTA's performance.
- While DATTA is designed to handle diverse distribution shifts, the paper does not explore the limits of its capabilities. Investigating the types of shifts that DATTA struggles with could inform future research directions.
- The computational overhead of the Diversity Estimator and Diversity Adaptive Adapter is not discussed, which could be an important practical consideration for real-world deployment.
Overall, the DATTA framework represents an important step towards building more robust and adaptable machine learning systems for dynamic, real-world environments. Future research building on these ideas could lead to even more versatile and capable test-time adaptation techniques.
Conclusion
The DATTA paper introduces a novel approach to test-time adaptation that aims to handle diverse distribution shifts encountered during model deployment. By learning to estimate the degree of distribution shift and dynamically adapt the model accordingly, DATTA demonstrates improved performance compared to other state-of-the-art techniques. This work highlights the importance of developing adaptive and resilient machine learning systems that can thrive in the complex, ever-changing real world. As the field of machine learning continues to mature, techniques like DATTA will be crucial for unlocking the full potential of these technologies in practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DATTA: Towards Diversity Adaptive Test-Time Adaptation in Dynamic Wild World
Chuyang Ye, Dongyan Wei, Zhendong Liu, Yuanyi Pang, Yixi Lin, Jiarong Liao, Qinting Jiang, Xianghua Fu, Qing Li, Jingyan Jiang
Test-time adaptation (TTA) effectively addresses distribution shifts between training and testing data by adjusting models on test samples, which is crucial for improving model inference in real-world applications. However, traditional TTA methods typically follow a fixed pattern to address the dynamic data patterns (low-diversity or high-diversity patterns) often leading to performance degradation and consequently a decline in Quality of Experience (QoE). The primary issues we observed are:Different scenarios require different normalization methods (e.g., Instance Normalization is optimal in mixed domains but not in static domains). Model fine-tuning can potentially harm the model and waste time.Hence, it is crucial to design strategies for effectively measuring and managing distribution diversity to minimize its negative impact on model performance. Based on these observations, this paper proposes a new general method, named Diversity Adaptive Test-Time Adaptation (DATTA), aimed at improving QoE. DATTA dynamically selects the best batch normalization methods and fine-tuning strategies by leveraging the Diversity Score to differentiate between high and low diversity score batches. It features three key components: Diversity Discrimination (DD) to assess batch diversity, Diversity Adaptive Batch Normalization (DABN) to tailor normalization methods based on DD insights, and Diversity Adaptive Fine-Tuning (DAFT) to selectively fine-tune the model. Experimental results show that our method achieves up to a 21% increase in accuracy compared to state-of-the-art methodologies, indicating that our method maintains good model performance while demonstrating its robustness. Our code will be released soon.
Read more8/16/2024
0
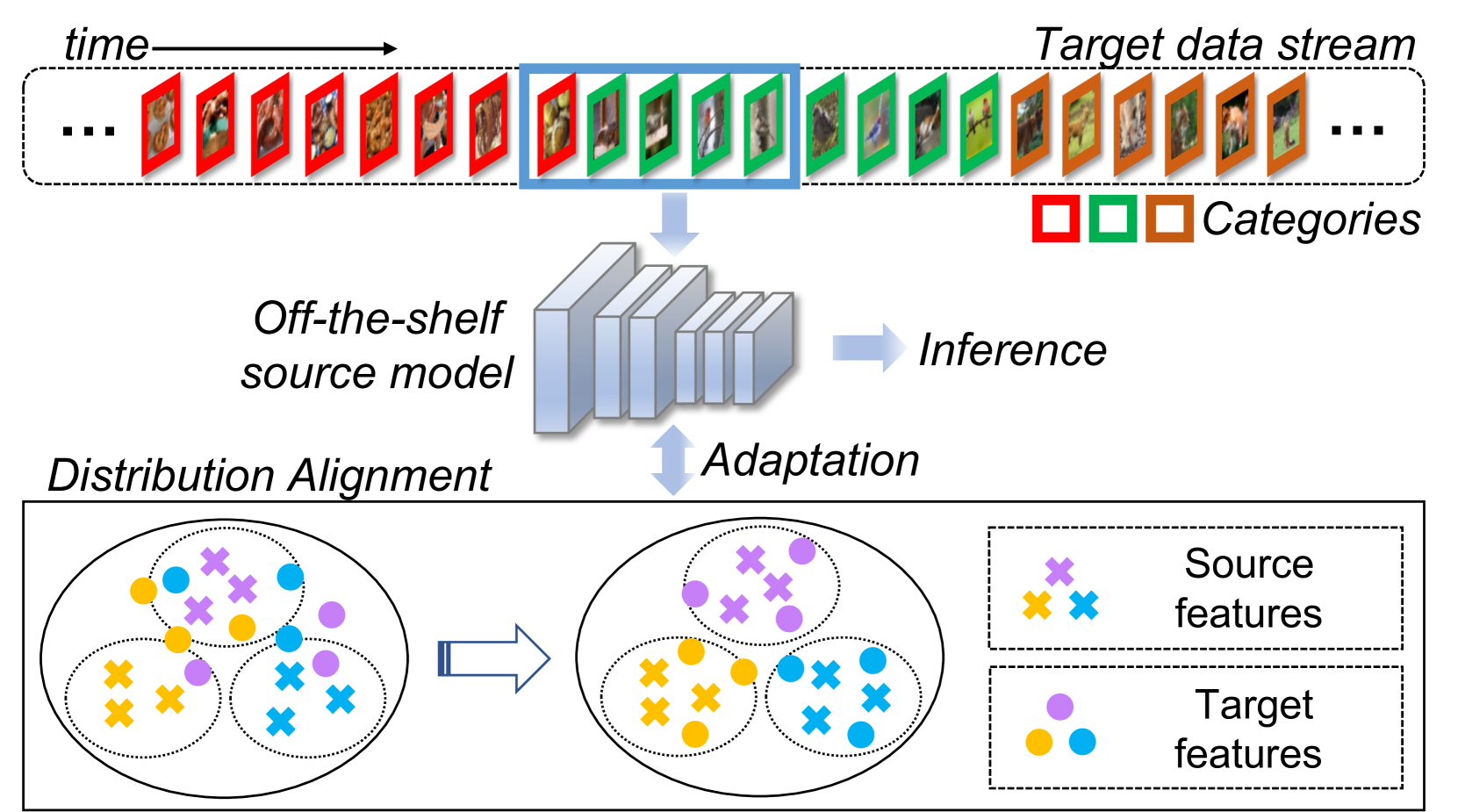
Distribution Alignment for Fully Test-Time Adaptation with Dynamic Online Data Streams
Ziqiang Wang, Zhixiang Chi, Yanan Wu, Li Gu, Zhi Liu, Konstantinos Plataniotis, Yang Wang
Given a model trained on source data, Test-Time Adaptation (TTA) enables adaptation and inference in test data streams with domain shifts from the source. Current methods predominantly optimize the model for each incoming test data batch using self-training loss. While these methods yield commendable results in ideal test data streams, where batches are independently and identically sampled from the target distribution, they falter under more practical test data streams that are not independent and identically distributed (non-i.i.d.). The data batches in a non-i.i.d. stream display prominent label shifts relative to each other. It leads to conflicting optimization objectives among batches during the TTA process. Given the inherent risks of adapting the source model to unpredictable test-time distributions, we reverse the adaptation process and propose a novel Distribution Alignment loss for TTA. This loss guides the distributions of test-time features back towards the source distributions, which ensures compatibility with the well-trained source model and eliminates the pitfalls associated with conflicting optimization objectives. Moreover, we devise a domain shift detection mechanism to extend the success of our proposed TTA method in the continual domain shift scenarios. Our extensive experiments validate the logic and efficacy of our method. On six benchmark datasets, we surpass existing methods in non-i.i.d. scenarios and maintain competitive performance under the ideal i.i.d. assumption.
Read more7/18/2024

0
Active Test-Time Adaptation: Theoretical Analyses and An Algorithm
Shurui Gui, Xiner Li, Shuiwang Ji
Test-time adaptation (TTA) addresses distribution shifts for streaming test data in unsupervised settings. Currently, most TTA methods can only deal with minor shifts and rely heavily on heuristic and empirical studies. To advance TTA under domain shifts, we propose the novel problem setting of active test-time adaptation (ATTA) that integrates active learning within the fully TTA setting. We provide a learning theory analysis, demonstrating that incorporating limited labeled test instances enhances overall performances across test domains with a theoretical guarantee. We also present a sample entropy balancing for implementing ATTA while avoiding catastrophic forgetting (CF). We introduce a simple yet effective ATTA algorithm, known as SimATTA, using real-time sample selection techniques. Extensive experimental results confirm consistency with our theoretical analyses and show that the proposed ATTA method yields substantial performance improvements over TTA methods while maintaining efficiency and shares similar effectiveness to the more demanding active domain adaptation (ADA) methods. Our code is available at https://github.com/divelab/ATTA
Read more4/9/2024
🤯
0
Discover Your Neighbors: Advanced Stable Test-Time Adaptation in Dynamic World
Qinting Jiang, Chuyang Ye, Dongyan Wei, Yuan Xue, Jingyan Jiang, Zhi Wang
Despite progress, deep neural networks still suffer performance declines under distribution shifts between training and test domains, leading to a substantial decrease in Quality of Experience (QoE) for multimedia applications. Existing test-time adaptation (TTA) methods are challenged by dynamic, multiple test distributions within batches. This work provides a new perspective on analyzing batch normalization techniques through class-related and class-irrelevant features, our observations reveal combining source and test batch normalization statistics robustly characterizes target distributions. However, test statistics must have high similarity. We thus propose Discover Your Neighbours (DYN), the first backward-free approach specialized for dynamic TTA. The core innovation is identifying similar samples via instance normalization statistics and clustering into groups which provides consistent class-irrelevant representations. Specifically, Our DYN consists of layer-wise instance statistics clustering (LISC) and cluster-aware batch normalization (CABN). In LISC, we perform layer-wise clustering of approximate feature samples at each BN layer by calculating the cosine similarity of instance normalization statistics across the batch. CABN then aggregates SBN and TCN statistics to collaboratively characterize the target distribution, enabling more robust representations. Experimental results validate DYN's robustness and effectiveness, demonstrating maintained performance under dynamic data stream patterns.
Read more6/11/2024