DBCopilot: Scaling Natural Language Querying to Massive Databases
2312.03463
0
0
Abstract
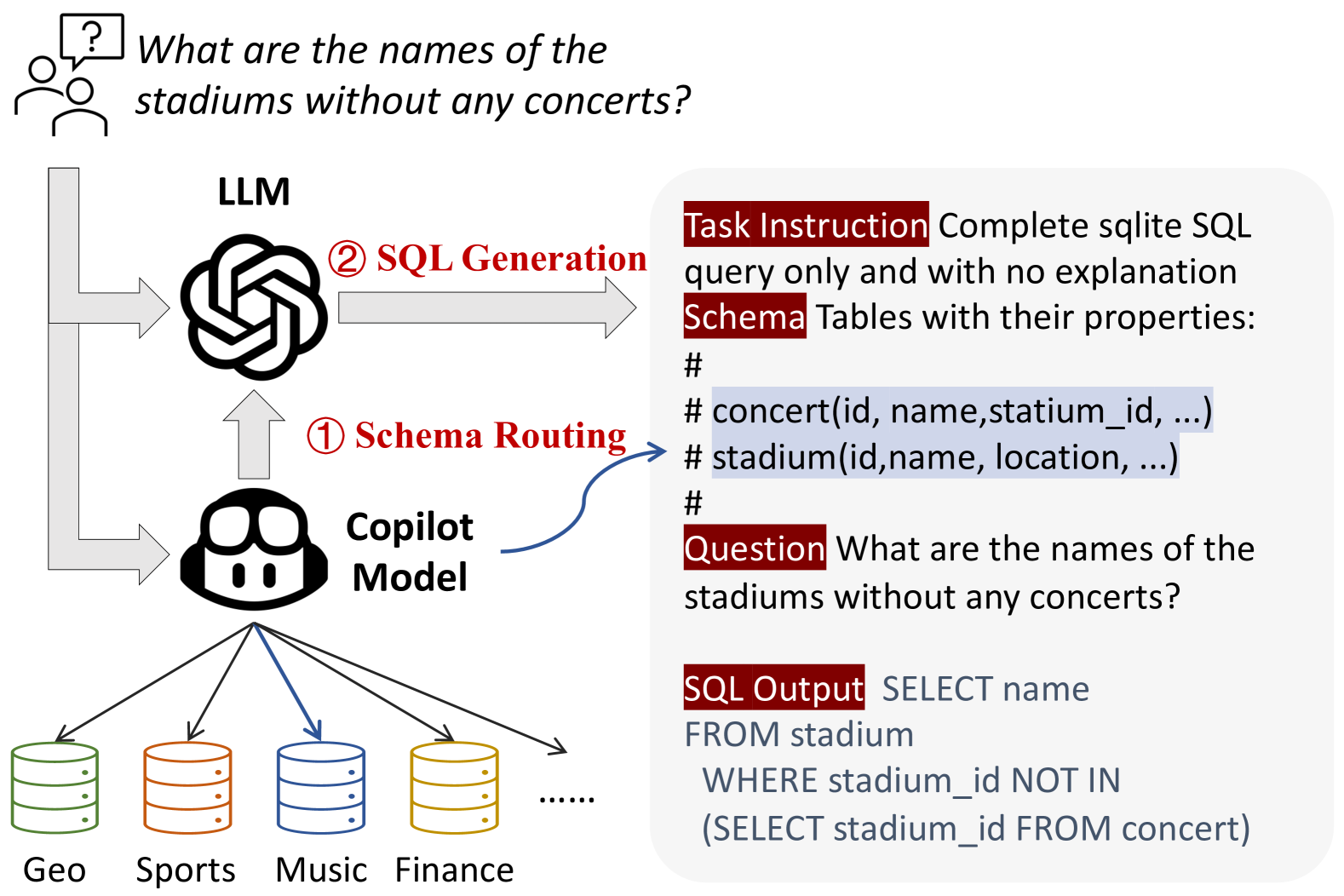
Text-to-SQL simplifies database interactions by enabling non-experts to convert their natural language (NL) questions into Structured Query Language (SQL) queries. While recent advances in large language models (LLMs) have improved the zero-shot text-to-SQL paradigm, existing methods face scalability challenges when dealing with massive, dynamically changing databases. This paper introduces DBCopilot, a framework that addresses these challenges by employing a compact and flexible copilot model for routing across massive databases. Specifically, DBCopilot decouples the text-to-SQL process into schema routing and SQL generation, leveraging a lightweight sequence-to-sequence neural network-based router to formulate database connections and navigate natural language questions through databases and tables. The routed schemas and questions are then fed into LLMs for efficient SQL generation. Furthermore, DBCopilot also introduced a reverse schema-to-question generation paradigm, which can learn and adapt the router over massive databases automatically without requiring manual intervention. Experimental results demonstrate that DBCopilot is a scalable and effective solution for real-world text-to-SQL tasks, providing a significant advancement in handling large-scale schemas.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents DBCopilot, a system that enables natural language querying of massive databases at scale.
- The system leverages large language models to translate natural language queries into SQL queries, allowing users to interact with databases using plain language.
- DBCopilot is designed to handle complex queries and large datasets, making it a powerful tool for data analysis and exploration.
Plain English Explanation
Bridging the Gap Between Humans and Massive Databases Imagine you have access to a vast database, but the only way to interact with it is by writing complex SQL queries. This can be a daunting task, especially for those without a technical background. DBCopilot aims to change that by allowing users to ask questions in plain language and have the system translate those into the necessary SQL commands.
This is particularly useful when working with large, complex datasets, where the ability to explore and query the data in an intuitive way can lead to valuable insights. EPI-SQL and DuboSQL are other systems that tackle similar problems, using different approaches to translate natural language into SQL.
By bridging the gap between human language and the technical requirements of databases, DBCopilot makes it easier for a wide range of users to access and analyze large amounts of data, opening up new possibilities for data-driven decision making and discovery.
Technical Explanation
Scaling Natural Language Querying to Massive Databases The key innovation of DBCopilot is its ability to handle complex natural language queries and translate them into efficient SQL queries that can be executed on massive databases. The system leverages large language models, which are trained on vast amounts of text data, to understand the semantics and intent behind the user's queries.
The NL2KQL system uses a similar approach to translate natural language into another database query language, Kusto. DBCopilot, on the other hand, focuses specifically on SQL, which is a more widely used and standardized language for relational databases.
The architecture of DBCopilot includes several components, such as a query parsing module, a SQL generation module, and a database execution module. The system is designed to be efficient and scalable, allowing it to handle large datasets and complex queries without sacrificing performance.
Critical Analysis
The authors of the paper have done a commendable job in developing a system that can bridge the gap between natural language and SQL queries. However, there are a few potential limitations and areas for further research:
-
Reliability and Trustworthiness: While the paper mentions that DBCopilot can handle complex queries, it's important to consider the reliability and trustworthiness of the system's output, especially when dealing with high-stakes decisions. The TrustSQL benchmark provides a framework for evaluating the reliability of text-to-SQL models, and this could be an area for further investigation.
-
Domain-Specific Knowledge: The performance of language models can be heavily influenced by the data they are trained on. It would be interesting to explore how DBCopilot's performance might vary across different domains or industries, and whether additional domain-specific fine-tuning could improve its capabilities.
-
Interpretability and Explainability: As more complex systems are developed for natural language-to-SQL translation, it becomes increasingly important to ensure that these systems are interpretable and explainable, so that users can understand the reasoning behind the generated queries and their results.
Conclusion
Overall, the DBCopilot system represents an important step forward in democratizing access to large, complex databases. By allowing users to interact with data using natural language, the system has the potential to unlock new insights and drive data-driven decision making across a wide range of applications. As the field of natural language-to-SQL translation continues to evolve, it will be essential to address the critical issues of reliability, trustworthiness, and interpretability to ensure that these technologies can be deployed safely and effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Data-Copilot: Bridging Billions of Data and Humans with Autonomous Workflow
Wenqi Zhang, Yongliang Shen, Weiming Lu, Yueting Zhuang
0
0
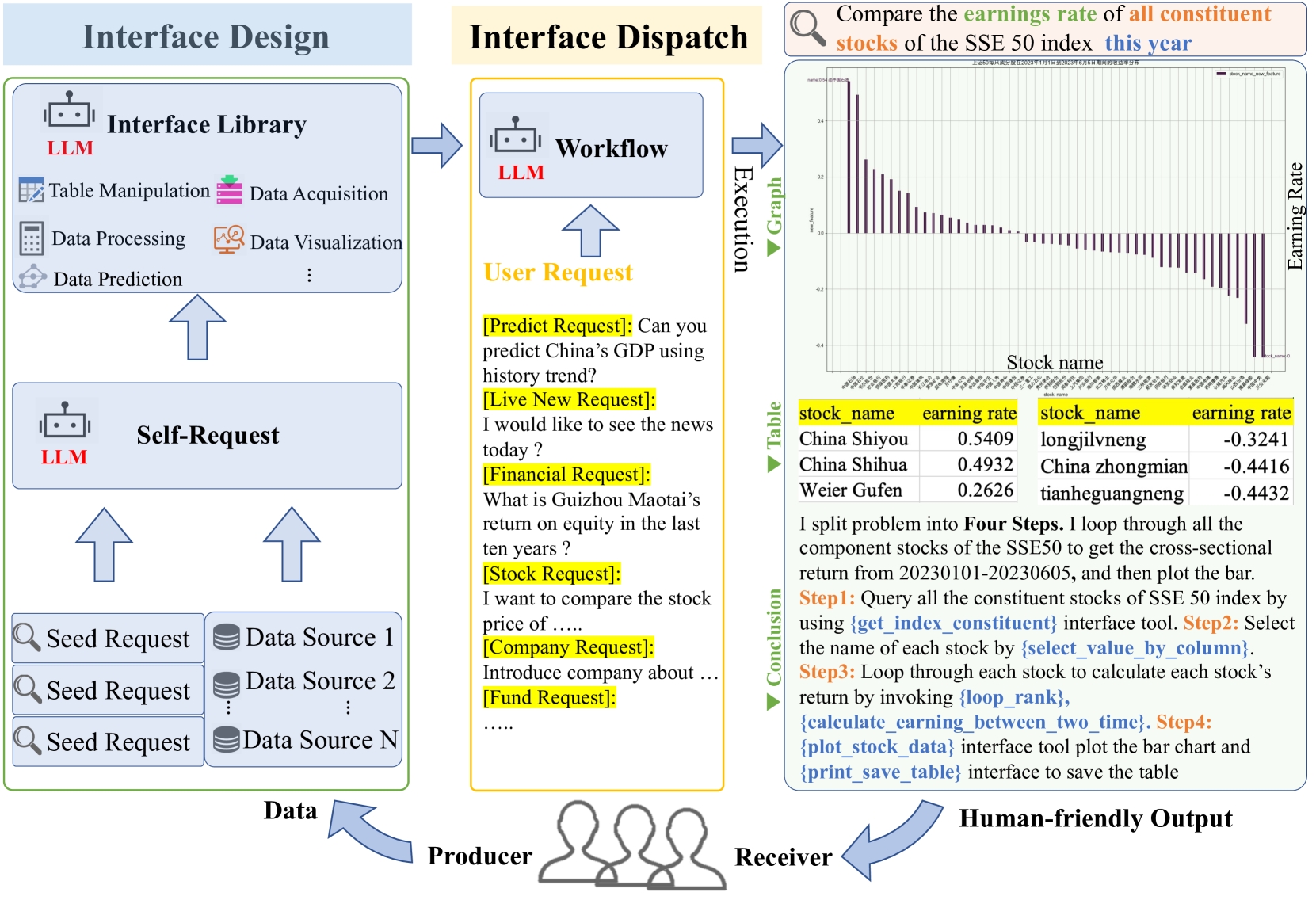
Various industries such as finance, meteorology, and energy produce vast amounts of heterogeneous data every day. There is a natural demand for humans to manage, process, and display data efficiently. However, it necessitates labor-intensive efforts and a high level of expertise for these data-related tasks. Considering large language models (LLMs) showcase promising capabilities in semantic understanding and reasoning, we advocate that the deployment of LLMs could autonomously manage and process massive amounts of data while interacting and displaying in a human-friendly manner. Based on this, we propose Data-Copilot, an LLM-based system that connects numerous data sources on one end and caters to diverse human demands on the other end. Acting as an experienced expert, Data-Copilot autonomously transforms raw data into multi-form output that best matches the user's intent. Specifically, it first designs multiple universal interfaces to satisfy diverse data-related requests, like querying, analysis, prediction, and visualization. In real-time response, it automatically deploys a concise workflow by invoking corresponding interfaces. The whole process is fully controlled by Data-Copilot, without human assistance. We release Data-Copilot-1.0 using massive Chinese financial data, e.g., stocks, funds, and news. Experiments indicate it achieves reliable performance with lower token consumption, showing promising application prospects.
5/8/2024
🌿
Natural Language Interfaces for Tabular Data Querying and Visualization: A Survey
Weixu Zhang, Yifei Wang, Yuanfeng Song, Victor Junqiu Wei, Yuxing Tian, Yiyan Qi, Jonathan H. Chan, Raymond Chi-Wing Wong, Haiqin Yang
0
0
The emergence of natural language processing has revolutionized the way users interact with tabular data, enabling a shift from traditional query languages and manual plotting to more intuitive, language-based interfaces. The rise of large language models (LLMs) such as ChatGPT and its successors has further advanced this field, opening new avenues for natural language processing techniques. This survey presents a comprehensive overview of natural language interfaces for tabular data querying and visualization, which allow users to interact with data using natural language queries. We introduce the fundamental concepts and techniques underlying these interfaces with a particular emphasis on semantic parsing, the key technology facilitating the translation from natural language to SQL queries or data visualization commands. We then delve into the recent advancements in Text-to-SQL and Text-to-Vis problems from the perspectives of datasets, methodologies, metrics, and system designs. This includes a deep dive into the influence of LLMs, highlighting their strengths, limitations, and potential for future improvements. Through this survey, we aim to provide a roadmap for researchers and practitioners interested in developing and applying natural language interfaces for data interaction in the era of large language models.
5/14/2024
🤿
EPI-SQL: Enhancing Text-to-SQL Translation with Error-Prevention Instructions
Xiping Liu, Zhao Tan
0
0
The conversion of natural language queries into SQL queries, known as Text-to-SQL, is a critical yet challenging task. This paper introduces EPI-SQL, a novel methodological framework leveraging Large Language Models (LLMs) to enhance the performance of Text-to-SQL tasks. EPI-SQL operates through a four-step process. Initially, the method involves gathering instances from the Spider dataset on which LLMs are prone to failure. These instances are then utilized to generate general error-prevention instructions (EPIs). Subsequently, LLMs craft contextualized EPIs tailored to the specific context of the current task. Finally, these context-specific EPIs are incorporated into the prompt used for SQL generation. EPI-SQL is distinguished in that it provides task-specific guidance, enabling the model to circumvent potential errors for the task at hand. Notably, the methodology rivals the performance of advanced few-shot methods despite being a zero-shot approach. An empirical assessment using the Spider benchmark reveals that EPI-SQL achieves an execution accuracy of 85.1%, underscoring its effectiveness in generating accurate SQL queries through LLMs. The findings indicate a promising direction for future research, i.e. enhancing instructions with task-specific and contextualized rules, for boosting LLMs' performance in NLP tasks.
4/24/2024
MCS-SQL: Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to-SQL Generation
Dongjun Lee, Choongwon Park, Jaehyuk Kim, Heesoo Park
0
0
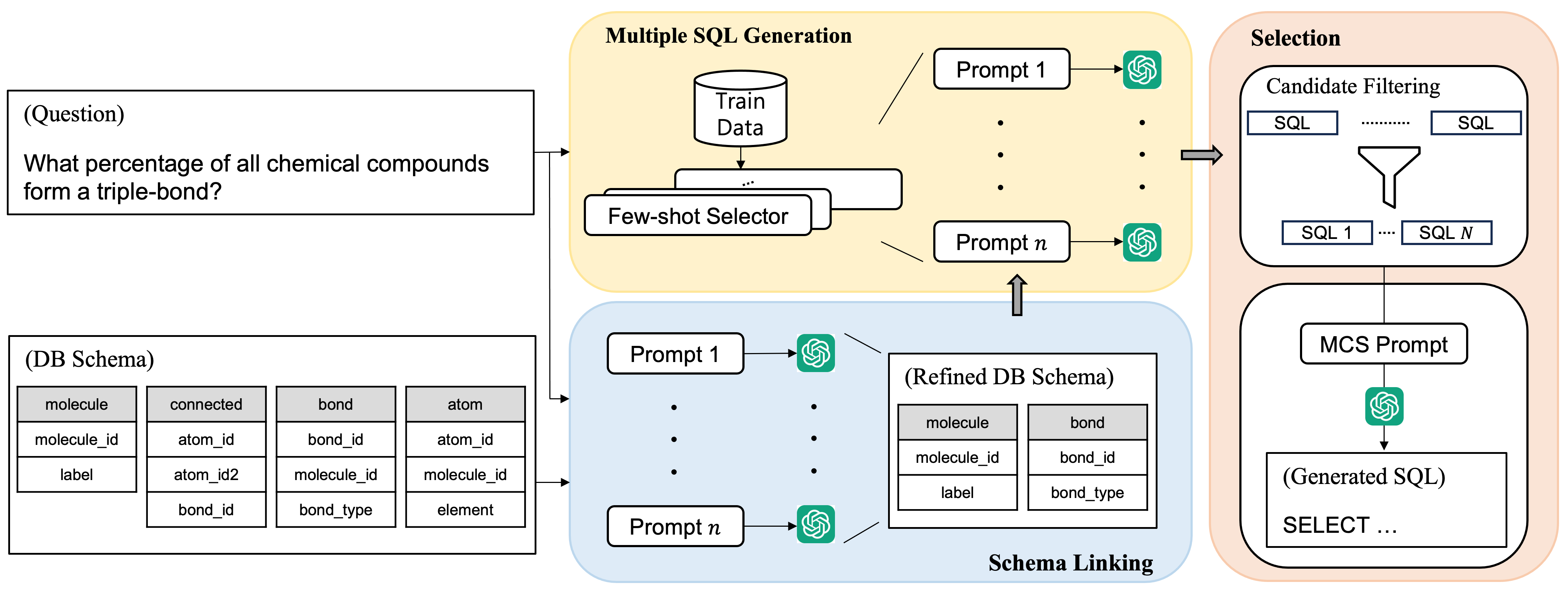
Recent advancements in large language models (LLMs) have enabled in-context learning (ICL)-based methods that significantly outperform fine-tuning approaches for text-to-SQL tasks. However, their performance is still considerably lower than that of human experts on benchmarks that include complex schemas and queries, such as BIRD. This study considers the sensitivity of LLMs to the prompts and introduces a novel approach that leverages multiple prompts to explore a broader search space for possible answers and effectively aggregate them. Specifically, we robustly refine the database schema through schema linking using multiple prompts. Thereafter, we generate various candidate SQL queries based on the refined schema and diverse prompts. Finally, the candidate queries are filtered based on their confidence scores, and the optimal query is obtained through a multiple-choice selection that is presented to the LLM. When evaluated on the BIRD and Spider benchmarks, the proposed method achieved execution accuracies of 65.5% and 89.6%, respectively, significantly outperforming previous ICL-based methods. Moreover, we established a new SOTA performance on the BIRD in terms of both the accuracy and efficiency of the generated queries.
5/14/2024