MCS-SQL: Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to-SQL Generation

0
Sign in to get full access
Overview
- The paper "MCS-SQL: Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to-SQL Generation" explores a novel approach to improving the performance of text-to-SQL generation models.
- The key idea is to use multiple prompts and a multiple-choice selection mechanism to better capture the user's intent and generate more accurate SQL queries.
- The proposed MCS-SQL model outperforms existing state-of-the-art text-to-SQL models on several benchmark datasets.
Plain English Explanation
The paper presents a new way to improve the ability of AI models to understand natural language and generate the corresponding SQL code. The core idea is to give the model multiple ways to interpret the user's request, rather than just a single prompt. This allows the model to better grasp the user's intent and produce more accurate SQL queries as a result.
The researchers developed a model called MCS-SQL that takes in the user's natural language request and generates several candidate SQL queries. The user then selects the one that best matches their intent from a multiple-choice list. This interactive process helps the model learn from the user's feedback and refine its understanding over time.
The key advantage of MCS-SQL is that it can handle a wider range of language input and produce more reliable SQL queries compared to existing text-to-SQL approaches. This could be particularly helpful for users who are not familiar with SQL syntax but need to interact with databases. By making the translation from natural language to SQL more robust and intuitive, MCS-SQL aims to democratize access to data and database management.
Technical Explanation
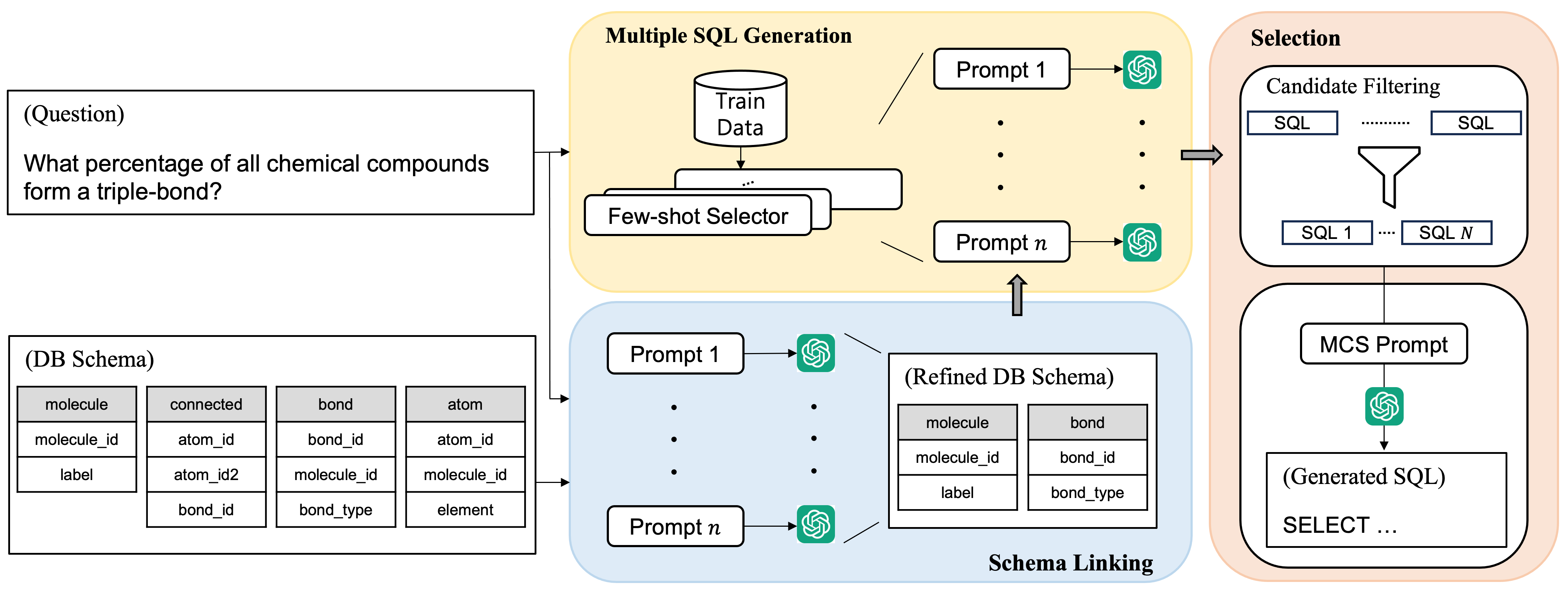
The paper introduces the MCS-SQL (Multiple Choice Selection for SQL) model, which leverages multiple prompts and a multiple-choice selection mechanism to improve text-to-SQL generation performance.
The MCS-SQL model first encodes the natural language input using a pre-trained language model. It then generates multiple candidate SQL queries using a conditional generation module. These candidate queries are presented to the user, who selects the one that best matches their intent. The selected query is then used to fine-tune the model's parameters, allowing it to learn from the user's feedback.
The researchers evaluate MCS-SQL on several text-to-SQL benchmarks, including Spider, SParC, and CoSQL. The results show that MCS-SQL outperforms existing state-of-the-art text-to-SQL models, demonstrating the effectiveness of the multiple prompt and multiple-choice selection approach.
Key insights from the technical explanation:
- The use of multiple prompts and a multiple-choice selection mechanism helps the model better capture the user's intent.
- The interactive learning process, where the user selects the most appropriate SQL query, allows the model to refine its understanding over time.
- MCS-SQL achieves state-of-the-art performance on several text-to-SQL benchmark datasets.
Critical Analysis
The paper presents a compelling approach to improving text-to-SQL generation, but there are a few potential limitations and areas for further research:
- The interactive nature of the MCS-SQL model may not be scalable in real-world scenarios, where users may not be willing or available to provide constant feedback.
- The paper does not address the potential privacy concerns that may arise from users providing feedback on sensitive data or database queries. Link to "Privacy-Preserving Prompt Engineering: A Survey"
- The authors could explore ways to further automate the multiple prompt generation process, perhaps by leveraging techniques like Automatic Prompt Generation for Tabular Data Tasks.
- Integrating MCS-SQL with other state-of-the-art text-to-SQL techniques, such as COE-SQL: Context-Aware Learning for Multi-Turn Text-to-SQL or the Open-SQL Framework, could further improve the model's performance and robustness.
Conclusion
The MCS-SQL model presented in this paper represents a significant advance in text-to-SQL generation by leveraging multiple prompts and a multiple-choice selection mechanism. This approach allows the model to better capture the user's intent and produce more accurate SQL queries, which could have important implications for democratizing access to data and database management.
While the paper highlights the effectiveness of the MCS-SQL approach, the researchers should continue to explore ways to address the potential scalability and privacy concerns, as well as investigate opportunities to integrate their work with other state-of-the-art techniques in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MCS-SQL: Leveraging Multiple Prompts and Multiple-Choice Selection For Text-to-SQL Generation
Dongjun Lee, Choongwon Park, Jaehyuk Kim, Heesoo Park
Recent advancements in large language models (LLMs) have enabled in-context learning (ICL)-based methods that significantly outperform fine-tuning approaches for text-to-SQL tasks. However, their performance is still considerably lower than that of human experts on benchmarks that include complex schemas and queries, such as BIRD. This study considers the sensitivity of LLMs to the prompts and introduces a novel approach that leverages multiple prompts to explore a broader search space for possible answers and effectively aggregate them. Specifically, we robustly refine the database schema through schema linking using multiple prompts. Thereafter, we generate various candidate SQL queries based on the refined schema and diverse prompts. Finally, the candidate queries are filtered based on their confidence scores, and the optimal query is obtained through a multiple-choice selection that is presented to the LLM. When evaluated on the BIRD and Spider benchmarks, the proposed method achieved execution accuracies of 65.5% and 89.6%, respectively, significantly outperforming previous ICL-based methods. Moreover, we established a new SOTA performance on the BIRD in terms of both the accuracy and efficiency of the generated queries.
Read more5/14/2024
0
RB-SQL: A Retrieval-based LLM Framework for Text-to-SQL
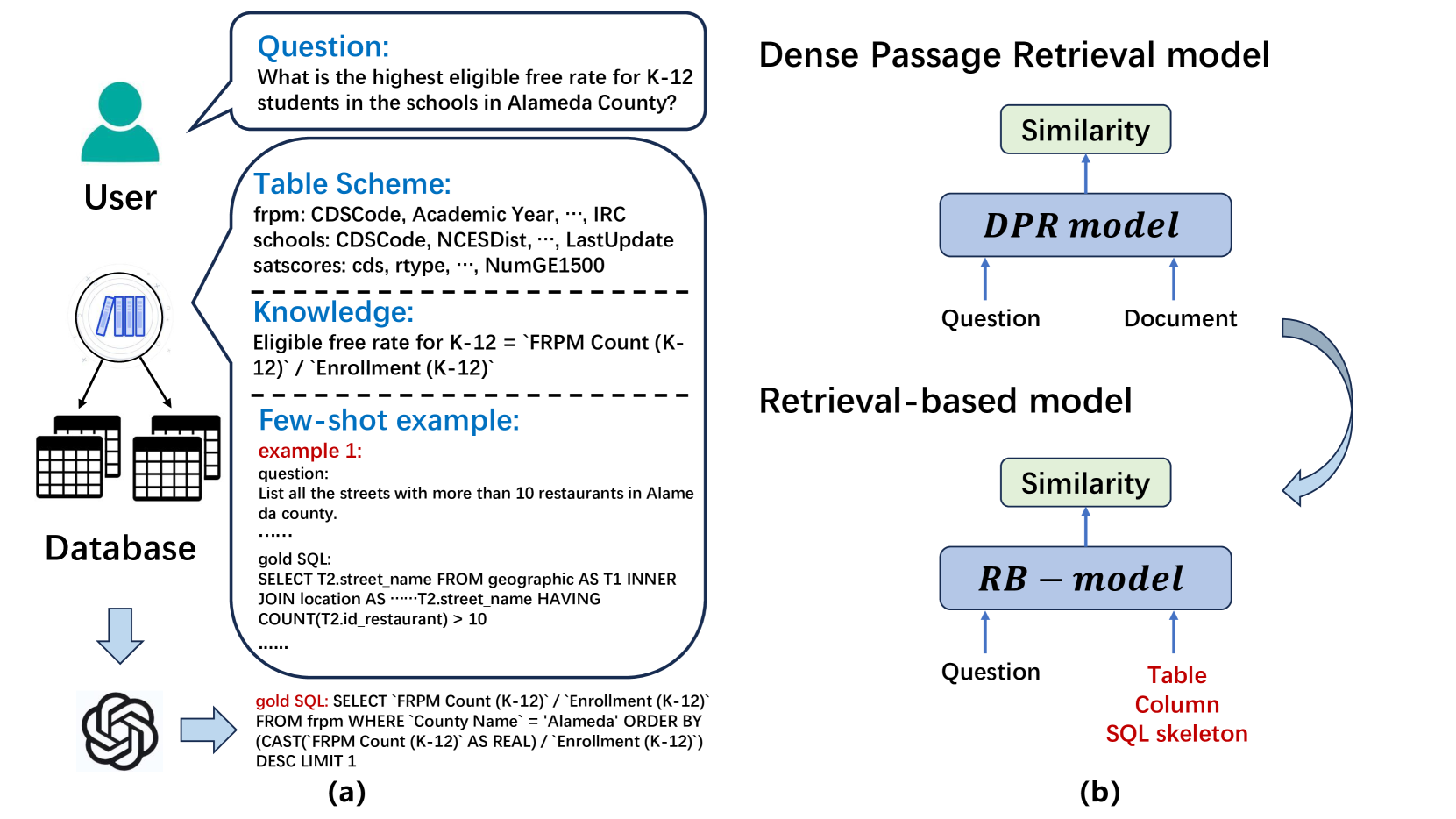
Zhenhe Wu, Zhongqiu Li, Jie Zhang, Mengxiang Li, Yu Zhao, Ruiyu Fang, Zhongjiang He, Xuelong Li, Zhoujun Li, Shuangyong Song
Large language models (LLMs) with in-context learning have significantly improved the performance of text-to-SQL task. Previous works generally focus on using exclusive SQL generation prompt to improve the LLMs' reasoning ability. However, they are mostly hard to handle large databases with numerous tables and columns, and usually ignore the significance of pre-processing database and extracting valuable information for more efficient prompt engineering. Based on above analysis, we propose RB-SQL, a novel retrieval-based LLM framework for in-context prompt engineering, which consists of three modules that retrieve concise tables and columns as schema, and targeted examples for in-context learning. Experiment results demonstrate that our model achieves better performance than several competitive baselines on public datasets BIRD and Spider.
Read more7/15/2024

0
A Survey on Employing Large Language Models for Text-to-SQL Tasks
Liang Shi, Zhengju Tang, Nan Zhang, Xiaotong Zhang, Zhi Yang
The increasing volume of data stored in relational databases has led to the need for efficient querying and utilization of this data in various sectors. However, writing SQL queries requires specialized knowledge, which poses a challenge for non-professional users trying to access and query databases. Text-to-SQL parsing solves this issue by converting natural language queries into SQL queries, thus making database access more accessible for non-expert users. To take advantage of the recent developments in Large Language Models (LLMs), a range of new methods have emerged, with a primary focus on prompt engineering and fine-tuning. This survey provides a comprehensive overview of LLMs in text-to-SQL tasks, discussing benchmark datasets, prompt engineering, fine-tuning methods, and future research directions. We hope this review will enable readers to gain a broader understanding of the recent advances in this field and offer some insights into its future trajectory.
Read more9/10/2024
0
Open-SQL Framework: Enhancing Text-to-SQL on Open-source Large Language Models
Xiaojun Chen, Tianle Wang, Tianhao Qiu, Jianbin Qin, Min Yang
Despite the success of large language models (LLMs) in Text-to-SQL tasks, open-source LLMs encounter challenges in contextual understanding and response coherence. To tackle these issues, we present ours, a systematic methodology tailored for Text-to-SQL with open-source LLMs. Our contributions include a comprehensive evaluation of open-source LLMs in Text-to-SQL tasks, the openprompt strategy for effective question representation, and novel strategies for supervised fine-tuning. We explore the benefits of Chain-of-Thought in step-by-step inference and propose the openexample method for enhanced few-shot learning. Additionally, we introduce token-efficient techniques, such as textbf{Variable-length Open DB Schema}, textbf{Target Column Truncation}, and textbf{Example Column Truncation}, addressing challenges in large-scale databases. Our findings emphasize the need for further investigation into the impact of supervised fine-tuning on contextual learning capabilities. Remarkably, our method significantly improved Llama2-7B from 2.54% to 41.04% and Code Llama-7B from 14.54% to 48.24% on the BIRD-Dev dataset. Notably, the performance of Code Llama-7B surpassed GPT-4 (46.35%) on the BIRD-Dev dataset.
Read more5/14/2024