D$^3$: Scaling Up Deepfake Detection by Learning from Discrepancy
2404.04584
0
0
Abstract
The boom of Generative AI brings opportunities entangled with risks and concerns. In this work, we seek a step toward a universal deepfake detection system with better generalization and robustness, to accommodate the responsible deployment of diverse image generative models. We do so by first scaling up the existing detection task setup from the one-generator to multiple-generators in training, during which we disclose two challenges presented in prior methodological designs. Specifically, we reveal that the current methods tailored for training on one specific generator either struggle to learn comprehensive artifacts from multiple generators or tend to sacrifice their ability to identify fake images from seen generators (i.e., In-Domain performance) to exchange the generalization for unseen generators (i.e., Out-Of-Domain performance). To tackle the above challenges, we propose our Discrepancy Deepfake Detector (D$^3$) framework, whose core idea is to learn the universal artifacts from multiple generators by introducing a parallel network branch that takes a distorted image as extra discrepancy signal to supplement its original counterpart. Extensive scaled-up experiments on the merged UFD and GenImage datasets with six detection models demonstrate the effectiveness of our framework, achieving a 5.3% accuracy improvement in the OOD testing compared to the current SOTA methods while maintaining the ID performance.
Create account to get full access
Overview
- Proposes a novel approach called D³ (Deepfake Detection by Discrepancy) for scaling up deepfake detection
- Leverages discrepancies between real and generated images to train a robust deepfake detection model
- Demonstrates improved performance compared to existing methods on benchmark datasets
Plain English Explanation
The paper introduces a new technique called D³ (Deepfake Detection by Discrepancy) that aims to improve the scalability and performance of deepfake detection. Deepfakes are synthetic media, such as images or videos, that are created using machine learning to manipulate or generate content that appears realistic but is fake.
The key insight behind D³ is that there are often subtle discrepancies between real images and those generated by deepfake models. By training a model to detect these discrepancies, it can become more effective at identifying deepfakes. This is in contrast to some existing approaches that may rely on specific artifacts or traces of the deepfake creation process, which can be difficult to generalize.
The researchers demonstrate that D³ achieves better performance than previous methods on standard deepfake detection benchmarks. This suggests that learning from the discrepancies between real and fake media can be a powerful way to build more robust and scalable deepfake detection systems.
Technical Explanation
The D³ Scaling Up Deepfake Detection by Learning from Discrepancy paper proposes a novel approach for deepfake detection that leverages the discrepancies between real and generated images. The key idea is to train a model to identify the subtle differences between authentic and synthetic media, rather than relying on specific artifacts or traces of the deepfake creation process.
The authors first introduce the D³ architecture, which consists of two main components: a feature extractor and a discrepancy classifier. The feature extractor is responsible for capturing the relevant visual information from the input images, while the discrepancy classifier is trained to distinguish real images from deepfakes based on the extracted features.
To train the D³ model, the researchers use a novel loss function that encourages the model to learn the discrepancies between real and generated images. This is achieved by including a discrepancy loss term that penalizes the model when it fails to correctly identify the authenticity of the input.
The paper also presents an extensive evaluation of the D³ approach on several benchmark datasets for deepfake detection, including Towards More General Video-based Deepfake Detection, Deep Image Composition Meets Image Forgery, and G3DR: Generative 3D Reconstruction on ImageNet. The results show that D³ outperforms existing state-of-the-art methods, demonstrating the effectiveness of the discrepancy-based approach.
Critical Analysis
The D³ Scaling Up Deepfake Detection by Learning from Discrepancy paper presents a promising approach for improving the scalability and performance of deepfake detection. By focusing on learning the discrepancies between real and generated media, the authors have developed a method that can potentially generalize better to a wider range of deepfake types and techniques.
However, the paper does not address the potential limitations of the discrepancy-based approach. For example, it is possible that as deepfake generation techniques become more advanced, the discrepancies between real and synthetic media may become increasingly subtle and harder to detect. The authors could have discussed strategies for addressing this challenge, such as incorporating other complementary approaches or exploring more sophisticated feature extraction and classification techniques.
Additionally, the paper could have delved deeper into the interpretability and explainability of the D³ model. Understanding the specific visual cues and patterns that the model uses to detect deepfakes could provide valuable insights for further improving deepfake detection systems and for understanding the evolving landscape of deepfake generation techniques.
Despite these potential areas for further exploration, the D³ Scaling Up Deepfake Detection by Learning from Discrepancy paper represents a significant contribution to the field of deepfake detection. The authors have demonstrated the potential of discrepancy-based learning, and their work could inspire further research and development in this direction.
Conclusion
The D³ Scaling Up Deepfake Detection by Learning from Discrepancy paper presents a novel approach for improving the scalability and performance of deepfake detection. By leveraging the discrepancies between real and generated images, the D³ model is able to outperform existing state-of-the-art methods on benchmark datasets.
The key insight behind D³ is that there are often subtle visual differences between authentic and synthetic media, and that by learning to detect these discrepancies, the model can become more robust and effective at identifying deepfakes. This approach holds promise for addressing the growing challenge of deepfake proliferation, as it can potentially generalize better to a wider range of deepfake techniques compared to methods that rely on specific artifacts or traces of the generation process.
Overall, the D³ Scaling Up Deepfake Detection by Learning from Discrepancy paper represents an important contribution to the field of deepfake detection, and its findings could have significant implications for the development of more scalable and accurate deepfake detection systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!GM-DF: Generalized Multi-Scenario Deepfake Detection
Yingxin Lai, Zitong Yu, Jing Yang, Bin Li, Xiangui Kang, Linlin Shen
0
0
Existing face forgery detection usually follows the paradigm of training models in a single domain, which leads to limited generalization capacity when unseen scenarios and unknown attacks occur. In this paper, we elaborately investigate the generalization capacity of deepfake detection models when jointly trained on multiple face forgery detection datasets. We first find a rapid degradation of detection accuracy when models are directly trained on combined datasets due to the discrepancy across collection scenarios and generation methods. To address the above issue, a Generalized Multi-Scenario Deepfake Detection framework (GM-DF) is proposed to serve multiple real-world scenarios by a unified model. First, we propose a hybrid expert modeling approach for domain-specific real/forgery feature extraction. Besides, as for the commonality representation, we use CLIP to extract the common features for better aligning visual and textual features across domains. Meanwhile, we introduce a masked image reconstruction mechanism to force models to capture rich forged details. Finally, we supervise the models via a domain-aware meta-learning strategy to further enhance their generalization capacities. Specifically, we design a novel domain alignment loss to strongly align the distributions of the meta-test domains and meta-train domains. Thus, the updated models are able to represent both specific and common real/forgery features across multiple datasets. In consideration of the lack of study of multi-dataset training, we establish a new benchmark leveraging multi-source data to fairly evaluate the models' generalization capacity on unseen scenarios. Both qualitative and quantitative experiments on five datasets conducted on traditional protocols as well as the proposed benchmark demonstrate the effectiveness of our approach.
7/1/2024
🔄
Diffusion Deepfake
Chaitali Bhattacharyya, Hanxiao Wang, Feng Zhang, Sungho Kim, Xiatian Zhu
0
0
Recent progress in generative AI, primarily through diffusion models, presents significant challenges for real-world deepfake detection. The increased realism in image details, diverse content, and widespread accessibility to the general public complicates the identification of these sophisticated deepfakes. Acknowledging the urgency to address the vulnerability of current deepfake detectors to this evolving threat, our paper introduces two extensive deepfake datasets generated by state-of-the-art diffusion models as other datasets are less diverse and low in quality. Our extensive experiments also showed that our dataset is more challenging compared to the other face deepfake datasets. Our strategic dataset creation not only challenge the deepfake detectors but also sets a new benchmark for more evaluation. Our comprehensive evaluation reveals the struggle of existing detection methods, often optimized for specific image domains and manipulations, to effectively adapt to the intricate nature of diffusion deepfakes, limiting their practical utility. To address this critical issue, we investigate the impact of enhancing training data diversity on representative detection methods. This involves expanding the diversity of both manipulation techniques and image domains. Our findings underscore that increasing training data diversity results in improved generalizability. Moreover, we propose a novel momentum difficulty boosting strategy to tackle the additional challenge posed by training data heterogeneity. This strategy dynamically assigns appropriate sample weights based on learning difficulty, enhancing the model's adaptability to both easy and challenging samples. Extensive experiments on both existing and newly proposed benchmarks demonstrate that our model optimization approach surpasses prior alternatives significantly.
4/3/2024

An Analysis of Recent Advances in Deepfake Image Detection in an Evolving Threat Landscape
Sifat Muhammad Abdullah, Aravind Cheruvu, Shravya Kanchi, Taejoong Chung, Peng Gao, Murtuza Jadliwala, Bimal Viswanath
0
0
Deepfake or synthetic images produced using deep generative models pose serious risks to online platforms. This has triggered several research efforts to accurately detect deepfake images, achieving excellent performance on publicly available deepfake datasets. In this work, we study 8 state-of-the-art detectors and argue that they are far from being ready for deployment due to two recent developments. First, the emergence of lightweight methods to customize large generative models, can enable an attacker to create many customized generators (to create deepfakes), thereby substantially increasing the threat surface. We show that existing defenses fail to generalize well to such emph{user-customized generative models} that are publicly available today. We discuss new machine learning approaches based on content-agnostic features, and ensemble modeling to improve generalization performance against user-customized models. Second, the emergence of textit{vision foundation models} -- machine learning models trained on broad data that can be easily adapted to several downstream tasks -- can be misused by attackers to craft adversarial deepfakes that can evade existing defenses. We propose a simple adversarial attack that leverages existing foundation models to craft adversarial samples textit{without adding any adversarial noise}, through careful semantic manipulation of the image content. We highlight the vulnerabilities of several defenses against our attack, and explore directions leveraging advanced foundation models and adversarial training to defend against this new threat.
4/26/2024
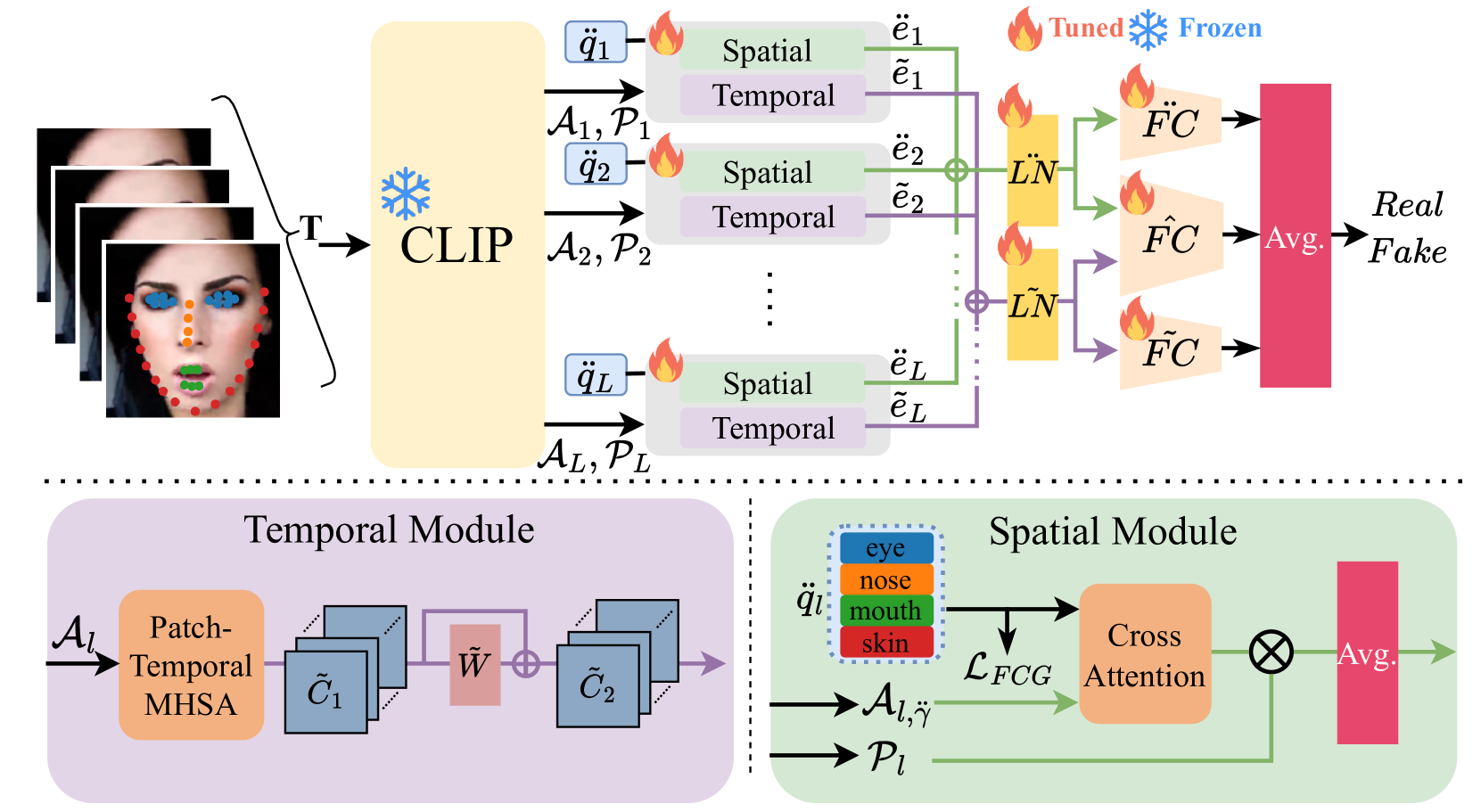
Towards More General Video-based Deepfake Detection through Facial Feature Guided Adaptation for Foundation Model
Yue-Hua Han, Tai-Ming Huang, Shu-Tzu Lo, Po-Han Huang, Kai-Lung Hua, Jun-Cheng Chen
0
0
With the rise of deep learning, generative models have enabled the creation of highly realistic synthetic images, presenting challenges due to their potential misuse. While research in Deepfake detection has grown rapidly in response, many detection methods struggle with unseen Deepfakes generated by new synthesis techniques. To address this generalisation challenge, we propose a novel Deepfake detection approach by adapting the Foundation Models with rich information encoded inside, specifically using the image encoder from CLIP which has demonstrated strong zero-shot capability for downstream tasks. Inspired by the recent advances of parameter efficient fine-tuning, we propose a novel side-network-based decoder to extract spatial and temporal cues from the given video clip, with the promotion of the Facial Component Guidance (FCG) to encourage the spatial feature to include features of key facial parts for more robust and general Deepfake detection. Through extensive cross-dataset evaluations, our approach exhibits superior effectiveness in identifying unseen Deepfake samples, achieving notable performance improvement even with limited training samples and manipulation types. Our model secures an average performance enhancement of 0.9% AUROC in cross-dataset assessments comparing with state-of-the-art methods, especially a significant lead of achieving 4.4% improvement on the challenging DFDC dataset.
6/6/2024