G3DR: Generative 3D Reconstruction in ImageNet
2403.00939
0
0

Abstract
We introduce a novel 3D generative method, Generative 3D Reconstruction (G3DR) in ImageNet, capable of generating diverse and high-quality 3D objects from single images, addressing the limitations of existing methods. At the heart of our framework is a novel depth regularization technique that enables the generation of scenes with high-geometric fidelity. G3DR also leverages a pretrained language-vision model, such as CLIP, to enable reconstruction in novel views and improve the visual realism of generations. Additionally, G3DR designs a simple but effective sampling procedure to further improve the quality of generations. G3DR offers diverse and efficient 3D asset generation based on class or text conditioning. Despite its simplicity, G3DR is able to beat state-of-theart methods, improving over them by up to 22% in perceptual metrics and 90% in geometry scores, while needing only half of the training time. Code is available at https://github.com/preddy5/G3DR
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents G3DR, a method for generating 3D reconstructions of objects from 2D images in the ImageNet dataset.
- The authors develop a generative model that can create 3D mesh representations of objects based on their 2D appearance.
- Experiments show that G3DR can produce high-quality 3D reconstructions for a wide range of common objects.
Plain English Explanation
Imagine you have a collection of 2D photos of various objects, like a chair, a car, or a lamp. Wouldn't it be great if you could take those flat images and turn them into 3D models that you could rotate and examine from all angles? That's exactly what the researchers behind G3DR have accomplished.
G3DR is a new machine learning technique that can take a 2D image and generate a 3D mesh representation of the object depicted. This allows you to create 3D computer models of real-world objects without having to scan or photograph them from multiple angles. The model learns to infer the 3D structure of an object just from analyzing its 2D appearance.
The researchers trained G3DR on a massive database of 2D images called ImageNet, which contains millions of pictures of all kinds of everyday objects. By studying these 2D images and their corresponding 3D models, the algorithm learned to generalize and generate convincing 3D reconstructions for new 2D inputs it hasn't seen before.
The key innovation of G3DR is that it can produce these 3D models in a fully automated way, without requiring any manual 3D modeling or labeling of the training data. This makes it a powerful tool for tasks like 3D content creation, virtual reality, and e-commerce, where 3D models of real-world objects are increasingly valuable.
Technical Explanation
The G3DR model is built on a generative adversarial network (GAN) architecture. It consists of a generator network that takes a 2D input image and outputs a 3D mesh representation of the depicted object, and a discriminator network that evaluates the realism of the generated 3D output.
During training, the generator learns to create 3D meshes that can trick the discriminator into thinking they are real, ground-truth 3D models. This adversarial training process allows the generator to progressively improve its 3D reconstruction capabilities.
The authors leverage a novel differentiable renderer module that enables the 3D mesh outputs to be directly compared to 2D images for training. This allows the entire pipeline to be trained end-to-end using standard backpropagation techniques.
Experiments on the ImageNet dataset show that G3DR can generate high-quality 3D reconstructions for a diverse set of object categories, outperforming prior 3D reconstruction methods. Qualitative results demonstrate the models' ability to capture fine-grained 3D details from 2D inputs.
Critical Analysis
The paper presents a compelling approach for 3D reconstruction from single 2D images. However, it is important to note that the quality of the generated 3D models is still limited compared to 3D scans or manual modeling. The reconstructions may not be accurate enough for certain high-precision applications.
Additionally, the training dataset, ImageNet, contains a broad but finite set of object categories. It is unclear how well G3DR would generalize to novel or unusual object types not present in the training data. Further research may be needed to enhance the model's flexibility and generalization capabilities.
That said, the core contribution of automatically generating 3D models from 2D images is a significant advance. As 3D content becomes increasingly important in domains like virtual reality, e-commerce, and digital entertainment, tools like G3DR could have a transformative impact by making 3D creation more accessible and efficient.
Conclusion
The G3DR paper presents an innovative approach for generating 3D reconstructions of objects from 2D images. By leveraging a generative adversarial network architecture, the model can produce high-quality 3D mesh representations in a fully automated manner.
This work has the potential to streamline 3D content creation workflows and enable new applications that rely on 3D models of real-world objects. While the current quality has room for improvement, the core idea of inferring 3D structure from 2D appearances is a significant step forward in computer vision and graphics.
As 3D modeling and reconstruction continue to evolve, techniques like G3DR may become increasingly valuable for a wide range of industries and use cases. This research demonstrates the power of machine learning to expand our capabilities in digital 3D representation and modeling.
Related Papers
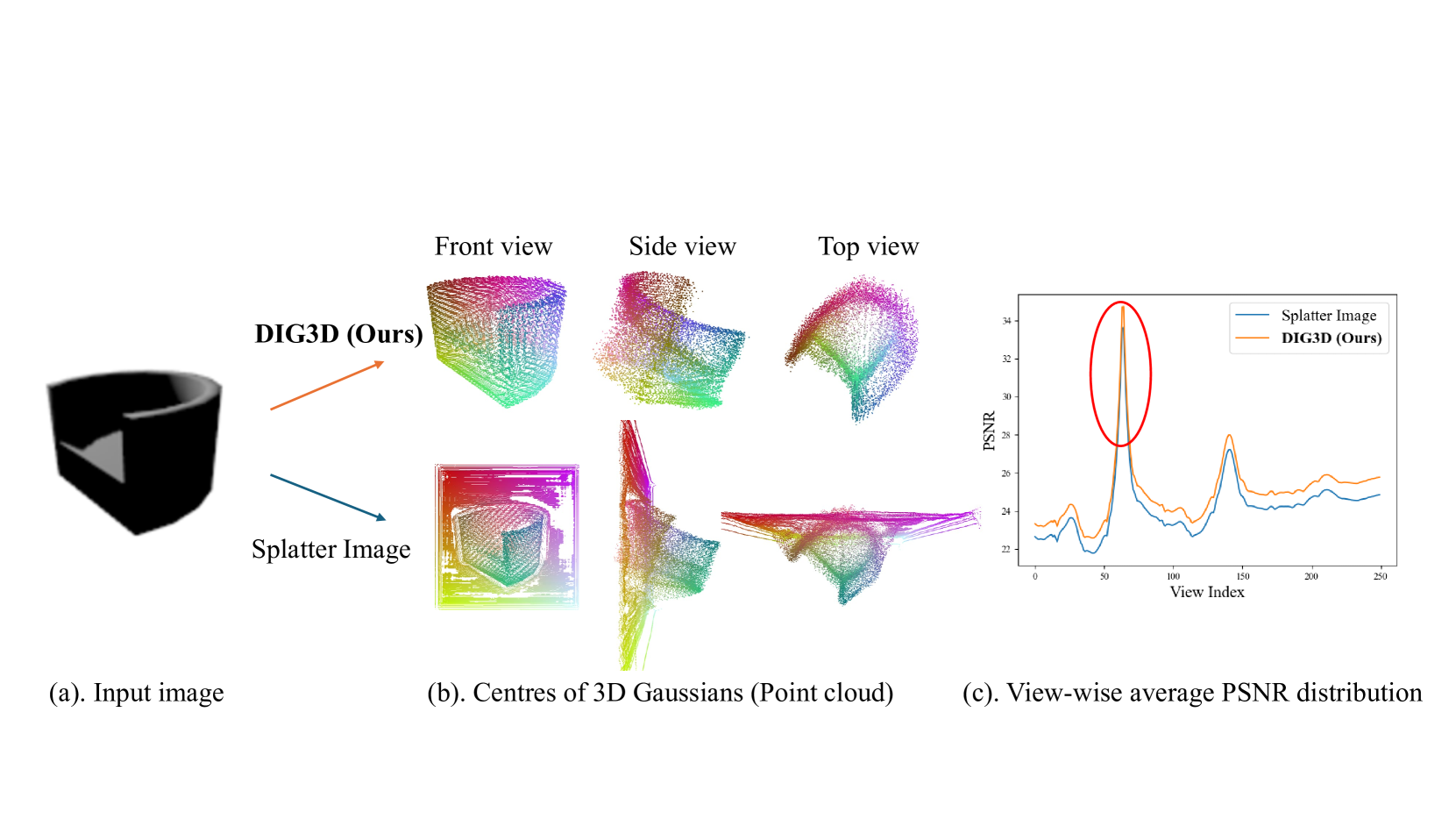
DIG3D: Marrying Gaussian Splatting with Deformable Transformer for Single Image 3D Reconstruction
Jiamin Wu, Kenkun Liu, Han Gao, Xiaoke Jiang, Lei Zhang
0
0
In this paper, we study the problem of 3D reconstruction from a single-view RGB image and propose a novel approach called DIG3D for 3D object reconstruction and novel view synthesis. Our method utilizes an encoder-decoder framework which generates 3D Gaussians in decoder with the guidance of depth-aware image features from encoder. In particular, we introduce the use of deformable transformer, allowing efficient and effective decoding through 3D reference point and multi-layer refinement adaptations. By harnessing the benefits of 3D Gaussians, our approach offers an efficient and accurate solution for 3D reconstruction from single-view images. We evaluate our method on the ShapeNet SRN dataset, getting PSNR of 24.21 and 24.98 in car and chair dataset, respectively. The result outperforming the recent method by around 2.25%, demonstrating the effectiveness of our method in achieving superior results.
4/26/2024

6Img-to-3D: Few-Image Large-Scale Outdoor Driving Scene Reconstruction
Th'eo Gieruc, Marius Kastingschafer, Sebastian Bernhard, Mathieu Salzmann
0
0
Current 3D reconstruction techniques struggle to infer unbounded scenes from a few images faithfully. Specifically, existing methods have high computational demands, require detailed pose information, and cannot reconstruct occluded regions reliably. We introduce 6Img-to-3D, an efficient, scalable transformer-based encoder-renderer method for single-shot image to 3D reconstruction. Our method outputs a 3D-consistent parameterized triplane from only six outward-facing input images for large-scale, unbounded outdoor driving scenarios. We take a step towards resolving existing shortcomings by combining contracted custom cross- and self-attention mechanisms for triplane parameterization, differentiable volume rendering, scene contraction, and image feature projection. We showcase that six surround-view vehicle images from a single timestamp without global pose information are enough to reconstruct 360$^{circ}$ scenes during inference time, taking 395 ms. Our method allows, for example, rendering third-person images and birds-eye views. Our code is available at https://github.com/continental/6Img-to-3D, and more examples can be found at our website here https://6Img-to-3D.GitHub.io/.
4/19/2024
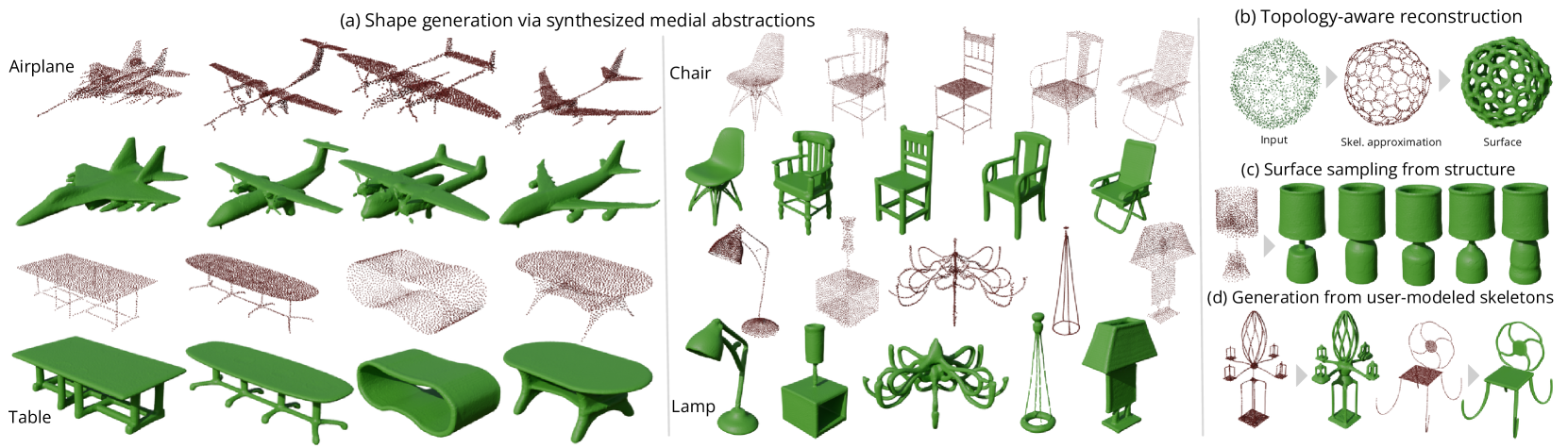
GEM3D: GEnerative Medial Abstractions for 3D Shape Synthesis
Dmitry Petrov, Pradyumn Goyal, Vikas Thamizharasan, Vladimir G. Kim, Matheus Gadelha, Melinos Averkiou, Siddhartha Chaudhuri, Evangelos Kalogerakis
0
0
We introduce GEM3D -- a new deep, topology-aware generative model of 3D shapes. The key ingredient of our method is a neural skeleton-based representation encoding information on both shape topology and geometry. Through a denoising diffusion probabilistic model, our method first generates skeleton-based representations following the Medial Axis Transform (MAT), then generates surfaces through a skeleton-driven neural implicit formulation. The neural implicit takes into account the topological and geometric information stored in the generated skeleton representations to yield surfaces that are more topologically and geometrically accurate compared to previous neural field formulations. We discuss applications of our method in shape synthesis and point cloud reconstruction tasks, and evaluate our method both qualitatively and quantitatively. We demonstrate significantly more faithful surface reconstruction and diverse shape generation results compared to the state-of-the-art, also involving challenging scenarios of reconstructing and synthesizing structurally complex, high-genus shape surfaces from Thingi10K and ShapeNet.
4/12/2024

Interactive3D: Create What You Want by Interactive 3D Generation
Shaocong Dong, Lihe Ding, Zhanpeng Huang, Zibin Wang, Tianfan Xue, Dan Xu
0
0
3D object generation has undergone significant advancements, yielding high-quality results. However, fall short of achieving precise user control, often yielding results that do not align with user expectations, thus limiting their applicability. User-envisioning 3D object generation faces significant challenges in realizing its concepts using current generative models due to limited interaction capabilities. Existing methods mainly offer two approaches: (i) interpreting textual instructions with constrained controllability, or (ii) reconstructing 3D objects from 2D images. Both of them limit customization to the confines of the 2D reference and potentially introduce undesirable artifacts during the 3D lifting process, restricting the scope for direct and versatile 3D modifications. In this work, we introduce Interactive3D, an innovative framework for interactive 3D generation that grants users precise control over the generative process through extensive 3D interaction capabilities. Interactive3D is constructed in two cascading stages, utilizing distinct 3D representations. The first stage employs Gaussian Splatting for direct user interaction, allowing modifications and guidance of the generative direction at any intermediate step through (i) Adding and Removing components, (ii) Deformable and Rigid Dragging, (iii) Geometric Transformations, and (iv) Semantic Editing. Subsequently, the Gaussian splats are transformed into InstantNGP. We introduce a novel (v) Interactive Hash Refinement module to further add details and extract the geometry in the second stage. Our experiments demonstrate that Interactive3D markedly improves the controllability and quality of 3D generation. Our project webpage is available at url{https://interactive-3d.github.io/}.
4/26/2024