The Death of Feature Engineering? BERT with Linguistic Features on SQuAD 2.0
2404.03184
0
0

Abstract
Machine reading comprehension is an essential natural language processing task, which takes into a pair of context and query and predicts the corresponding answer to query. In this project, we developed an end-to-end question answering model incorporating BERT and additional linguistic features. We conclude that the BERT base model will be improved by incorporating the features. The EM score and F1 score are improved 2.17 and 2.14 compared with BERT(base). Our best single model reaches EM score 76.55 and F1 score 79.97 in the hidden test set. Our error analysis also shows that the linguistic architecture can help model understand the context better in that it can locate answers that BERT only model predicted No Answer wrongly.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper explores using BERT, a powerful language model, along with additional linguistic features to improve performance on the SQuAD 2.0 question-answering dataset.
- The authors investigate whether feature engineering is still necessary in the age of large language models, or if the models can learn the relevant features on their own.
- The results show that incorporating linguistic features like part-of-speech tags and named entities can provide a small but meaningful boost in performance over using BERT alone.
Plain English Explanation
The paper looks at a common task in natural language processing called question answering. The goal is to build a system that can read a passage of text and then answer questions about the content. This is a challenging task because it requires understanding the meaning of the text, not just identifying keywords.
The researchers used a powerful language model called BERT as the foundation for their question-answering system. BERT is trained on a huge amount of text data and can understand the semantics and context of language very well.
However, the researchers wanted to see if they could improve BERT's performance even further by adding additional "linguistic features" to the system. Linguistic features are things like parts of speech (nouns, verbs, etc.), named entities (people, places, organizations), and other grammar-related information. The idea is that this extra linguistic knowledge could help the model better comprehend the text and answer questions more accurately.
The results showed that incorporating these linguistic features did provide a small but significant boost in question-answering performance, compared to using BERT alone. This suggests that while large language models like BERT are extremely powerful, there may still be value in carefully designing and incorporating additional domain-specific features, at least for certain tasks.
Technical Explanation
The paper focuses on the SQuAD 2.0 question-answering dataset, which contains passages of text along with questions about the content. The goal is to build a model that can read the passage and then select the correct answer span from the text.
The authors use BERT as the foundation of their model, taking advantage of BERT's strong language understanding capabilities. They then experiment with adding various linguistic features on top of BERT, including part-of-speech tags, named entities, and dependency parse information. These features are concatenated with the BERT embeddings and fed into a question-answering prediction layer.
The researchers compare the performance of the BERT-only model against the BERT-plus-features model on the SQuAD 2.0 dev and test sets. The results show that incorporating the linguistic features leads to a statistically significant improvement in exact match and F1 score metrics, though the gains are relatively modest (around 1-2 points).
The authors also analyze how the different linguistic features contribute to the performance gain, finding that named entity recognition and part-of-speech tagging tend to be the most helpful. They hypothesize that these features provide the model with additional semantic and grammatical knowledge that complements BERT's natural language understanding capabilities.
Critical Analysis
The paper provides a solid empirical investigation into the value of feature engineering in the era of powerful language models like BERT. The results suggest that while BERT alone is an extremely capable question-answering system, there is still room for improvement by incorporating targeted linguistic features.
However, the gains observed are relatively small, raising the question of whether the additional complexity and engineering effort is worth the modest performance boost. The authors acknowledge this limitation and suggest that the value of feature engineering may depend on the specific task and dataset.
Additionally, the paper does not explore the generalization of these findings beyond the SQuAD 2.0 dataset. It would be helpful to see if the benefits of linguistic features hold true on other question-answering benchmarks or natural language understanding tasks.
Finally, the paper does not delve into potential downsides or risks of over-engineering models with too many features. There could be concerns around model interpretability, overfitting, or increased computational costs that should be considered.
Overall, the paper makes a valuable contribution to the ongoing debate about the role of feature engineering in the age of large language models. The results suggest that a balanced approach, combining powerful pre-trained models with carefully selected task-specific features, may be a fruitful direction for future research.
Conclusion
This paper explores the interplay between powerful language models like BERT and the potential value of incorporating additional linguistic features for question-answering tasks. The results indicate that while BERT alone is a highly capable system, adding features like part-of-speech tags and named entities can provide a modest but meaningful performance boost.
These findings suggest that feature engineering may not be entirely obsolete, even in the era of large, pre-trained language models. There may still be value in carefully designing and incorporating domain-specific features to complement the language understanding capabilities of these models.
At the same time, the relatively small gains observed in this paper highlight the need to carefully weigh the benefits against the added complexity and engineering effort required. As the field of natural language processing continues to advance, striking the right balance between powerful models and targeted feature engineering will be an important area of ongoing research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Estimating the Causal Effects of Natural Logic Features in Transformer-Based NLI Models
Julia Rozanova, Marco Valentino, Andr'e Freitas
0
0
Rigorous evaluation of the causal effects of semantic features on language model predictions can be hard to achieve for natural language reasoning problems. However, this is such a desirable form of analysis from both an interpretability and model evaluation perspective, that it is valuable to investigate specific patterns of reasoning with enough structure and regularity to identify and quantify systematic reasoning failures in widely-used models. In this vein, we pick a portion of the NLI task for which an explicit causal diagram can be systematically constructed: the case where across two sentences (the premise and hypothesis), two related words/terms occur in a shared context. In this work, we apply causal effect estimation strategies to measure the effect of context interventions (whose effect on the entailment label is mediated by the semantic monotonicity characteristic) and interventions on the inserted word-pair (whose effect on the entailment label is mediated by the relation between these words). Extending related work on causal analysis of NLP models in different settings, we perform an extensive interventional study on the NLI task to investigate robustness to irrelevant changes and sensitivity to impactful changes of Transformers. The results strongly bolster the fact that similar benchmark accuracy scores may be observed for models that exhibit very different behaviour. Moreover, our methodology reinforces previously suspected biases from a causal perspective, including biases in favour of upward-monotone contexts and ignoring the effects of negation markers.
4/4/2024
Empowering Interdisciplinary Research with BERT-Based Models: An Approach Through SciBERT-CNN with Topic Modeling
Darya Likhareva, Hamsini Sankaran, Sivakumar Thiyagarajan
0
0
Researchers must stay current in their fields by regularly reviewing academic literature, a task complicated by the daily publication of thousands of papers. Traditional multi-label text classification methods often ignore semantic relationships and fail to address the inherent class imbalances. This paper introduces a novel approach using the SciBERT model and CNNs to systematically categorize academic abstracts from the Elsevier OA CC-BY corpus. We use a multi-segment input strategy that processes abstracts, body text, titles, and keywords obtained via BERT topic modeling through SciBERT. Here, the [CLS] token embeddings capture the contextual representation of each segment, concatenated and processed through a CNN. The CNN uses convolution and pooling to enhance feature extraction and reduce dimensionality, optimizing the data for classification. Additionally, we incorporate class weights based on label frequency to address the class imbalance, significantly improving the classification F1 score and enhancing text classification systems and literature review efficiency.
4/24/2024
🚀
Enhancing Embedding Performance through Large Language Model-based Text Enrichment and Rewriting
Nicholas Harris, Anand Butani, Syed Hashmy
0
0
Embedding models are crucial for various natural language processing tasks but can be limited by factors such as limited vocabulary, lack of context, and grammatical errors. This paper proposes a novel approach to improve embedding performance by leveraging large language models (LLMs) to enrich and rewrite input text before the embedding process. By utilizing ChatGPT 3.5 to provide additional context, correct inaccuracies, and incorporate metadata, the proposed method aims to enhance the utility and accuracy of embedding models. The effectiveness of this approach is evaluated on three datasets: Banking77Classification, TwitterSemEval 2015, and Amazon Counter-factual Classification. Results demonstrate significant improvements over the baseline model on the TwitterSemEval 2015 dataset, with the best-performing prompt achieving a score of 85.34 compared to the previous best of 81.52 on the Massive Text Embedding Benchmark (MTEB) Leaderboard. However, performance on the other two datasets was less impressive, highlighting the importance of considering domain-specific characteristics. The findings suggest that LLM-based text enrichment has shown promising results to improve embedding performance, particularly in certain domains. Hence, numerous limitations in the process of embedding can be avoided.
4/19/2024
Enriched BERT Embeddings for Scholarly Publication Classification
Benjamin Wolff, Eva Seidlmayer, Konrad U. Forstner
0
0
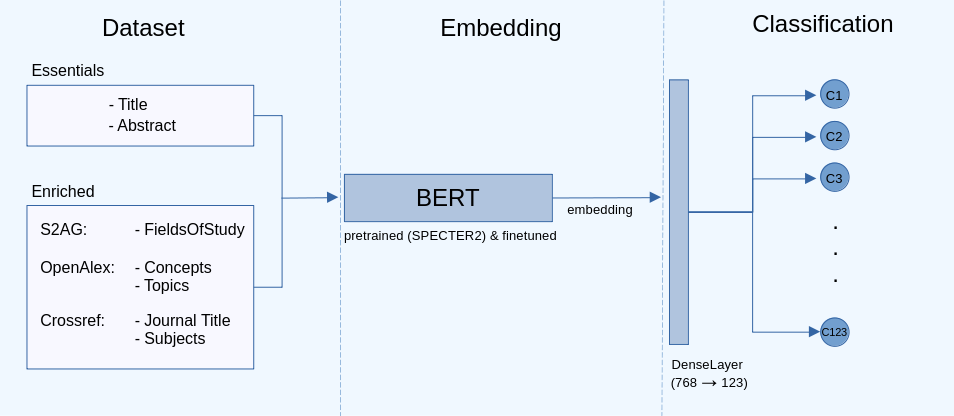
With the rapid expansion of academic literature and the proliferation of preprints, researchers face growing challenges in manually organizing and labeling large volumes of articles. The NSLP 2024 FoRC Shared Task I addresses this challenge organized as a competition. The goal is to develop a classifier capable of predicting one of 123 predefined classes from the Open Research Knowledge Graph (ORKG) taxonomy of research fields for a given article.This paper presents our results. Initially, we enrich the dataset (containing English scholarly articles sourced from ORKG and arXiv), then leverage different pre-trained language Models (PLMs), specifically BERT, and explore their efficacy in transfer learning for this downstream task. Our experiments encompass feature-based and fine-tuned transfer learning approaches using diverse PLMs, optimized for scientific tasks, including SciBERT, SciNCL, and SPECTER2. We conduct hyperparameter tuning and investigate the impact of data augmentation from bibliographic databases such as OpenAlex, Semantic Scholar, and Crossref. Our results demonstrate that fine-tuning pre-trained models substantially enhances classification performance, with SPECTER2 emerging as the most accurate model. Moreover, enriching the dataset with additional metadata improves classification outcomes significantly, especially when integrating information from S2AG, OpenAlex and Crossref. Our best-performing approach achieves a weighted F1-score of 0.7415. Overall, our study contributes to the advancement of reliable automated systems for scholarly publication categorization, offering a potential solution to the laborious manual curation process, thereby facilitating researchers in efficiently locating relevant resources.
5/8/2024