Enhancing Embedding Performance through Large Language Model-based Text Enrichment and Rewriting
2404.12283
0
0
🚀
Abstract
Embedding models are crucial for various natural language processing tasks but can be limited by factors such as limited vocabulary, lack of context, and grammatical errors. This paper proposes a novel approach to improve embedding performance by leveraging large language models (LLMs) to enrich and rewrite input text before the embedding process. By utilizing ChatGPT 3.5 to provide additional context, correct inaccuracies, and incorporate metadata, the proposed method aims to enhance the utility and accuracy of embedding models. The effectiveness of this approach is evaluated on three datasets: Banking77Classification, TwitterSemEval 2015, and Amazon Counter-factual Classification. Results demonstrate significant improvements over the baseline model on the TwitterSemEval 2015 dataset, with the best-performing prompt achieving a score of 85.34 compared to the previous best of 81.52 on the Massive Text Embedding Benchmark (MTEB) Leaderboard. However, performance on the other two datasets was less impressive, highlighting the importance of considering domain-specific characteristics. The findings suggest that LLM-based text enrichment has shown promising results to improve embedding performance, particularly in certain domains. Hence, numerous limitations in the process of embedding can be avoided.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores how to enhance the performance of text embedding models using large language models (LLMs) for text enrichment and rewriting.
- The researchers propose methods to leverage the powerful language understanding capabilities of LLMs to improve the quality of text embeddings, which are fundamental for many natural language processing (NLP) tasks.
- The paper presents several techniques, such as LLM-augmented Retrieval, Simple Techniques for Enhancing Sentence Embeddings, LTNER: Large Language Model Tagging Named Entity, and LongEmbed: Extending Embedding Models for Long-Context Retrieval, to demonstrate the benefits of LLM-based text enrichment and rewriting.
Plain English Explanation
The researchers in this paper are trying to find ways to make text embedding models work better. Text embedding models are a fundamental building block for many natural language processing (NLP) tasks, like search, recommendation, and text analysis.
The key idea is to use powerful large language models (LLMs), like GPT-3 or BERT, to enrich and rewrite the input text before feeding it into the embedding model. LLMs have amazing language understanding capabilities, so the researchers hypothesize that using them to enhance the text can lead to better embeddings.
For example, the paper describes a technique where the LLM is used to add more context and detail to short sentences, helping the embedding model better capture the meaning. In another approach, the LLM rewrites the text to be more concise and coherent, which can also improve the embeddings.
The key benefit of these LLM-based techniques is that they can boost the performance of text embedding models on a variety of downstream NLP tasks, without requiring changes to the embedding model architecture itself. This makes it a practical and flexible way to get more mileage out of existing embedding models.
Technical Explanation
The paper proposes several techniques for leveraging LLMs to enhance text embeddings:
-
LLM-augmented Retrieval: This method uses an LLM to generate additional relevant text to supplement the input, improving the quality of text embeddings for retrieval tasks.
-
Simple Techniques for Enhancing Sentence Embeddings: The researchers explore simple techniques like prompt-based rewriting and contrastive learning to leverage LLMs and improve sentence embeddings.
-
LTNER: Large Language Model Tagging Named Entity: This approach uses an LLM to identify and enrich named entities in the input text, which can help the embedding model better capture semantic relationships.
-
LongEmbed: Extending Embedding Models for Long-Context Retrieval: The authors introduce a method to adapt embedding models to handle long-form text by combining LLM-based text generation and retrieval-specific training.
In each case, the paper evaluates the proposed techniques on various benchmark datasets and finds consistent improvements in embedding performance compared to using the base embedding models alone.
Critical Analysis
The paper presents a compelling approach to enhancing text embeddings using LLMs, and the results demonstrate the potential benefits of this strategy. However, some potential limitations and areas for further research include:
-
Computational Complexity: Integrating LLMs into the embedding pipeline may increase the computational and memory requirements, which could be a concern for real-world deployment, especially on resource-constrained devices.
-
Robustness and Generalization: The paper focuses on evaluating the techniques on specific benchmark datasets. Further research is needed to assess the robustness and generalization of these methods across a wider range of domains and tasks.
-
Interpretability and Explainability: As with many LLM-based approaches, the inner workings of the techniques can be opaque, making it challenging to understand the specific mechanisms driving the performance improvements. Exploring ways to improve the interpretability of these methods could be valuable.
-
Ethical Considerations: The use of powerful LLMs raises potential ethical concerns, such as the generation of biased or inappropriate text. Careful monitoring and mitigation strategies may be necessary when deploying these techniques in real-world applications.
Overall, the paper presents a promising direction for enhancing text embeddings, and the proposed techniques warrant further investigation and refinement to address the potential limitations and expand their practical applicability.
Conclusion
This paper introduces several novel methods for leveraging large language models (LLMs) to improve the performance of text embedding models. By using LLMs to enrich and rewrite input text, the researchers demonstrate consistent improvements in embedding quality across a variety of benchmark tasks.
The key significance of this work is that it provides a flexible and practical approach to boosting the performance of text embeddings without requiring changes to the underlying embedding model architecture. This makes the techniques easily applicable to existing embedding models, enabling organizations to get more value out of their current NLP infrastructure.
As the field of natural language processing continues to advance, techniques like those presented in this paper will play an important role in unlocking the full potential of text embedding models and driving progress in a wide range of real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
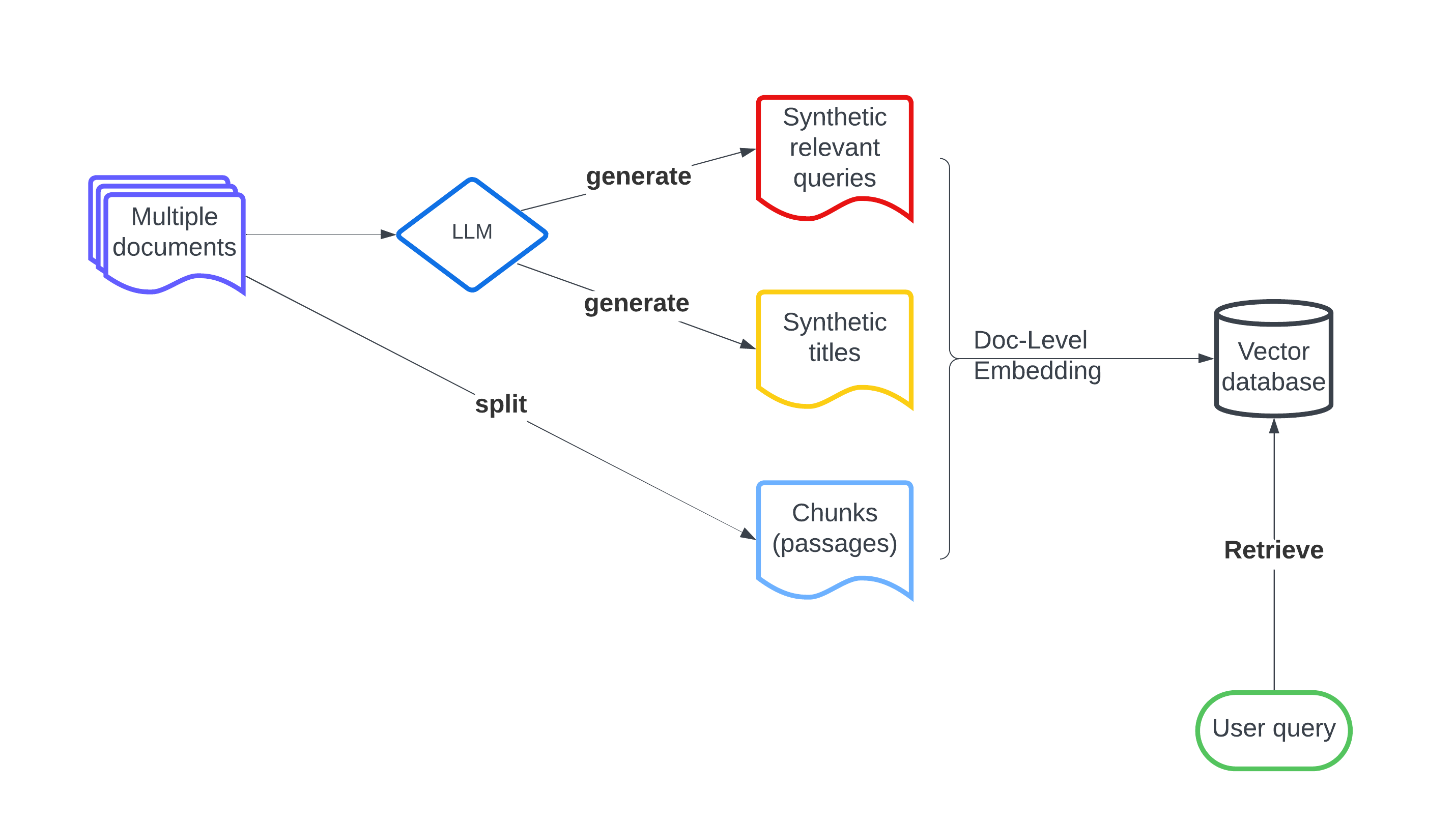
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
Mingrui Wu, Sheng Cao
0
0
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
4/10/2024
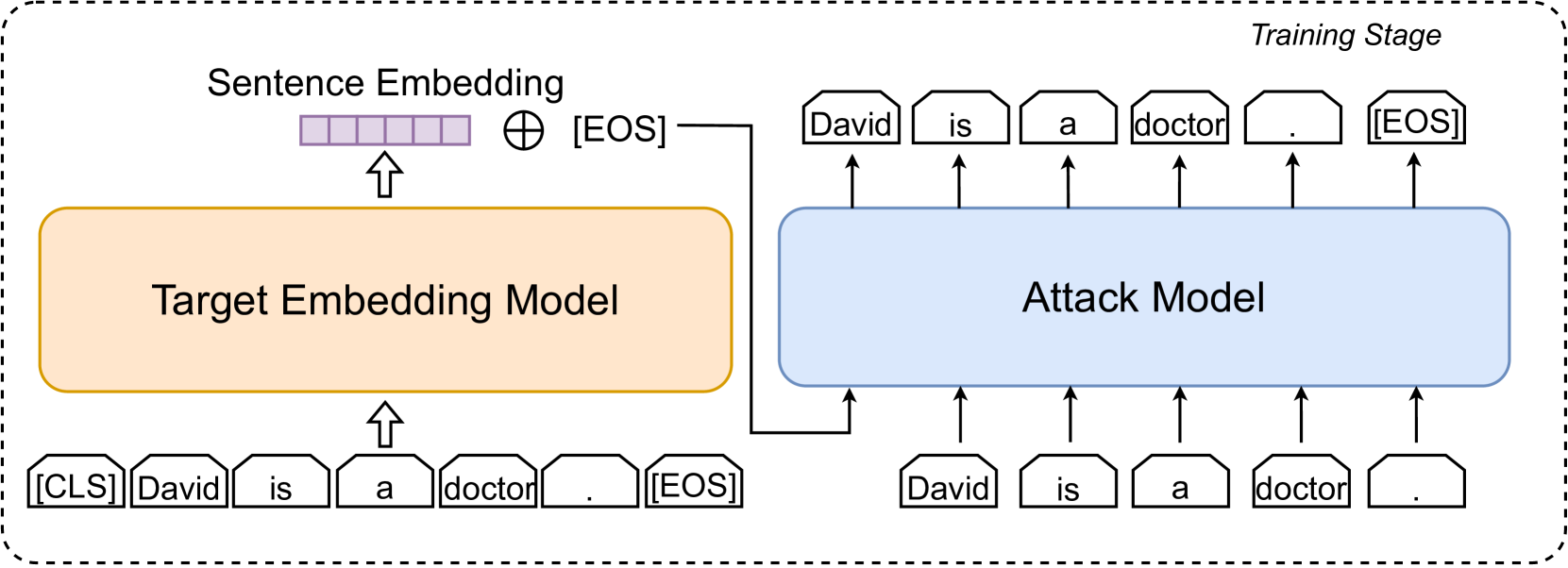
Understanding Privacy Risks of Embeddings Induced by Large Language Models
Zhihao Zhu, Ninglu Shao, Defu Lian, Chenwang Wu, Zheng Liu, Yi Yang, Enhong Chen
0
0
Large language models (LLMs) show early signs of artificial general intelligence but struggle with hallucinations. One promising solution to mitigate these hallucinations is to store external knowledge as embeddings, aiding LLMs in retrieval-augmented generation. However, such a solution risks compromising privacy, as recent studies experimentally showed that the original text can be partially reconstructed from text embeddings by pre-trained language models. The significant advantage of LLMs over traditional pre-trained models may exacerbate these concerns. To this end, we investigate the effectiveness of reconstructing original knowledge and predicting entity attributes from these embeddings when LLMs are employed. Empirical findings indicate that LLMs significantly improve the accuracy of two evaluated tasks over those from pre-trained models, regardless of whether the texts are in-distribution or out-of-distribution. This underscores a heightened potential for LLMs to jeopardize user privacy, highlighting the negative consequences of their widespread use. We further discuss preliminary strategies to mitigate this risk.
4/26/2024
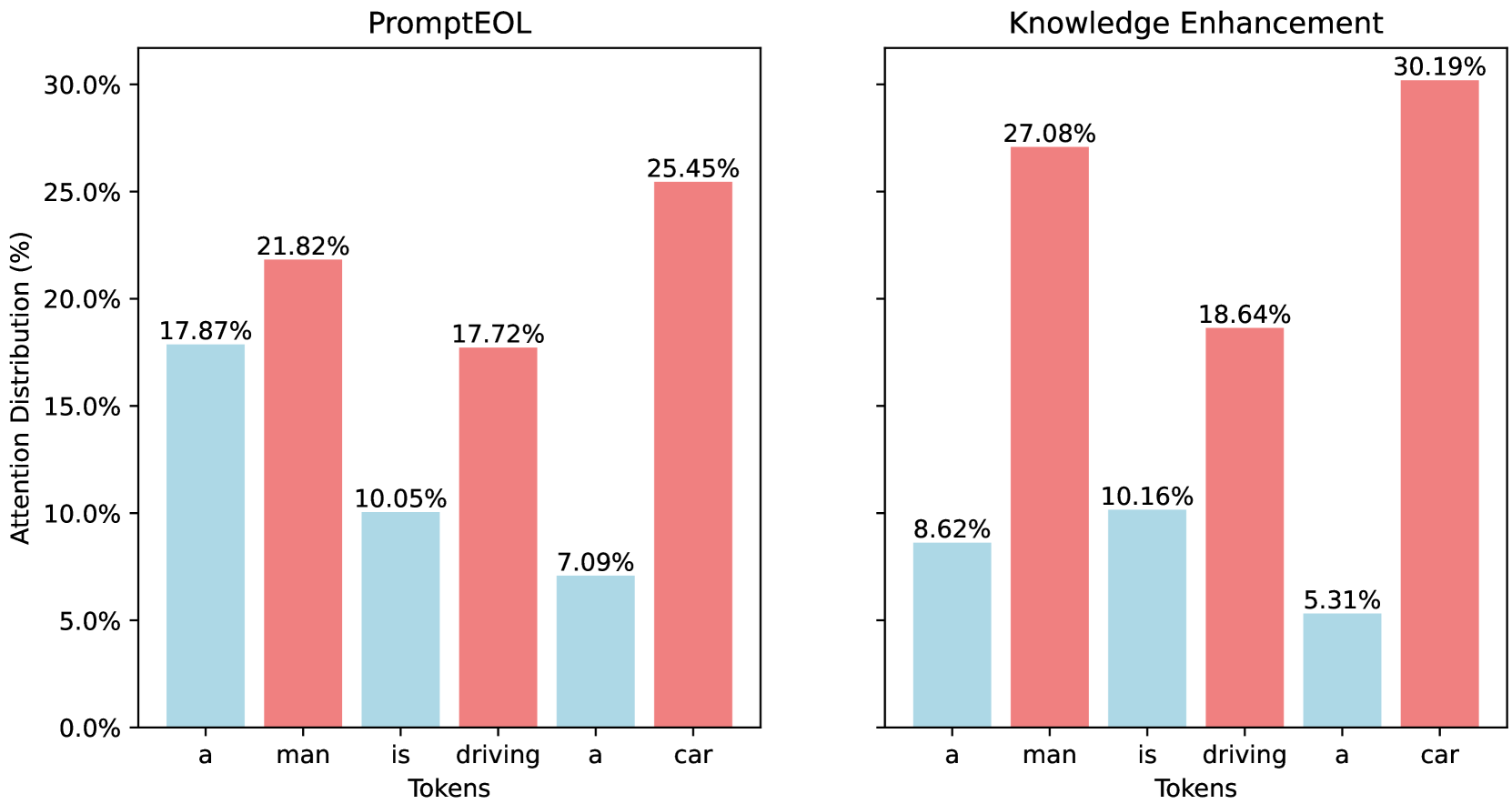
Simple Techniques for Enhancing Sentence Embeddings in Generative Language Models
Bowen Zhang, Kehua Chang, Chunping Li
0
0
Sentence Embedding stands as a fundamental task within the realm of Natural Language Processing, finding extensive application in search engines, expert systems, and question-and-answer platforms. With the continuous evolution of large language models such as LLaMA and Mistral, research on sentence embedding has recently achieved notable breakthroughs. However, these advancements mainly pertain to fine-tuning scenarios, leaving explorations into computationally efficient direct inference methods for sentence representation in a nascent stage. This paper endeavors to bridge this research gap. Through comprehensive experimentation, we challenge the widely held belief in the necessity of an Explicit One-word Limitation for deriving sentence embeddings from Pre-trained Language Models (PLMs). We demonstrate that this approach, while beneficial for generative models under direct inference scenario, is not imperative for discriminative models or the fine-tuning of generative PLMs. This discovery sheds new light on the design of manual templates in future studies. Building upon this insight, we propose two innovative prompt engineering techniques capable of further enhancing the expressive power of PLMs' raw embeddings: Pretended Chain of Thought and Knowledge Enhancement. We confirm their effectiveness across various PLM types and provide a detailed exploration of the underlying factors contributing to their success.
5/16/2024
💬
Improving the Capabilities of Large Language Model Based Marketing Analytics Copilots With Semantic Search And Fine-Tuning
Yilin Gao, Sai Kumar Arava, Yancheng Li, James W. Snyder Jr
0
0
Artificial intelligence (AI) is widely deployed to solve problems related to marketing attribution and budget optimization. However, AI models can be quite complex, and it can be difficult to understand model workings and insights without extensive implementation teams. In principle, recently developed large language models (LLMs), like GPT-4, can be deployed to provide marketing insights, reducing the time and effort required to make critical decisions. In practice, there are substantial challenges that need to be overcome to reliably use such models. We focus on domain-specific question-answering, SQL generation needed for data retrieval, and tabular analysis and show how a combination of semantic search, prompt engineering, and fine-tuning can be applied to dramatically improve the ability of LLMs to execute these tasks accurately. We compare both proprietary models, like GPT-4, and open-source models, like Llama-2-70b, as well as various embedding methods. These models are tested on sample use cases specific to marketing mix modeling and attribution.
4/23/2024