DecentNeRFs: Decentralized Neural Radiance Fields from Crowdsourced Images

0

Sign in to get full access
Introduction
The paper presents DecentNeRF, a framework for decentralized neural radiance fields (NeRFs) from crowd-sourced images. NeRFs offer an opportunity to process the massive amount of daily captured photos worldwide into immersive visual experiences. However, most of these personal images remain siloed, and learning NeRFs for billions of scenes at a global scale is computationally intractable in a centralized fashion.
The key insight is that global content in images is often static across users, while personal content is dynamic. DecentNeRF separates global and personal content, enabling the sharing of only the global scene-specific 3D representations across users. This distributes the NeRF training computation across users and minimizes the reconstruction of undesired personal content on the server.
The framework uses federated learning to learn the global radiance field across users, with a novel federation procedure that implicitly learns per-user scaling to maximize visual fidelity. Secure multi-party computation is used to prevent the server from accessing individual users' global radiance fields, further reducing the reconstruction of personal content.
Compared to existing decentralized approaches, DecentNeRF demonstrates high visual quality in the global content while requiring significantly lower compute (around 10,000 times less) than centralized approaches. The paper also provides an analysis of how the secure aggregation reduces the reconstruction of personal content on the server.
Related Work
The provided text summarizes an approach called DecentNeRF, which aims to generate 3D scene representations for novel-view synthesis from an extensive collection of unstructured images in a decentralized manner. Unlike previous centralized approaches, DecentNeRF distributes the training compute to user devices, allowing for scaling to billions of scenes without aggregating users' personal images.
The paper discusses the use of Federated Learning (FL) to train the 3D scene representations on user devices, where each client trains a local model and the server performs a weighted average of the models to obtain a global model. However, sharing the 3D representations directly could still lead to reconstruction of personal data. DecentNeRF instead models the local 3D scene representation as a combination of a global radiance field for scene-specific details and a personal radiance field for user-specific information.
To address the potential data reconstruction attacks in FL, the paper utilizes secure aggregation techniques based on secure multi-party computation (SMPC) to average the encrypted model updates from users, ensuring that only the final averaged weights are revealed to the server.
Key Insights
The paper proposes a decentralized approach to learn a 3D representation of a scene, such as a famous restaurant, using images captured by multiple users over time. This is a challenging problem because the learned representation must encode both the appearance and 3D structure of the scene while avoiding the exposure of personal content, such as users, their food, or credit cards, that may be present in the images.
The key insights enabling the proposed approach are:
-
Personal-Global Content Separation: The global, scene-specific content is 3D view-consistent across users, while the personal or transient content is not. The approach encodes the 3D appearance between personal and global multilayer perceptrons (MLPs), allowing for high-quality reconstruction of the global content over multiple rounds of federation.
-
Learned Federation: Naive federated averaging of the global MLP is suboptimal due to differences in users' data distributions. Instead, the approach learns aggregation weights over federation rounds for optimal reconstruction quality.
-
Secure Multi-Party Computation (SMPC): To prevent the server from accessing the individual users' global MLPs, which could reveal personal content, the approach uses SMPC aggregation, allowing the server to only access the averaged global MLP at each round.
The paper also discusses the overall compute and communication overheads of the decentralized approach compared to a centralized approach.
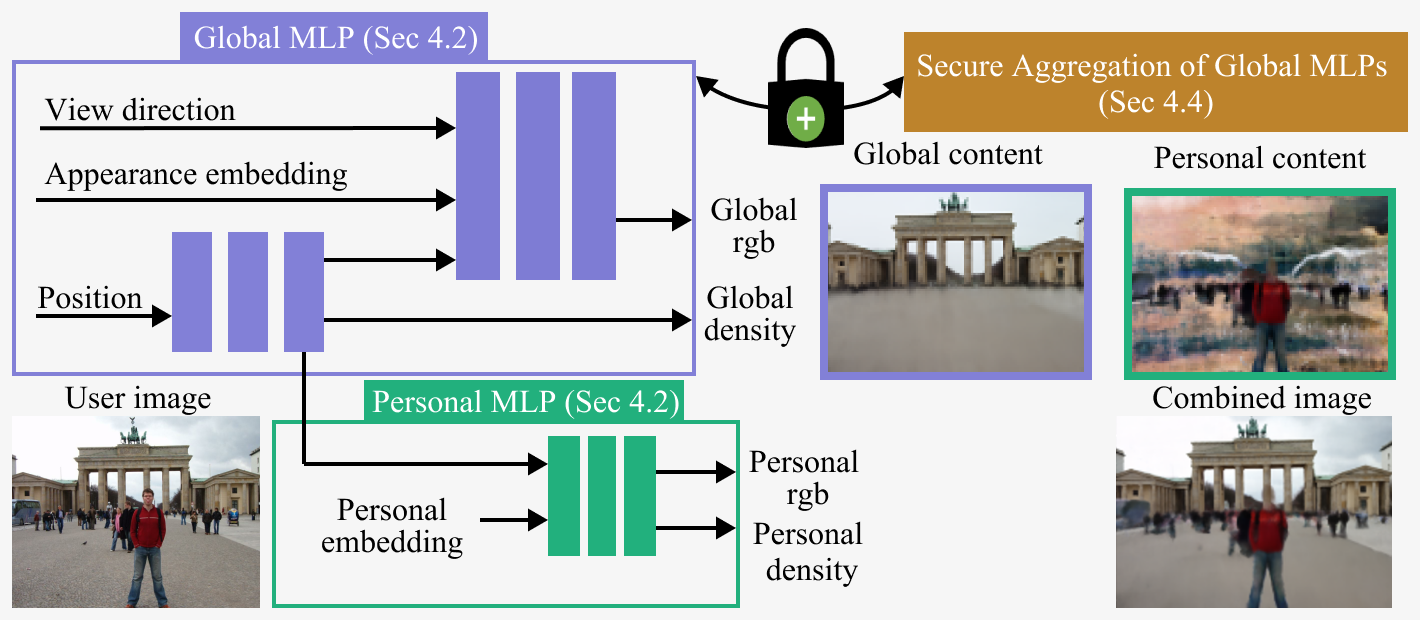
Our Approach
This section describes the key assumptions, insights, and algorithms that make up the DecentNeRF approach.
The key assumptions are: 1) Personal content is transient across users, 2) There is sufficient overlap in user views, and 3) Camera poses are known accurately.
The main insights are:
- Personal and global content can be separated into separate neural networks (MLPs) for each user. The global MLP captures shared content, while the personal MLP captures user-specific content.
- The weights of the global MLP can be learned in a decentralized way by having users send encrypted or masked versions of their global MLP weights. The server can then securely aggregate these to update the global MLP.
- The relative contribution (weighting) of each user's global MLP update can also be learned in a decentralized way, with users sending encrypted gradient updates that the server can use to update the user weighting factors.
The full DecentNeRF algorithm combines these ideas, with users sending encrypted global MLP weights, gradients, and weight update information to the server, which can then securely aggregate these to update the global MLP and user weighting factors over multiple rounds. This allows DecentNeRF to achieve high-quality 3D reconstructions while preserving user privacy.
Experimental details
The paper introduces two datasets for evaluating decentralized novel view synthesis:
-
Novel Blender Dataset: This is a synthetic dataset created by adding Lego people to the original Blender dataset. It contains 360-degree rotations with non-IID partitioning of 18 degrees in yaw angle rotation across 100 images distributed equally among 20 users, with each view containing 6 Lego people and one static person per user's view.
-
Phototourism Dataset: This real-world dataset evaluates decentralization on 3 scenes: Brandenburg Gate, Trevi Fountain, and Sacre Coeur. The setup has 20 clients with 10 images each at 2x downsampled resolution.
The paper compares the proposed DecentNeRF approach against a centralized approach (NeRF-W) and an existing decentralized approach (FedNeRF). It evaluates photorealism using PSNR, SSIM, and LPIPS, and decentralization using server FLOPs.
For the Phototourism dataset, the paper also evaluates personal content removal using a pre-trained object detector and reports the number of detected people.
The paper provides implementation details, including the use of a PyTorch Lightning implementation of NeRF-W, the SecAgg protocol for secure aggregation, and training/model specifics.
Results and Analysis
The paper presents an analysis of the Learned Federation approach for improving photorealism in federated neural radiance field (NeRF) reconstruction. The key findings are:
-
Ablation study on Learned Federation: The authors show that their Learned Federation approach outperforms the standard FedAvg aggregation strategy and FedNeRF in terms of PSNR on global content, especially in scenarios with varying degrees of occlusion across clients.
-
Photorealism and Decentralization analysis: The authors evaluate photorealism and decentralization on a novel Blender dataset and the real-world Phototourism dataset. The results demonstrate that the Learned Federation approach can achieve performance comparable to the best centralized approach (NeRFW) while requiring significantly less server compute.
-
Analysis of Personal Content Reconstruction: The paper shows that the Learned Federation approach is able to reduce the reconstruction of personal content by the server by up to 10 dB compared to FedNeRF. The authors further analyze the effect of the number of users and view overlap on the faithful rendering of personal content by the server.
Overall, the paper presents a comprehensive evaluation of the Learned Federation approach, highlighting its advantages in terms of photorealism, decentralization, and privacy preservation compared to existing federated NeRF techniques.
Discussion
DecentNeRF is a decentralized framework for learning Neural Radiance Fields (NeRFs). It decomposes multi-view images into personal and global visual content, then securely aggregates the global content across users while minimizing the reconstruction of personal content on the server. This framework enables large-scale crowd-sourced NeRFs, allowing for the capture of 3D scenes and live events in a decentralized manner.
The paper notes that while DecentNeRF was evaluated on phototourism scenes, it has the potential to enable decentralized NeRF approaches for a wide range of applications. The authors highlight that DecentNeRF's photorealism and decentralization advantages can be further enhanced by leveraging future advancements in NeRF architectures, training, and rendering.
The paper also discusses limitations, such as not demonstrating DecentNeRF on actual user mobile devices, and potential attacks on the secure multi-party computation (SMPC) protocols used to protect user privacy. The authors suggest incorporating stronger privacy guarantees and more efficient secure decentralization strategies as exciting future research directions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DecentNeRFs: Decentralized Neural Radiance Fields from Crowdsourced Images
Zaid Tasneem, Akshat Dave, Abhishek Singh, Kushagra Tiwary, Praneeth Vepakomma, Ashok Veeraraghavan, Ramesh Raskar
Neural radiance fields (NeRFs) show potential for transforming images captured worldwide into immersive 3D visual experiences. However, most of this captured visual data remains siloed in our camera rolls as these images contain personal details. Even if made public, the problem of learning 3D representations of billions of scenes captured daily in a centralized manner is computationally intractable. Our approach, DecentNeRF, is the first attempt at decentralized, crowd-sourced NeRFs that require $sim 10^4times$ less server computing for a scene than a centralized approach. Instead of sending the raw data, our approach requires users to send a 3D representation, distributing the high computation cost of training centralized NeRFs between the users. It learns photorealistic scene representations by decomposing users' 3D views into personal and global NeRFs and a novel optimally weighted aggregation of only the latter. We validate the advantage of our approach to learn NeRFs with photorealism and minimal server computation cost on structured synthetic and real-world photo tourism datasets. We further analyze how secure aggregation of global NeRFs in DecentNeRF minimizes the undesired reconstruction of personal content by the server.
Read more4/1/2024

0
Federated Neural Radiance Field for Distributed Intelligence
Yintian Zhang, Ziyu Shao
Novel view synthesis (NVS) is an important technology for many AR and VR applications. The recently proposed Neural Radiance Field (NeRF) approach has demonstrated superior performance on NVS tasks, and has been applied to other related fields. However, certain application scenarios with distributed data storage may pose challenges on acquiring training images for the NeRF approach, due to strict regulations and privacy concerns. In order to overcome this challenge, we focus on FedNeRF, a federated learning (FL) based NeRF approach that utilizes images available at different data owners while preserving data privacy. In this paper, we first construct a resource-rich and functionally diverse federated learning testbed. Then, we deploy FedNeRF algorithm in such a practical FL system, and conduct FedNeRF experiments with partial client selection. It is expected that the studies of the FedNeRF approach presented in this paper will be helpful to facilitate future applications of NeRF approach in distributed data storage scenarios.
Read more6/18/2024

0
NeSLAM: Neural Implicit Mapping and Self-Supervised Feature Tracking With Depth Completion and Denoising
Tianchen Deng, Yanbo Wang, Hongle Xie, Hesheng Wang, Jingchuan Wang, Danwei Wang, Weidong Chen
In recent years, there have been significant advancements in 3D reconstruction and dense RGB-D SLAM systems. One notable development is the application of Neural Radiance Fields (NeRF) in these systems, which utilizes implicit neural representation to encode 3D scenes. This extension of NeRF to SLAM has shown promising results. However, the depth images obtained from consumer-grade RGB-D sensors are often sparse and noisy, which poses significant challenges for 3D reconstruction and affects the accuracy of the representation of the scene geometry. Moreover, the original hierarchical feature grid with occupancy value is inaccurate for scene geometry representation. Furthermore, the existing methods select random pixels for camera tracking, which leads to inaccurate localization and is not robust in real-world indoor environments. To this end, we present NeSLAM, an advanced framework that achieves accurate and dense depth estimation, robust camera tracking, and realistic synthesis of novel views. First, a depth completion and denoising network is designed to provide dense geometry prior and guide the neural implicit representation optimization. Second, the occupancy scene representation is replaced with Signed Distance Field (SDF) hierarchical scene representation for high-quality reconstruction and view synthesis. Furthermore, we also propose a NeRF-based self-supervised feature tracking algorithm for robust real-time tracking. Experiments on various indoor datasets demonstrate the effectiveness and accuracy of the system in reconstruction, tracking quality, and novel view synthesis.
Read more4/1/2024

0
DistillNeRF: Perceiving 3D Scenes from Single-Glance Images by Distilling Neural Fields and Foundation Model Features
Letian Wang, Seung Wook Kim, Jiawei Yang, Cunjun Yu, Boris Ivanovic, Steven L. Waslander, Yue Wang, Sanja Fidler, Marco Pavone, Peter Karkus
We propose DistillNeRF, a self-supervised learning framework addressing the challenge of understanding 3D environments from limited 2D observations in autonomous driving. Our method is a generalizable feedforward model that predicts a rich neural scene representation from sparse, single-frame multi-view camera inputs, and is trained self-supervised with differentiable rendering to reconstruct RGB, depth, or feature images. Our first insight is to exploit per-scene optimized Neural Radiance Fields (NeRFs) by generating dense depth and virtual camera targets for training, thereby helping our model to learn 3D geometry from sparse non-overlapping image inputs. Second, to learn a semantically rich 3D representation, we propose distilling features from pre-trained 2D foundation models, such as CLIP or DINOv2, thereby enabling various downstream tasks without the need for costly 3D human annotations. To leverage these two insights, we introduce a novel model architecture with a two-stage lift-splat-shoot encoder and a parameterized sparse hierarchical voxel representation. Experimental results on the NuScenes dataset demonstrate that DistillNeRF significantly outperforms existing comparable self-supervised methods for scene reconstruction, novel view synthesis, and depth estimation; and it allows for competitive zero-shot 3D semantic occupancy prediction, as well as open-world scene understanding through distilled foundation model features. Demos and code will be available at https://distillnerf.github.io/.
Read more6/19/2024