Deep Models for Multi-View 3D Object Recognition: A Review
2404.15224
0
0
🤿
Abstract
Human decision-making often relies on visual information from multiple perspectives or views. In contrast, machine learning-based object recognition utilizes information from a single image of the object. However, the information conveyed by a single image may not be sufficient for accurate decision-making, particularly in complex recognition problems. The utilization of multi-view 3D representations for object recognition has thus far demonstrated the most promising results for achieving state-of-the-art performance. This review paper comprehensively covers recent progress in multi-view 3D object recognition methods for 3D classification and retrieval tasks. Specifically, we focus on deep learning-based and transformer-based techniques, as they are widely utilized and have achieved state-of-the-art performance. We provide detailed information about existing deep learning-based and transformer-based multi-view 3D object recognition models, including the most commonly used 3D datasets, camera configurations and number of views, view selection strategies, pre-trained CNN architectures, fusion strategies, and recognition performance on 3D classification and 3D retrieval tasks. Additionally, we examine various computer vision applications that use multi-view classification. Finally, we highlight key findings and future directions for developing multi-view 3D object recognition methods to provide readers with a comprehensive understanding of the field.
Create account to get full access
Overview
- Humans often rely on visual information from multiple perspectives for decision-making, while machine learning-based object recognition typically uses a single image.
- A single image may not provide sufficient information for accurate object recognition, particularly in complex scenarios.
- Utilizing multi-view 3D representations has shown promise for achieving state-of-the-art performance in object recognition tasks.
Plain English Explanation
When humans make decisions, we often use visual information from different angles or viewpoints. For example, when trying to identify an object, we might look at it from the front, side, and top to get a better understanding of its shape and features. This helps us make more accurate decisions.
On the other hand, most machine learning-based object recognition systems only use a single image of the object. While this can work well in many cases, it may not be enough for more complex recognition problems. The information conveyed by a single image might not be sufficient to make an accurate decision.
To address this, researchers have been exploring the use of multi-view 3D representations for object recognition. By combining information from multiple views of an object in 3D space, these techniques have demonstrated promising results for achieving state-of-the-art performance in object classification and retrieval tasks.
Technical Explanation
This review paper comprehensively covers recent progress in multi-view 3D object recognition methods, focusing on deep learning-based and transformer-based techniques. These approaches have achieved impressive results and are widely used in the field.
The paper provides detailed information about existing deep learning-based and transformer-based multi-view 3D object recognition models. This includes details on the 3D datasets used, camera configurations and number of views, view selection strategies, pre-trained CNN architectures, fusion strategies, and recognition performance on 3D classification and 3D retrieval tasks.
The paper also examines various computer vision applications that leverage multi-view classification, such as 3D pose estimation and multi-modal representation learning.
Critical Analysis
The paper acknowledges that while multi-view 3D object recognition has shown promising results, there are still some limitations and areas for further research. For example, the paper suggests that more work is needed to develop efficient view selection strategies and fusion techniques to combine information from multiple views effectively.
Additionally, the review highlights the need for further research on scaling multi-view 3D object recognition to larger datasets and real-world applications.
Conclusion
This comprehensive review paper provides a detailed overview of the state-of-the-art in multi-view 3D object recognition, focusing on deep learning-based and transformer-based techniques. The paper highlights the potential of utilizing multi-view representations to improve the accuracy and robustness of object recognition systems, particularly in complex scenarios.
The insights and future research directions outlined in this paper can help guide the development of more advanced multi-camera 3D object detection and recognition methods, with significant implications for a wide range of computer vision applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
Multi-person 3D pose estimation from unlabelled data
Daniel Rodriguez-Criado, Pilar Bachiller, George Vogiatzis, Luis J. Manso
0
0
Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, assuming a multiple-view system composed of several regular RGB cameras, 3D multi-pose estimation presents several challenges. First of all, each person must be uniquely identified in the different views to separate the 2D information provided by the cameras. Secondly, the 3D pose estimation process from the multi-view 2D information of each person must be robust against noise and potential occlusions in the scenario. In this work, we address these two challenges with the help of deep learning. Specifically, we present a model based on Graph Neural Networks capable of predicting the cross-view correspondence of the people in the scenario along with a Multilayer Perceptron that takes the 2D points to yield the 3D poses of each person. These two models are trained in a self-supervised manner, thus avoiding the need for large datasets with 3D annotations.
4/10/2024
🤔
MVTN: Learning Multi-View Transformations for 3D Understanding
Abdullah Hamdi, Faisal AlZahrani, Silvio Giancola, Bernard Ghanem
0
0
Multi-view projection techniques have shown themselves to be highly effective in achieving top-performing results in the recognition of 3D shapes. These methods involve learning how to combine information from multiple view-points. However, the camera view-points from which these views are obtained are often fixed for all shapes. To overcome the static nature of current multi-view techniques, we propose learning these view-points. Specifically, we introduce the Multi-View Transformation Network (MVTN), which uses differentiable rendering to determine optimal view-points for 3D shape recognition. As a result, MVTN can be trained end-to-end with any multi-view network for 3D shape classification. We integrate MVTN into a novel adaptive multi-view pipeline that is capable of rendering both 3D meshes and point clouds. Our approach demonstrates state-of-the-art performance in 3D classification and shape retrieval on several benchmarks (ModelNet40, ScanObjectNN, ShapeNet Core55). Further analysis indicates that our approach exhibits improved robustness to occlusion compared to other methods. We also investigate additional aspects of MVTN, such as 2D pretraining and its use for segmentation. To support further research in this area, we have released MVTorch, a PyTorch library for 3D understanding and generation using multi-view projections.
6/7/2024

ImageNet3D: Towards General-Purpose Object-Level 3D Understanding
Wufei Ma, Guanning Zeng, Guofeng Zhang, Qihao Liu, Letian Zhang, Adam Kortylewski, Yaoyao Liu, Alan Yuille
0
0
A vision model with general-purpose object-level 3D understanding should be capable of inferring both 2D (e.g., class name and bounding box) and 3D information (e.g., 3D location and 3D viewpoint) for arbitrary rigid objects in natural images. This is a challenging task, as it involves inferring 3D information from 2D signals and most importantly, generalizing to rigid objects from unseen categories. However, existing datasets with object-level 3D annotations are often limited by the number of categories or the quality of annotations. Models developed on these datasets become specialists for certain categories or domains, and fail to generalize. In this work, we present ImageNet3D, a large dataset for general-purpose object-level 3D understanding. ImageNet3D augments 200 categories from the ImageNet dataset with 2D bounding box, 3D pose, 3D location annotations, and image captions interleaved with 3D information. With the new annotations available in ImageNet3D, we could (i) analyze the object-level 3D awareness of visual foundation models, and (ii) study and develop general-purpose models that infer both 2D and 3D information for arbitrary rigid objects in natural images, and (iii) integrate unified 3D models with large language models for 3D-related reasoning.. We consider two new tasks, probing of object-level 3D awareness and open vocabulary pose estimation, besides standard classification and pose estimation. Experimental results on ImageNet3D demonstrate the potential of our dataset in building vision models with stronger general-purpose object-level 3D understanding.
6/17/2024
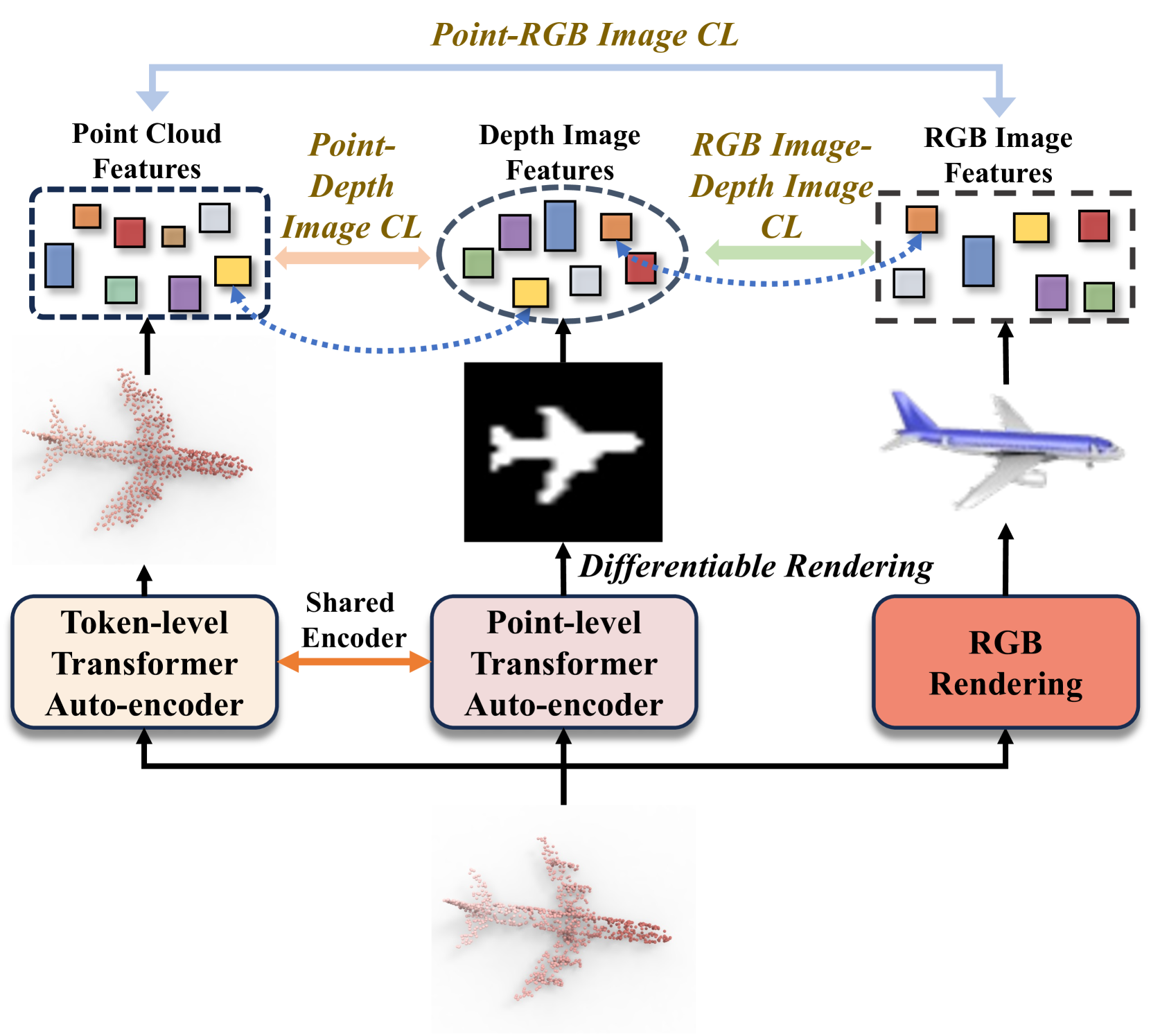
Towards Unified Representation of Multi-Modal Pre-training for 3D Understanding via Differentiable Rendering
Ben Fei, Yixuan Li, Weidong Yang, Lipeng Ma, Ying He
0
0
State-of-the-art 3D models, which excel in recognition tasks, typically depend on large-scale datasets and well-defined category sets. Recent advances in multi-modal pre-training have demonstrated potential in learning 3D representations by aligning features from 3D shapes with their 2D RGB or depth counterparts. However, these existing frameworks often rely solely on either RGB or depth images, limiting their effectiveness in harnessing a comprehensive range of multi-modal data for 3D applications. To tackle this challenge, we present DR-Point, a tri-modal pre-training framework that learns a unified representation of RGB images, depth images, and 3D point clouds by pre-training with object triplets garnered from each modality. To address the scarcity of such triplets, DR-Point employs differentiable rendering to obtain various depth images. This approach not only augments the supply of depth images but also enhances the accuracy of reconstructed point clouds, thereby promoting the representative learning of the Transformer backbone. Subsequently, using a limited number of synthetically generated triplets, DR-Point effectively learns a 3D representation space that aligns seamlessly with the RGB-Depth image space. Our extensive experiments demonstrate that DR-Point outperforms existing self-supervised learning methods in a wide range of downstream tasks, including 3D object classification, part segmentation, point cloud completion, semantic segmentation, and detection. Additionally, our ablation studies validate the effectiveness of DR-Point in enhancing point cloud understanding.
4/23/2024