Multi-person 3D pose estimation from unlabelled data
2212.08731
0
0
📊
Abstract
Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, assuming a multiple-view system composed of several regular RGB cameras, 3D multi-pose estimation presents several challenges. First of all, each person must be uniquely identified in the different views to separate the 2D information provided by the cameras. Secondly, the 3D pose estimation process from the multi-view 2D information of each person must be robust against noise and potential occlusions in the scenario. In this work, we address these two challenges with the help of deep learning. Specifically, we present a model based on Graph Neural Networks capable of predicting the cross-view correspondence of the people in the scenario along with a Multilayer Perceptron that takes the 2D points to yield the 3D poses of each person. These two models are trained in a self-supervised manner, thus avoiding the need for large datasets with 3D annotations.
Create account to get full access
Overview
- 3D multi-person pose estimation is an important and challenging area of research with numerous real-world applications.
- The paper addresses two key challenges in 3D multi-pose estimation using multiple RGB cameras: uniquely identifying people across different views and robustly estimating 3D poses from 2D information.
- The authors propose a deep learning-based approach that uses Graph Neural Networks to solve the cross-view correspondence problem and a Multilayer Perceptron to estimate 3D poses from 2D data.
- Their models are trained in a self-supervised manner, avoiding the need for large datasets with 3D annotations.
Plain English Explanation
Estimating the 3D body poses of multiple people in a scene captured by several cameras is a complex but valuable task. It has many practical applications, such as 3D reconstruction of interacting multi-person clothing, human mesh recovery from arbitrary views, and benchmarking 3D human pose estimation.
However, this problem presents two main challenges. First, the system needs to be able to identify each individual person across the different camera views. Secondly, the 3D pose estimation process must be robust to noise and occlusions in the scene.
The researchers in this paper tackle these challenges using deep learning techniques. They developed a model based on Graph Neural Networks that can predict how the people in the scene correspond across the camera views. They also created a Multilayer Perceptron that takes the 2D information from the cameras and uses it to estimate the 3D poses of each person.
Importantly, both of these models are trained in a self-supervised way, meaning they don't require large datasets with annotated 3D pose information. This makes the approach more practical and accessible compared to methods that rely on such extensive labeled data.
Technical Explanation
The paper presents a deep learning-based approach to 3D multi-person pose estimation from multiple RGB cameras. The key components are:
-
Cross-View Correspondence: The authors use Graph Neural Networks to predict how the detected people in each camera view correspond to each other. This allows the system to uniquely identify individuals across the different views.
-
3D Pose Estimation: A Multilayer Perceptron is used to take the 2D joint locations for each person and estimate their 3D body pose. This model is designed to be robust to noise and occlusions in the input 2D data.
Both of these models are trained in a self-supervised manner, without requiring large datasets with 3D pose annotations. The cross-view correspondence model is trained to predict the matching between people in different views, while the 3D pose estimation model learns to map 2D to 3D pose using the outputs of the correspondence model.
This self-supervised approach is a key innovation of the paper, as it makes the overall system more practical and accessible compared to methods that rely on heavily curated 3D datasets for training.
Critical Analysis
The paper makes a valuable contribution to the field of 3D multi-person pose estimation. The self-supervised training approach is a notable strength, as it reduces the burden of collecting large annotated datasets.
However, the authors acknowledge that their method still has some limitations. For example, it may struggle in scenarios with a large number of people or significant occlusions. Additionally, the accuracy of the 3D pose estimates is not as high as some supervised methods that use more extensive 3D data for training.
Further research could explore ways to improve the robustness of the 3D pose estimation, such as incorporating additional depth or temporal information. Investigating the scalability of the approach to larger and more complex scenes would also be an important next step.
Overall, this work represents a promising step towards more practical 3D multi-person pose estimation systems that can be deployed in real-world applications without the need for extensive manual annotation efforts.
Conclusion
The paper presents a deep learning-based approach to 3D multi-person pose estimation that addresses two key challenges: cross-view correspondence and robust 3D pose estimation from 2D data. By using self-supervised training, the authors have developed a more accessible solution that can be applied without the need for large annotated 3D datasets.
While the method has some limitations, it represents an important advancement in the field and opens up new possibilities for real-world applications of 3D multi-person pose estimation, such as 3D reconstruction of interacting multi-person clothing, human mesh recovery from arbitrary views, and benchmarking 3D human pose estimation. Further research to improve robustness and scalability could unlock even more impactful use cases for this technology.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
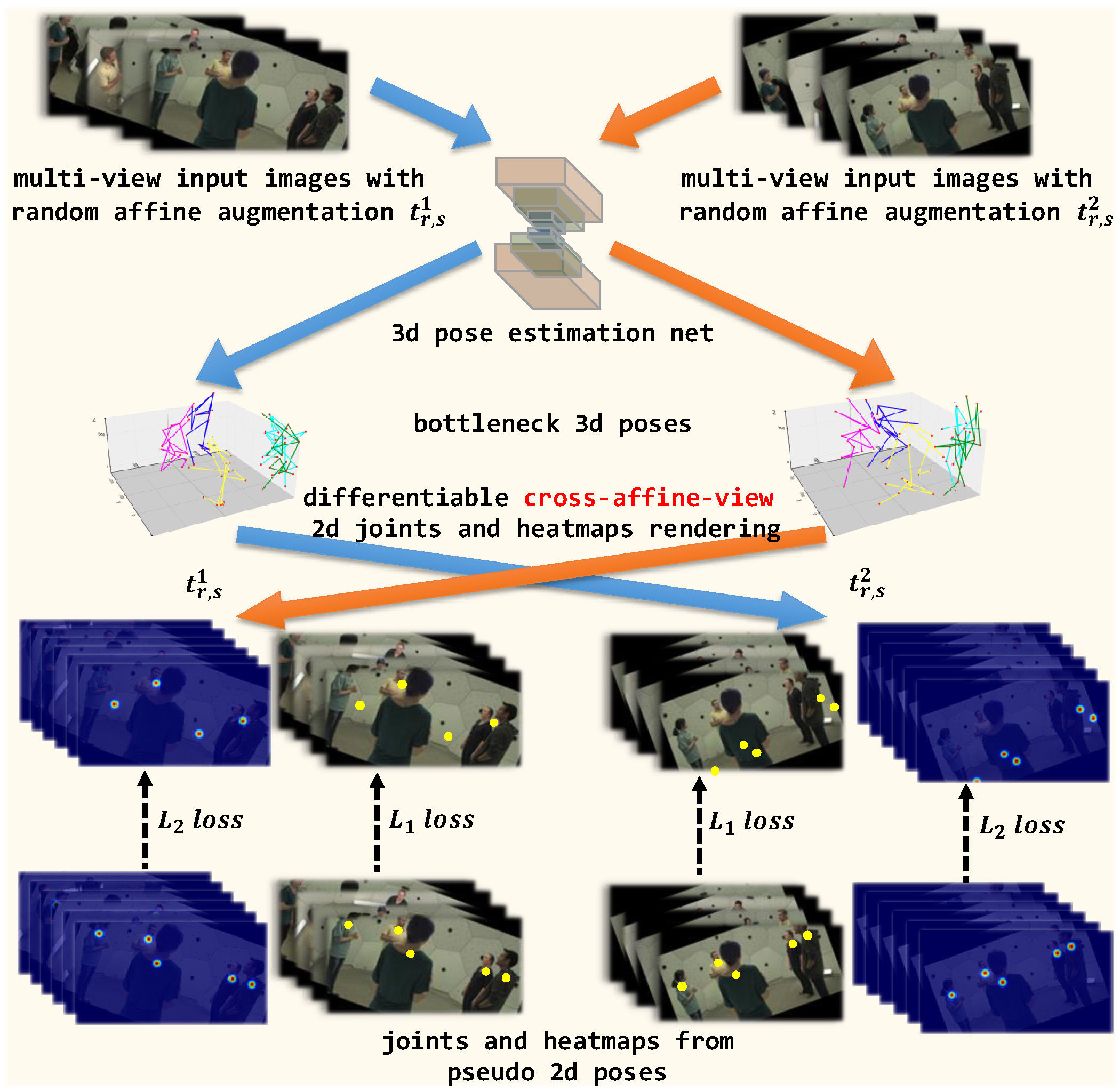
SelfPose3d: Self-Supervised Multi-Person Multi-View 3d Pose Estimation
Vinkle Srivastav, Keqi Chen, Nicolas Padoy
0
0
We present a new self-supervised approach, SelfPose3d, for estimating 3d poses of multiple persons from multiple camera views. Unlike current state-of-the-art fully-supervised methods, our approach does not require any 2d or 3d ground-truth poses and uses only the multi-view input images from a calibrated camera setup and 2d pseudo poses generated from an off-the-shelf 2d human pose estimator. We propose two self-supervised learning objectives: self-supervised person localization in 3d space and self-supervised 3d pose estimation. We achieve self-supervised 3d person localization by training the model on synthetically generated 3d points, serving as 3d person root positions, and on the projected root-heatmaps in all the views. We then model the 3d poses of all the localized persons with a bottleneck representation, map them onto all views obtaining 2d joints, and render them using 2d Gaussian heatmaps in an end-to-end differentiable manner. Afterwards, we use the corresponding 2d joints and heatmaps from the pseudo 2d poses for learning. To alleviate the intrinsic inaccuracy of the pseudo labels, we propose an adaptive supervision attention mechanism to guide the self-supervision. Our experiments and analysis on three public benchmark datasets, including Panoptic, Shelf, and Campus, show the effectiveness of our approach, which is comparable to fully-supervised methods. Code: https://github.com/CAMMA-public/SelfPose3D. Video demo: https://youtu.be/GAqhmUIr2E8.
6/11/2024
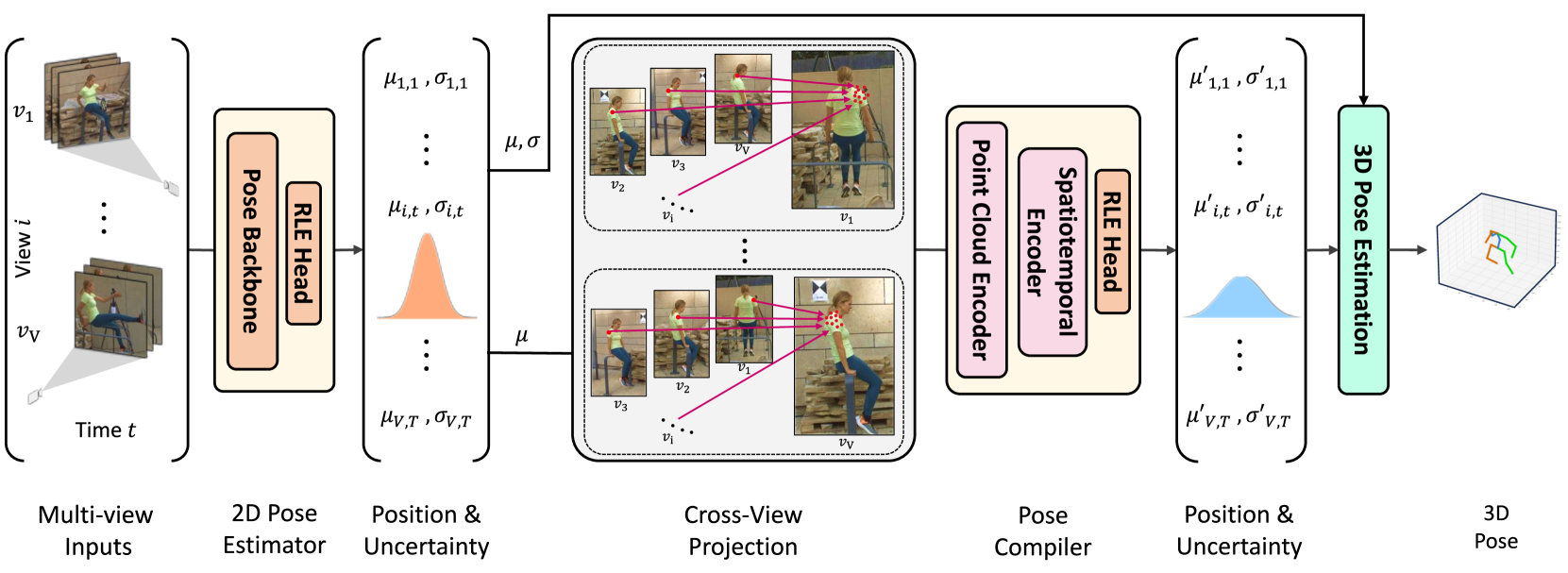
UPose3D: Uncertainty-Aware 3D Human Pose Estimation with Cross-View and Temporal Cues
Vandad Davoodnia, Saeed Ghorbani, Marc-Andr'e Carbonneau, Alexandre Messier, Ali Etemad
0
0
We introduce UPose3D, a novel approach for multi-view 3D human pose estimation, addressing challenges in accuracy and scalability. Our method advances existing pose estimation frameworks by improving robustness and flexibility without requiring direct 3D annotations. At the core of our method, a pose compiler module refines predictions from a 2D keypoints estimator that operates on a single image by leveraging temporal and cross-view information. Our novel cross-view fusion strategy is scalable to any number of cameras, while our synthetic data generation strategy ensures generalization across diverse actors, scenes, and viewpoints. Finally, UPose3D leverages the prediction uncertainty of both the 2D keypoint estimator and the pose compiler module. This provides robustness to outliers and noisy data, resulting in state-of-the-art performance in out-of-distribution settings. In addition, for in-distribution settings, UPose3D yields a performance rivaling methods that rely on 3D annotated data, while being the state-of-the-art among methods relying only on 2D supervision.
5/16/2024

Human Modelling and Pose Estimation Overview
Pawel Knap
0
0
Human modelling and pose estimation stands at the crossroads of Computer Vision, Computer Graphics, and Machine Learning. This paper presents a thorough investigation of this interdisciplinary field, examining various algorithms, methodologies, and practical applications. It explores the diverse range of sensor technologies relevant to this domain and delves into a wide array of application areas. Additionally, we discuss the challenges and advancements in 2D and 3D human modelling methodologies, along with popular datasets, metrics, and future research directions. The main contribution of this paper lies in its up-to-date comparison of state-of-the-art (SOTA) human pose estimation algorithms in both 2D and 3D domains. By providing this comprehensive overview, the paper aims to enhance understanding of 3D human modelling and pose estimation, offering insights into current SOTA achievements, challenges, and future prospects within the field.
6/28/2024

Estimating Human Poses Across Datasets: A Unified Skeleton and Multi-Teacher Distillation Approach
Muhammad Saif Ullah Khan, Dhavalkumar Limbachiya, Didier Stricker, Muhammad Zeshan Afzal
0
0
Human pose estimation is a key task in computer vision with various applications such as activity recognition and interactive systems. However, the lack of consistency in the annotated skeletons across different datasets poses challenges in developing universally applicable models. To address this challenge, we propose a novel approach integrating multi-teacher knowledge distillation with a unified skeleton representation. Our networks are jointly trained on the COCO and MPII datasets, containing 17 and 16 keypoints, respectively. We demonstrate enhanced adaptability by predicting an extended set of 21 keypoints, 4 (COCO) and 5 (MPII) more than original annotations, improving cross-dataset generalization. Our joint models achieved an average accuracy of 70.89 and 76.40, compared to 53.79 and 55.78 when trained on a single dataset and evaluated on both. Moreover, we also evaluate all 21 predicted points by our two models by reporting an AP of 66.84 and 72.75 on the Halpe dataset. This highlights the potential of our technique to address one of the most pressing challenges in pose estimation research and application - the inconsistency in skeletal annotations.
5/31/2024