DeepLight: Reconstructing High-Resolution Observations of Nighttime Light With Multi-Modal Remote Sensing Data
2402.15659
0
0

Abstract
Nighttime light (NTL) remote sensing observation serves as a unique proxy for quantitatively assessing progress toward meeting a series of Sustainable Development Goals (SDGs), such as poverty estimation, urban sustainable development, and carbon emission. However, existing NTL observations often suffer from pervasive degradation and inconsistency, limiting their utility for computing the indicators defined by the SDGs. In this study, we propose a novel approach to reconstruct high-resolution NTL images using multi-modal remote sensing data. To support this research endeavor, we introduce DeepLightMD, a comprehensive dataset comprising data from five heterogeneous sensors, offering fine spatial resolution and rich spectral information at a national scale. Additionally, we present DeepLightSR, a calibration-aware method for building bridges between spatially heterogeneous modality data in the multi-modality super-resolution. DeepLightSR integrates calibration-aware alignment, an auxiliary-to-main multi-modality fusion, and an auxiliary-embedded refinement to effectively address spatial heterogeneity, fuse diversely representative features, and enhance performance in $8times$ super-resolution (SR) tasks. Extensive experiments demonstrate the superiority of DeepLightSR over 8 competing methods, as evidenced by improvements in PSNR (2.01 dB $ sim $ 13.25 dB) and PIQE (0.49 $ sim $ 9.32). Our findings underscore the practical significance of our proposed dataset and model in reconstructing high-resolution NTL data, supporting efficiently and quantitatively assessing the SDG progress.
Create account to get full access
Overview
- This paper introduces "DeepLight", a deep learning-based approach for reconstructing high-resolution observations of nighttime light using multi-modal remote sensing data.
- The method aims to address the limitations of existing satellite-based nighttime light data, which often has low spatial resolution and is influenced by various atmospheric and environmental factors.
- DeepLight leverages complementary information from different remote sensing modalities, such as optical, thermal, and radar data, to generate high-quality nighttime light observations.
Plain English Explanation
Nighttime light observations from satellites are used for various applications, such as monitoring urban growth, estimating energy consumption, and studying human activity patterns. However, the images captured by these satellites often have low resolution and can be affected by factors like weather conditions and atmospheric interference.
The researchers developed a new approach called "DeepLight" to address these limitations. DeepLight uses a deep learning model to combine data from different remote sensing sources, such as optical, thermal, and radar images, to generate high-quality, high-resolution nighttime light observations.
By leveraging the complementary information provided by these diverse data sources, DeepLight can create more detailed and accurate maps of nighttime light, which can be valuable for a wide range of applications, from urban planning to disaster response.
Technical Explanation
The key technical aspects of the DeepLight approach are:
-
Data Fusion: DeepLight integrates information from multiple remote sensing modalities, including optical, thermal, and radar data, to create a comprehensive representation of nighttime light conditions.
-
Deep Learning Architecture: The researchers developed a deep neural network that can effectively fuse the multi-modal data and generate high-resolution nighttime light reconstructions.
-
Spatiotemporal Modeling: DeepLight considers both spatial and temporal information to improve the accuracy of nighttime light reconstructions, accounting for factors like seasonal variations and changes over time.
-
Evaluation: The paper presents extensive experiments and evaluations of DeepLight, comparing its performance against existing satellite-based nighttime light data and other state-of-the-art methods.
The results demonstrate that DeepLight can significantly improve the spatial resolution and accuracy of nighttime light observations, paving the way for more detailed and reliable analysis of urban areas, energy consumption patterns, and human activities.
Critical Analysis
The researchers acknowledge several limitations and areas for further research:
-
Data Availability: The performance of DeepLight is dependent on the availability and quality of the multi-modal remote sensing data, which may not be readily accessible in all regions.
-
Computational Complexity: The deep learning-based approach used in DeepLight can be computationally intensive, which may limit its scalability and real-time application in certain scenarios.
-
Validation and Generalization: While the paper presents extensive evaluations, further research is needed to validate the performance of DeepLight across a wider range of geographic areas and use cases.
-
Interpretability: As with many deep learning models, the inner workings of DeepLight may not be fully transparent, which can be a concern for certain applications that require explainable decision-making.
Overall, the DeepLight approach represents a promising step forward in addressing the limitations of existing satellite-based nighttime light data. However, continued research and development are needed to address the identified challenges and further improve the robustness and applicability of this technology.
Conclusion
The DeepLight paper introduces a novel approach for reconstructing high-resolution observations of nighttime light using multi-modal remote sensing data. By integrating information from various data sources, the deep learning-based model can generate more detailed and accurate nighttime light maps, which have the potential to significantly benefit a wide range of applications, from urban planning and energy management to disaster response and socioeconomic analysis.
While the paper identifies several areas for further research, the successful demonstration of the DeepLight approach highlights the value of leveraging diverse remote sensing data and advanced data fusion techniques to overcome the limitations of traditional satellite-based nighttime light observations. As the field of remote sensing continues to evolve, innovations like DeepLight may pave the way for more comprehensive and reliable monitoring of human activities and their impact on the environment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
Semantic Guided Large Scale Factor Remote Sensing Image Super-resolution with Generative Diffusion Prior
Ce Wang, Wanjie Sun
0
0
Remote sensing images captured by different platforms exhibit significant disparities in spatial resolution. Large scale factor super-resolution (SR) algorithms are vital for maximizing the utilization of low-resolution (LR) satellite data captured from orbit. However, existing methods confront challenges in recovering SR images with clear textures and correct ground objects. We introduce a novel framework, the Semantic Guided Diffusion Model (SGDM), designed for large scale factor remote sensing image super-resolution. The framework exploits a pre-trained generative model as a prior to generate perceptually plausible SR images. We further enhance the reconstruction by incorporating vector maps, which carry structural and semantic cues. Moreover, pixel-level inconsistencies in paired remote sensing images, stemming from sensor-specific imaging characteristics, may hinder the convergence of the model and diversity in generated results. To address this problem, we propose to extract the sensor-specific imaging characteristics and model the distribution of them, allowing diverse SR images generation based on imaging characteristics provided by reference images or sampled from the imaging characteristic probability distributions. To validate and evaluate our approach, we create the Cross-Modal Super-Resolution Dataset (CMSRD). Qualitative and quantitative experiments on CMSRD showcase the superiority and broad applicability of our method. Experimental results on downstream vision tasks also demonstrate the utilitarian of the generated SR images. The dataset and code will be publicly available at https://github.com/wwangcece/SGDM
5/14/2024
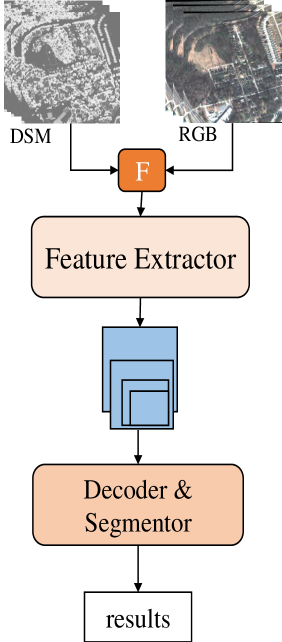
LMFNet: An Efficient Multimodal Fusion Approach for Semantic Segmentation in High-Resolution Remote Sensing
Tong Wang, Guanzhou Chen, Xiaodong Zhang, Chenxi Liu, Xiaoliang Tan, Jiaqi Wang, Chanjuan He, Wenlin Zhou
0
0
Despite the rapid evolution of semantic segmentation for land cover classification in high-resolution remote sensing imagery, integrating multiple data modalities such as Digital Surface Model (DSM), RGB, and Near-infrared (NIR) remains a challenge. Current methods often process only two types of data, missing out on the rich information that additional modalities can provide. Addressing this gap, we propose a novel textbf{L}ightweight textbf{M}ultimodal data textbf{F}usion textbf{Net}work (LMFNet) to accomplish the tasks of fusion and semantic segmentation of multimodal remote sensing images. LMFNet uniquely accommodates various data types simultaneously, including RGB, NirRG, and DSM, through a weight-sharing, multi-branch vision transformer that minimizes parameter count while ensuring robust feature extraction. Our proposed multimodal fusion module integrates a textit{Multimodal Feature Fusion Reconstruction Layer} and textit{Multimodal Feature Self-Attention Fusion Layer}, which can reconstruct and fuse multimodal features. Extensive testing on public datasets such as US3D, ISPRS Potsdam, and ISPRS Vaihingen demonstrates the effectiveness of LMFNet. Specifically, it achieves a mean Intersection over Union ($mIoU$) of 85.09% on the US3D dataset, marking a significant improvement over existing methods. Compared to unimodal approaches, LMFNet shows a 10% enhancement in $mIoU$ with only a 0.5M increase in parameter count. Furthermore, against bimodal methods, our approach with trilateral inputs enhances $mIoU$ by 0.46 percentage points.
4/23/2024
Spatial-frequency Dual-Domain Feature Fusion Network for Low-Light Remote Sensing Image Enhancement
Zishu Yao, Guodong Fan, Jinfu Fan, Min Gan, C. L. Philip Chen
0
0
Low-light remote sensing images generally feature high resolution and high spatial complexity, with continuously distributed surface features in space. This continuity in scenes leads to extensive long-range correlations in spatial domains within remote sensing images. Convolutional Neural Networks, which rely on local correlations for long-distance modeling, struggle to establish long-range correlations in such images. On the other hand, transformer-based methods that focus on global information face high computational complexities when processing high-resolution remote sensing images. From another perspective, Fourier transform can compute global information without introducing a large number of parameters, enabling the network to more efficiently capture the overall image structure and establish long-range correlations. Therefore, we propose a Dual-Domain Feature Fusion Network (DFFN) for low-light remote sensing image enhancement. Specifically, this challenging task of low-light enhancement is divided into two more manageable sub-tasks: the first phase learns amplitude information to restore image brightness, and the second phase learns phase information to refine details. To facilitate information exchange between the two phases, we designed an information fusion affine block that combines data from different phases and scales. Additionally, we have constructed two dark light remote sensing datasets to address the current lack of datasets in dark light remote sensing image enhancement. Extensive evaluations show that our method outperforms existing state-of-the-art methods. The code is available at https://github.com/iijjlk/DFFN.
4/29/2024
🖼️
Learning transformer-based heterogeneously salient graph representation for multimodal remote sensing image classification
Jiaqi Yang, Bo Du, Liangpei Zhang
0
0
Data collected by different modalities can provide a wealth of complementary information, such as hyperspectral image (HSI) to offer rich spectral-spatial properties, synthetic aperture radar (SAR) to provide structural information about the Earth's surface, and light detection and ranging (LiDAR) to cover altitude information about ground elevation. Therefore, a natural idea is to combine multimodal images for refined and accurate land-cover interpretation. Although many efforts have been attempted to achieve multi-source remote sensing image classification, there are still three issues as follows: 1) indiscriminate feature representation without sufficiently considering modal heterogeneity, 2) abundant features and complex computations associated with modeling long-range dependencies, and 3) overfitting phenomenon caused by sparsely labeled samples. To overcome the above barriers, a transformer-based heterogeneously salient graph representation (THSGR) approach is proposed in this paper. First, a multimodal heterogeneous graph encoder is presented to encode distinctively non-Euclidean structural features from heterogeneous data. Then, a self-attention-free multi-convolutional modulator is designed for effective and efficient long-term dependency modeling. Finally, a mean forward is put forward in order to avoid overfitting. Based on the above structures, the proposed model is able to break through modal gaps to obtain differentiated graph representation with competitive time cost, even for a small fraction of training samples. Experiments and analyses on three benchmark datasets with various state-of-the-art (SOTA) methods show the performance of the proposed approach.
6/11/2024