Semantic Guided Large Scale Factor Remote Sensing Image Super-resolution with Generative Diffusion Prior
2405.07044
0
0
🖼️
Abstract
Remote sensing images captured by different platforms exhibit significant disparities in spatial resolution. Large scale factor super-resolution (SR) algorithms are vital for maximizing the utilization of low-resolution (LR) satellite data captured from orbit. However, existing methods confront challenges in recovering SR images with clear textures and correct ground objects. We introduce a novel framework, the Semantic Guided Diffusion Model (SGDM), designed for large scale factor remote sensing image super-resolution. The framework exploits a pre-trained generative model as a prior to generate perceptually plausible SR images. We further enhance the reconstruction by incorporating vector maps, which carry structural and semantic cues. Moreover, pixel-level inconsistencies in paired remote sensing images, stemming from sensor-specific imaging characteristics, may hinder the convergence of the model and diversity in generated results. To address this problem, we propose to extract the sensor-specific imaging characteristics and model the distribution of them, allowing diverse SR images generation based on imaging characteristics provided by reference images or sampled from the imaging characteristic probability distributions. To validate and evaluate our approach, we create the Cross-Modal Super-Resolution Dataset (CMSRD). Qualitative and quantitative experiments on CMSRD showcase the superiority and broad applicability of our method. Experimental results on downstream vision tasks also demonstrate the utilitarian of the generated SR images. The dataset and code will be publicly available at https://github.com/wwangcece/SGDM
Create account to get full access
Overview
- Remote sensing images from different platforms have significant differences in spatial resolution.
- Large-scale super-resolution (SR) algorithms are crucial for maximizing the use of low-resolution satellite data.
- Existing methods struggle to recover SR images with clear textures and accurate ground objects.
- The paper introduces a novel framework, the Semantic Guided Diffusion Model (SGDM), for large-scale remote sensing image super-resolution.
Plain English Explanation
The paper focuses on a common problem in remote sensing: images captured from different platforms (e.g., satellites, drones) often have very different levels of detail or "resolution." Lower-resolution images can be valuable, but it's important to be able to enhance them and recover more fine-grained details.
The researchers developed a new approach called the Semantic Guided Diffusion Model (SGDM) to tackle this challenge. Their key insight was to use a pre-trained machine learning model as a starting point to generate high-quality, realistic super-resolution images. They further improved the results by incorporating additional information, like vector maps that provide structural and semantic cues about the scene.
A unique aspect of their approach is that it can account for differences in how the original low-resolution images were captured. This helps the model generate a diverse set of super-resolution results that reflect the unique characteristics of different imaging sensors.
To validate their method, the researchers created a new dataset called the Cross-Modal Super-Resolution Dataset (CMSRD). Their experiments show that the SGDM framework outperforms existing super-resolution techniques and produces results that are useful for downstream computer vision tasks.
Technical Explanation
The Semantic Guided Diffusion Model (SGDM) framework leverages a pre-trained generative model as a prior to produce perceptually plausible super-resolution (SR) images from low-resolution (LR) remote sensing inputs. To further enhance the reconstruction, the researchers incorporate vector maps that provide structural and semantic information about the scene.
A key challenge in remote sensing SR is the presence of pixel-level inconsistencies between paired LR and HR images, due to sensor-specific imaging characteristics. The SGDM addresses this by modeling the distribution of these sensor-specific imaging characteristics, allowing it to generate diverse SR results that reflect the unique properties of different imaging sensors.
The researchers create the Cross-Modal Super-Resolution Dataset (CMSRD) to evaluate their approach. Qualitative and quantitative experiments on this dataset demonstrate the superiority of SGDM compared to existing SR methods, as well as the utility of the generated SR images for downstream computer vision tasks.
Critical Analysis
The paper presents a novel and promising approach to large-scale remote sensing super-resolution, but there are a few potential areas for further exploration:
-
The authors mention that their method can generate diverse SR results, but it would be helpful to see more analysis on the diversity and consistency of the generated outputs.
-
While the CMSRD dataset is a valuable contribution, it would be interesting to see how the SGDM framework performs on other real-world remote sensing benchmarks, such as the PROBA-V dataset or the Sentinel-2 dataset.
-
The paper focuses on large-scale super-resolution, but it would be worthwhile to explore the performance of the SGDM approach on more moderate scale-up factors, as those may be more common in practical applications.
-
The authors could provide more insight into the computational complexity and resource requirements of their method, as that information is important for real-world deployment.
Overall, the Semantic Guided Diffusion Model (SGDM) represents a significant advancement in remote sensing super-resolution and is worthy of further research and refinement.
Conclusion
The paper introduces the Semantic Guided Diffusion Model (SGDM), a novel framework for large-scale remote sensing image super-resolution. By leveraging a pre-trained generative model and incorporating vector maps, the SGDM can produce perceptually plausible SR images that capture the structural and semantic details of the scene.
A unique aspect of the SGDM is its ability to model sensor-specific imaging characteristics, allowing it to generate diverse SR results that reflect the unique properties of different imaging platforms. The creation of the Cross-Modal Super-Resolution Dataset (CMSRD) is also a valuable contribution, providing a benchmark for evaluating remote sensing SR approaches.
Overall, the SGDM framework represents a significant step forward in maximizing the utility of low-resolution satellite data, with the potential to enable more detailed analysis and insights from remote sensing imagery.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SeeSR: Towards Semantics-Aware Real-World Image Super-Resolution
Rongyuan Wu, Tao Yang, Lingchen Sun, Zhengqiang Zhang, Shuai Li, Lei Zhang
0
0
Owe to the powerful generative priors, the pre-trained text-to-image (T2I) diffusion models have become increasingly popular in solving the real-world image super-resolution problem. However, as a consequence of the heavy quality degradation of input low-resolution (LR) images, the destruction of local structures can lead to ambiguous image semantics. As a result, the content of reproduced high-resolution image may have semantic errors, deteriorating the super-resolution performance. To address this issue, we present a semantics-aware approach to better preserve the semantic fidelity of generative real-world image super-resolution. First, we train a degradation-aware prompt extractor, which can generate accurate soft and hard semantic prompts even under strong degradation. The hard semantic prompts refer to the image tags, aiming to enhance the local perception ability of the T2I model, while the soft semantic prompts compensate for the hard ones to provide additional representation information. These semantic prompts encourage the T2I model to generate detailed and semantically accurate results. Furthermore, during the inference process, we integrate the LR images into the initial sampling noise to mitigate the diffusion model's tendency to generate excessive random details. The experiments show that our method can reproduce more realistic image details and hold better the semantics. The source code of our method can be found at https://github.com/cswry/SeeSR.
6/5/2024

Real-GDSR: Real-World Guided DSM Super-Resolution via Edge-Enhancing Residual Network
Daniel Panangian, Ksenia Bittner
0
0
A low-resolution digital surface model (DSM) features distinctive attributes impacted by noise, sensor limitations and data acquisition conditions, which failed to be replicated using simple interpolation methods like bicubic. This causes super-resolution models trained on synthetic data does not perform effectively on real ones. Training a model on real low and high resolution DSMs pairs is also a challenge because of the lack of information. On the other hand, the existence of other imaging modalities of the same scene can be used to enrich the information needed for large-scale super-resolution. In this work, we introduce a novel methodology to address the intricacies of real-world DSM super-resolution, named REAL-GDSR, breaking down this ill-posed problem into two steps. The first step involves the utilization of a residual local refinement network. This strategic approach departs from conventional methods that trained to directly predict height values instead of the differences (residuals) and utilize large receptive fields in their networks. The second step introduces a diffusion-based technique that enhances the results on a global scale, with a primary focus on smoothing and edge preservation. Our experiments underscore the effectiveness of the proposed method. We conduct a comprehensive evaluation, comparing it to recent state-of-the-art techniques in the domain of real-world DSM super-resolution (SR). Our approach consistently outperforms these existing methods, as evidenced through qualitative and quantitative assessments.
4/8/2024
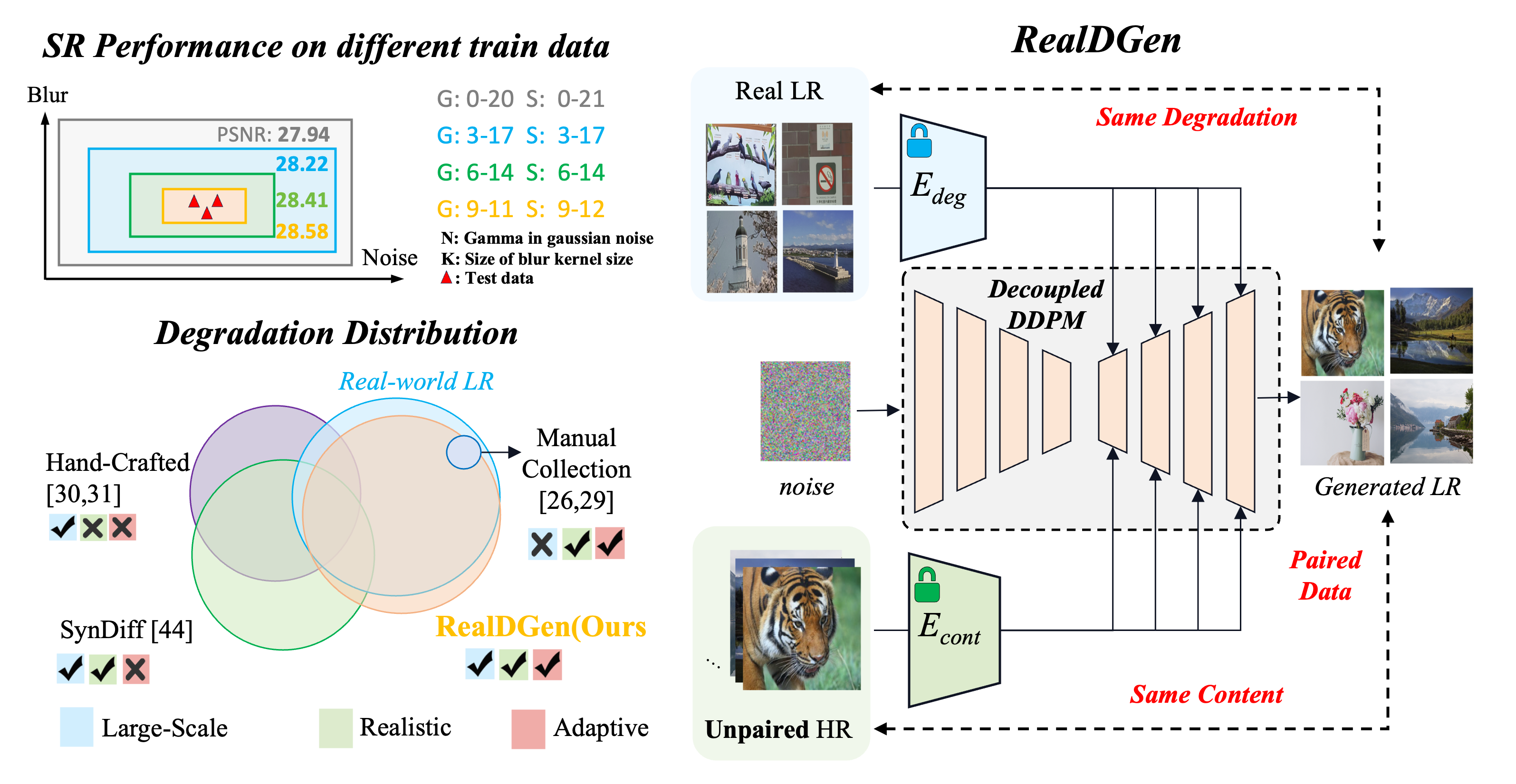
Towards Realistic Data Generation for Real-World Super-Resolution
Long Peng, Wenbo Li, Renjing Pei, Jingjing Ren, Xueyang Fu, Yang Wang, Yang Cao, Zheng-Jun Zha
0
0
Existing image super-resolution (SR) techniques often fail to generalize effectively in complex real-world settings due to the significant divergence between training data and practical scenarios. To address this challenge, previous efforts have either manually simulated intricate physical-based degradations or utilized learning-based techniques, yet these approaches remain inadequate for producing large-scale, realistic, and diverse data simultaneously. In this paper, we introduce a novel Realistic Decoupled Data Generator (RealDGen), an unsupervised learning data generation framework designed for real-world super-resolution. We meticulously develop content and degradation extraction strategies, which are integrated into a novel content-degradation decoupled diffusion model to create realistic low-resolution images from unpaired real LR and HR images. Extensive experiments demonstrate that RealDGen excels in generating large-scale, high-quality paired data that mirrors real-world degradations, significantly advancing the performance of popular SR models on various real-world benchmarks.
6/13/2024

Diffusion Models, Image Super-Resolution And Everything: A Survey
Brian B. Moser, Arundhati S. Shanbhag, Federico Raue, Stanislav Frolov, Sebastian Palacio, Andreas Dengel
0
0
Diffusion Models (DMs) have disrupted the image Super-Resolution (SR) field and further closed the gap between image quality and human perceptual preferences. They are easy to train and can produce very high-quality samples that exceed the realism of those produced by previous generative methods. Despite their promising results, they also come with new challenges that need further research: high computational demands, comparability, lack of explainability, color shifts, and more. Unfortunately, entry into this field is overwhelming because of the abundance of publications. To address this, we provide a unified recount of the theoretical foundations underlying DMs applied to image SR and offer a detailed analysis that underscores the unique characteristics and methodologies within this domain, distinct from broader existing reviews in the field. This survey articulates a cohesive understanding of DM principles and explores current research avenues, including alternative input domains, conditioning techniques, guidance mechanisms, corruption spaces, and zero-shot learning approaches. By offering a detailed examination of the evolution and current trends in image SR through the lens of DMs, this survey sheds light on the existing challenges and charts potential future directions, aiming to inspire further innovation in this rapidly advancing area.
6/26/2024