Denoising LM: Pushing the Limits of Error Correction Models for Speech Recognition
2405.15216
0
0

Abstract
Language models (LMs) have long been used to improve results of automatic speech recognition (ASR) systems, but they are unaware of the errors that ASR systems make. Error correction models are designed to fix ASR errors, however, they showed little improvement over traditional LMs mainly due to the lack of supervised training data. In this paper, we present Denoising LM (DLM), which is a $textit{scaled}$ error correction model trained with vast amounts of synthetic data, significantly exceeding prior attempts meanwhile achieving new state-of-the-art ASR performance. We use text-to-speech (TTS) systems to synthesize audio, which is fed into an ASR system to produce noisy hypotheses, which are then paired with the original texts to train the DLM. DLM has several $textit{key ingredients}$: (i) up-scaled model and data; (ii) usage of multi-speaker TTS systems; (iii) combination of multiple noise augmentation strategies; and (iv) new decoding techniques. With a Transformer-CTC ASR, DLM achieves 1.5% word error rate (WER) on $textit{test-clean}$ and 3.3% WER on $textit{test-other}$ on Librispeech, which to our knowledge are the best reported numbers in the setting where no external audio data are used and even match self-supervised methods which use external audio data. Furthermore, a single DLM is applicable to different ASRs, and greatly surpassing the performance of conventional LM based beam-search rescoring. These results indicate that properly investigated error correction models have the potential to replace conventional LMs, holding the key to a new level of accuracy in ASR systems.
Create account to get full access
Overview
- The paper explores techniques to improve speech recognition by leveraging error correction models based on large language models (LLMs).
- The researchers investigate the limits of what can be achieved by denoising LLMs in the context of speech recognition.
- They propose a new framework called "Denoising LM" that outperforms existing state-of-the-art speech recognition approaches.
Plain English Explanation
Speech recognition is the process of converting spoken words into text, and it's a crucial technology for many applications like voice assistants and transcription services. However, speech recognition systems can make mistakes, especially in noisy environments.
The researchers in this paper tried to address this problem by using large language models (LLMs) - powerful AI models that can understand and generate human-like text. The idea is to use these LLMs to "denoise" the output of speech recognition systems, correcting any errors or mistakes.
The paper presents a new framework called "Denoising LM" that takes the output of a speech recognition system and uses an LLM to clean it up and fix any errors. The researchers found that this approach can significantly improve the accuracy of speech recognition, even in challenging conditions with a lot of background noise.
By leveraging the impressive language understanding capabilities of LLMs, the "Denoising LM" framework pushes the limits of what's possible with error correction in speech recognition. This could lead to more reliable and effective voice-based technologies in the future.
Technical Explanation
The key technical contribution of the paper is the "Denoising LM" framework, which integrates a large language model (LLM) into the speech recognition pipeline to improve accuracy.
The framework works by first running a speech recognition system to generate an initial text transcript. This transcript is then passed to the "Denoising LM" component, which is an LLM-based model trained to identify and correct errors in the transcript.
The researchers experimented with different types of LLMs, including Contrastive Consistency Learning for Neural Noisy Channel Model and Transforming LLMs into Cross-Modal, Cross-Lingual Experts. They found that LLMs with stronger language understanding capabilities performed better at the denoising task.
Additionally, the paper explores techniques to make the Denoising LM more robust to noisy input, such as Resilience of Large Language Models to Noisy Instructions. This allows the framework to maintain high accuracy even when the initial speech recognition output contains significant errors.
The researchers conducted extensive experiments on multiple speech recognition benchmarks, including Listen Again, Choose the Right Answer: A New Paradigm for Spoken Language Understanding and Unveiling the Potential of LLM-based ASR for Chinese Open-Domain Conversations. The results demonstrate that the Denoising LM framework outperforms state-of-the-art speech recognition approaches across a range of scenarios.
Critical Analysis
The paper presents a compelling approach to improving speech recognition accuracy by leveraging the power of large language models. The researchers have clearly demonstrated the potential of the Denoising LM framework through their extensive experiments.
One potential limitation of the approach is its reliance on the initial speech recognition system to provide a reasonable starting point. If the speech recognition system produces highly inaccurate output, the Denoising LM may struggle to effectively correct the errors.
Additionally, the paper does not address the computational cost and inference time of the Denoising LM component, which could be a practical concern for real-time speech recognition applications.
Further research could explore ways to make the Denoising LM more robust to poor-quality input from the speech recognition system, as well as optimizing its efficiency to enable deployment in real-world scenarios.
Conclusion
The "Denoising LM" framework presented in this paper represents a significant advancement in using large language models to improve speech recognition accuracy. By leveraging the powerful language understanding capabilities of LLMs, the researchers have demonstrated the potential to push the limits of what's possible with error correction in speech recognition.
The findings in this paper could have important implications for the development of more reliable and effective voice-based technologies, such as virtual assistants, transcription services, and voice-controlled interfaces. As large language models continue to advance, the integration of these models into speech recognition systems could lead to transformative improvements in the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Multi-stage Large Language Model Correction for Speech Recognition
Jie Pu, Thai-Son Nguyen, Sebastian Stuker
0
0
In this paper, we investigate the usage of large language models (LLMs) to improve the performance of competitive speech recognition systems. Different from previous LLM-based ASR error correction methods, we propose a novel multi-stage approach that utilizes uncertainty estimation of ASR outputs and reasoning capability of LLMs. Specifically, the proposed approach has two stages: the first stage is about ASR uncertainty estimation and exploits N-best list hypotheses to identify less reliable transcriptions; The second stage works on these identified transcriptions and performs LLM-based corrections. This correction task is formulated as a multi-step rule-based LLM reasoning process, which uses explicitly written rules in prompts to decompose the task into concrete reasoning steps. Our experimental results demonstrate the effectiveness of the proposed method by showing 10% ~ 20% relative improvement in WER over competitive ASR systems -- across multiple test domains and in zero-shot settings.
6/18/2024

Listen Again and Choose the Right Answer: A New Paradigm for Automatic Speech Recognition with Large Language Models
Yuchen Hu, Chen Chen, Chengwei Qin, Qiushi Zhu, Eng Siong Chng, Ruizhe Li
0
0
Recent advances in large language models (LLMs) have promoted generative error correction (GER) for automatic speech recognition (ASR), which aims to predict the ground-truth transcription from the decoded N-best hypotheses. Thanks to the strong language generation ability of LLMs and rich information in the N-best list, GER shows great effectiveness in enhancing ASR results. However, it still suffers from two limitations: 1) LLMs are unaware of the source speech during GER, which may lead to results that are grammatically correct but violate the source speech content, 2) N-best hypotheses usually only vary in a few tokens, making it redundant to send all of them for GER, which could confuse LLM about which tokens to focus on and thus lead to increased miscorrection. In this paper, we propose ClozeGER, a new paradigm for ASR generative error correction. First, we introduce a multimodal LLM (i.e., SpeechGPT) to receive source speech as extra input to improve the fidelity of correction output. Then, we reformat GER as a cloze test with logits calibration to remove the input information redundancy and simplify GER with clear instructions. Experiments show that ClozeGER achieves a new breakthrough over vanilla GER on 9 popular ASR datasets.
5/17/2024
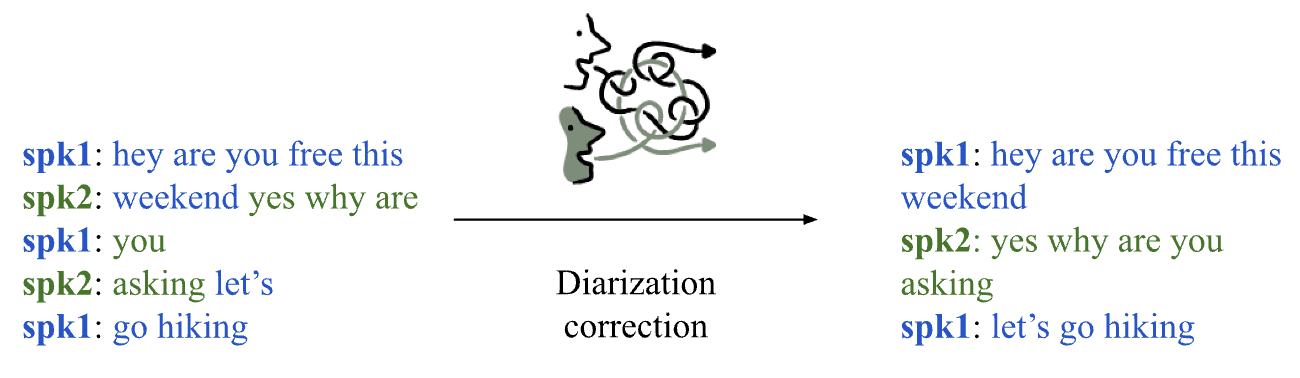
LLM-based speaker diarization correction: A generalizable approach
Georgios Efstathiadis, Vijay Yadav, Anzar Abbas
0
0
Speaker diarization is necessary for interpreting conversations transcribed using automated speech recognition (ASR) tools. Despite significant developments in diarization methods, diarization accuracy remains an issue. Here, we investigate the use of large language models (LLMs) for diarization correction as a post-processing step. LLMs were fine-tuned using the Fisher corpus, a large dataset of transcribed conversations. The ability of the models to improve diarization accuracy in a holdout dataset was measured. We report that fine-tuned LLMs can markedly improve diarization accuracy. However, model performance is constrained to transcripts produced using the same ASR tool as the transcripts used for fine-tuning, limiting generalizability. To address this constraint, an ensemble model was developed by combining weights from three separate models, each fine-tuned using transcripts from a different ASR tool. The ensemble model demonstrated better overall performance than each of the ASR-specific models, suggesting that a generalizable and ASR-agnostic approach may be achievable. We hope to make these models accessible through public-facing APIs for use by third-party applications.
6/10/2024

Discrete Multimodal Transformers with a Pretrained Large Language Model for Mixed-Supervision Speech Processing
Viet Anh Trinh, Rosy Southwell, Yiwen Guan, Xinlu He, Zhiyong Wang, Jacob Whitehill
0
0
Recent work on discrete speech tokenization has paved the way for models that can seamlessly perform multiple tasks across modalities, e.g., speech recognition, text to speech, speech to speech translation. Moreover, large language models (LLMs) pretrained from vast text corpora contain rich linguistic information that can improve accuracy in a variety of tasks. In this paper, we present a decoder-only Discrete Multimodal Language Model (DMLM), which can be flexibly applied to multiple tasks (ASR, T2S, S2TT, etc.) and modalities (text, speech, vision). We explore several critical aspects of discrete multi-modal models, including the loss function, weight initialization, mixed training supervision, and codebook. Our results show that DMLM benefits significantly, across multiple tasks and datasets, from a combination of supervised and unsupervised training. Moreover, for ASR, it benefits from initializing DMLM from a pretrained LLM, and from a codebook derived from Whisper activations.
6/26/2024