Transforming LLMs into Cross-modal and Cross-lingual RetrievalSystems
2404.01616
0
0

Abstract
Large language models (LLMs) are trained on text-only data that go far beyond the languages with paired speech and text data. At the same time, Dual Encoder (DE) based retrieval systems project queries and documents into the same embedding space and have demonstrated their success in retrieval and bi-text mining. To match speech and text in many languages, we propose using LLMs to initialize multi-modal DE retrieval systems. Unlike traditional methods, our system doesn't require speech data during LLM pre-training and can exploit LLM's multilingual text understanding capabilities to match speech and text in languages unseen during retrieval training. Our multi-modal LLM-based retrieval system is capable of matching speech and text in 102 languages despite only training on 21 languages. Our system outperforms previous systems trained explicitly on all 102 languages. We achieve a 10% absolute improvement in Recall@1 averaged across these languages. Additionally, our model demonstrates cross-lingual speech and text matching, which is further enhanced by readily available machine translation data.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a method for transforming large language models (LLMs) into cross-modal and cross-lingual retrieval systems.
- The approach involves generating audio tokens from text inputs, allowing the LLM to process and retrieve both text and audio data.
- The system is designed to enable retrieval across different modalities (text, audio) and languages.
Plain English Explanation
The researchers have developed a way to enhance large language models, which are advanced AI systems trained on vast amounts of text data, to work with audio data as well. Typically, these models are limited to processing written text, but the researchers have found a method to generate "audio tokens" from text inputs.
This allows the language model to understand and retrieve information not just from text, but also from audio sources. The system can now handle cross-modal retrieval, meaning it can search for and retrieve relevant information regardless of whether it's in text or audio format.
Additionally, the model is also designed to work across multiple languages. This means the system can retrieve information in different languages, enabling cross-lingual retrieval. For example, you could ask the system a question in English and it could find relevant information in a different language, like Mandarin.
The key advantage of this approach is that it expands the capabilities of powerful language models to handle more diverse data sources. Instead of being limited to text, these models can now work with audio as well, opening up new possibilities for applications like voice-based search, language learning, and audio-visual analysis.
Technical Explanation
The researchers' method involves two key steps:
-
Generating audio tokens: They use a pre-trained speech recognition model to generate audio embeddings, or numerical representations, from text inputs. This allows the language model to process both text and the corresponding audio information.
-
Integrating audio tokens into the language model: The audio tokens are then combined with the text tokens inside the LLM architecture. This enables the model to learn cross-modal associations between text and audio, and perform retrieval across these modalities.
To evaluate the approach, the researchers tested the system on several cross-modal and cross-lingual retrieval tasks. The results showed that the enhanced LLM outperformed baseline models that were limited to a single modality or language.
Critical Analysis
The paper provides a compelling approach for expanding the capabilities of large language models. Enabling these powerful AI systems to work with audio data as well as text is a significant advancement, as it unlocks new applications in areas like voice interfaces, multimedia analysis, and multilingual information retrieval.
However, the paper does not address potential limitations or challenges with the approach. For example, it's unclear how well the system would perform in real-world scenarios with noisy or low-quality audio inputs. Additionally, the reliance on a pre-trained speech recognition model could introduce biases or errors that impact the overall system performance.
Further research is needed to understand the robustness and generalizability of this approach, as well as its computational and resource requirements. Exploring the tradeoffs and potential pitfalls will be important for ensuring the practical deployment of such cross-modal and cross-lingual retrieval systems.
Conclusion
This paper presents a novel method for enhancing large language models to work with both text and audio data, enabling cross-modal and cross-lingual retrieval capabilities. By generating audio tokens and integrating them into the LLM architecture, the researchers have demonstrated a promising approach for expanding the versatility and applicability of these powerful AI systems. While further research is needed to address potential limitations, this work represents an important step forward in the development of more flexible and multilingual information retrieval technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Review of Multi-Modal Large Language and Vision Models
Kilian Carolan, Laura Fennelly, Alan F. Smeaton
0
0
Large Language Models (LLMs) have recently emerged as a focal point of research and application, driven by their unprecedented ability to understand and generate text with human-like quality. Even more recently, LLMs have been extended into multi-modal large language models (MM-LLMs) which extends their capabilities to deal with image, video and audio information, in addition to text. This opens up applications like text-to-video generation, image captioning, text-to-speech, and more and is achieved either by retro-fitting an LLM with multi-modal capabilities, or building a MM-LLM from scratch. This paper provides an extensive review of the current state of those LLMs with multi-modal capabilities as well as the very recent MM-LLMs. It covers the historical development of LLMs especially the advances enabled by transformer-based architectures like OpenAI's GPT series and Google's BERT, as well as the role of attention mechanisms in enhancing model performance. The paper includes coverage of the major and most important of the LLMs and MM-LLMs and also covers the techniques of model tuning, including fine-tuning and prompt engineering, which tailor pre-trained models to specific tasks or domains. Ethical considerations and challenges, such as data bias and model misuse, are also analysed to underscore the importance of responsible AI development and deployment. Finally, we discuss the implications of open-source versus proprietary models in AI research. Through this review, we provide insights into the transformative potential of MM-LLMs in various applications.
4/3/2024
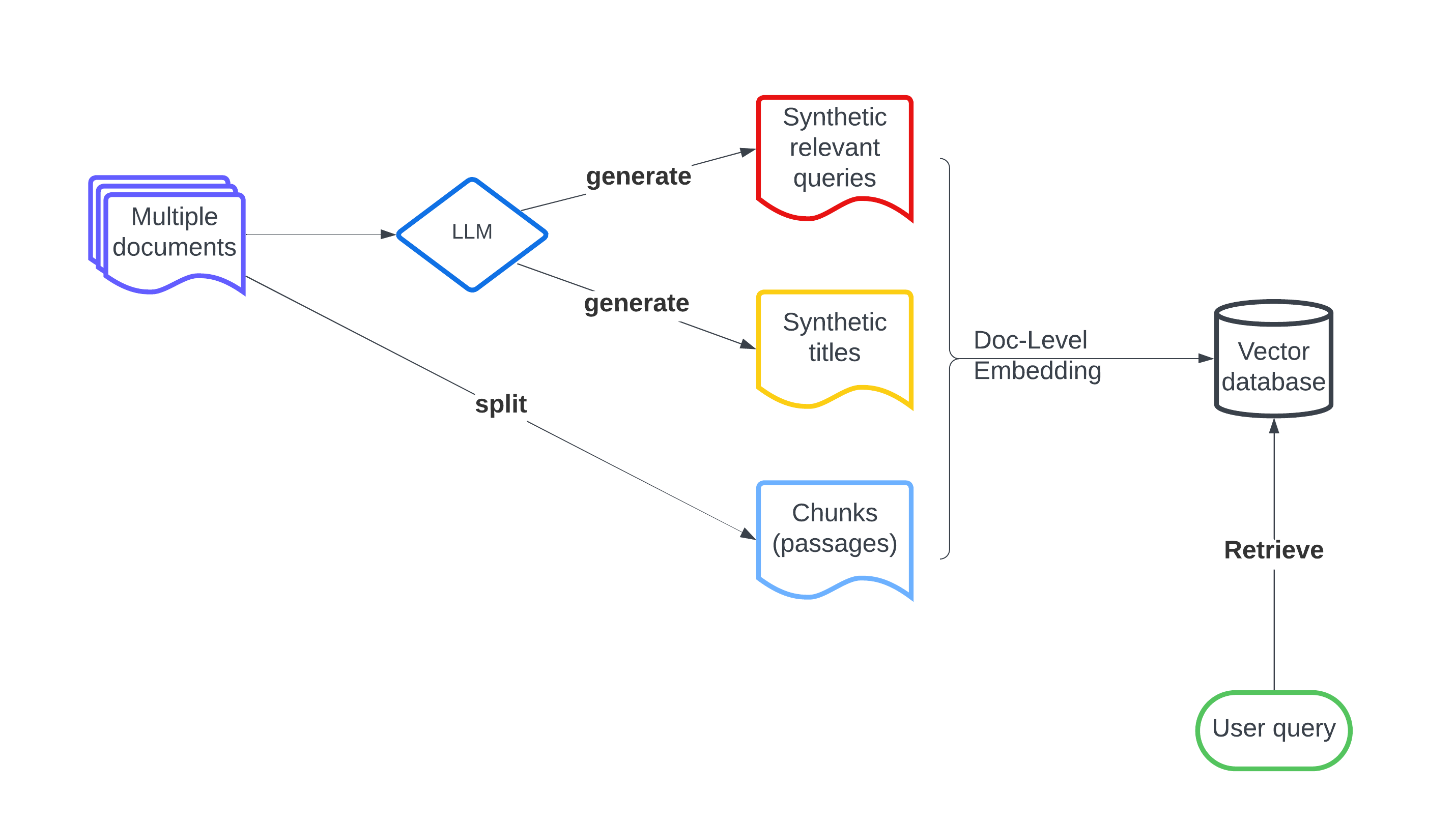
LLM-Augmented Retrieval: Enhancing Retrieval Models Through Language Models and Doc-Level Embedding
Mingrui Wu, Sheng Cao
0
0
Recently embedding-based retrieval or dense retrieval have shown state of the art results, compared with traditional sparse or bag-of-words based approaches. This paper introduces a model-agnostic doc-level embedding framework through large language model (LLM) augmentation. In addition, it also improves some important components in the retrieval model training process, such as negative sampling, loss function, etc. By implementing this LLM-augmented retrieval framework, we have been able to significantly improve the effectiveness of widely-used retriever models such as Bi-encoders (Contriever, DRAGON) and late-interaction models (ColBERTv2), thereby achieving state-of-the-art results on LoTTE datasets and BEIR datasets.
4/10/2024
💬
Large Language Models for Expansion of Spoken Language Understanding Systems to New Languages
Jakub Hoscilowicz, Pawel Pawlowski, Marcin Skorupa, Marcin Sowa'nski, Artur Janicki
0
0
Spoken Language Understanding (SLU) models are a core component of voice assistants (VA), such as Alexa, Bixby, and Google Assistant. In this paper, we introduce a pipeline designed to extend SLU systems to new languages, utilizing Large Language Models (LLMs) that we fine-tune for machine translation of slot-annotated SLU training data. Our approach improved on the MultiATIS++ benchmark, a primary multi-language SLU dataset, in the cloud scenario using an mBERT model. Specifically, we saw an improvement in the Overall Accuracy metric: from 53% to 62.18%, compared to the existing state-of-the-art method, Fine and Coarse-grained Multi-Task Learning Framework (FC-MTLF). In the on-device scenario (tiny and not pretrained SLU), our method improved the Overall Accuracy from 5.31% to 22.06% over the baseline Global-Local Contrastive Learning Framework (GL-CLeF) method. Contrary to both FC-MTLF and GL-CLeF, our LLM-based machine translation does not require changes in the production architecture of SLU. Additionally, our pipeline is slot-type independent: it does not require any slot definitions or examples.
4/4/2024
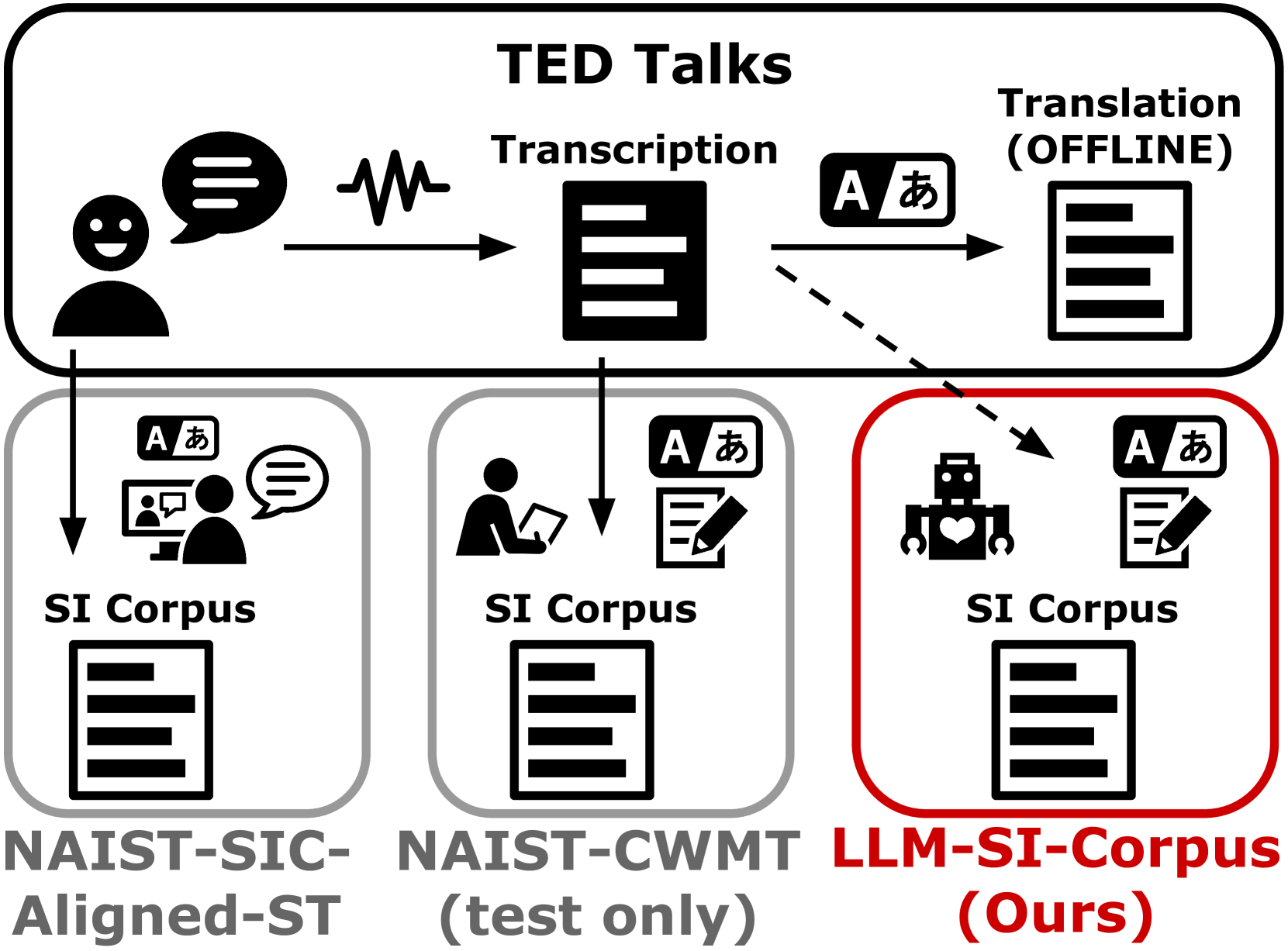
Simultaneous Interpretation Corpus Construction by Large Language Models in Distant Language Pair
Yusuke Sakai, Mana Makinae, Hidetaka Kamigaito, Taro Watanabe
0
0
In Simultaneous Machine Translation (SiMT) systems, training with a simultaneous interpretation (SI) corpus is an effective method for achieving high-quality yet low-latency systems. However, it is very challenging to curate such a corpus due to limitations in the abilities of annotators, and hence, existing SI corpora are limited. Therefore, we propose a method to convert existing speech translation corpora into interpretation-style data, maintaining the original word order and preserving the entire source content using Large Language Models (LLM-SI-Corpus). We demonstrate that fine-tuning SiMT models in text-to-text and speech-to-text settings with the LLM-SI-Corpus reduces latencies while maintaining the same level of quality as the models trained with offline datasets. The LLM-SI-Corpus is available at url{https://github.com/yusuke1997/LLM-SI-Corpus}.
4/19/2024