DenseFusion-1M: Merging Vision Experts for Comprehensive Multimodal Perception

0

Sign in to get full access
Overview
- The paper proposes a novel multimodal perception model called "DenseFusion-1M" that combines the strengths of various vision experts to achieve comprehensive multimodal understanding.
- The model leverages existing vision models trained on large-scale datasets, such as image classification, object detection, and image-text matching, to build a robust and versatile multimodal perception system.
- The key innovations include a dense fusion mechanism that seamlessly integrates the outputs of different vision experts and a specialized training procedure to leverage the complementary strengths of these experts.
Plain English Explanation
The paper presents a new model called "DenseFusion-1M" that can understand and analyze images and text in a comprehensive way. The model takes advantage of existing specialized vision models, such as those trained to classify images or detect objects, and combines their outputs to create a more powerful and well-rounded system.
Rather than relying on a single vision model, the researchers have developed a way to "fuse" the outputs of multiple experts together, allowing the model to draw on the different strengths of each one. For example, one expert may be great at recognizing objects, while another excels at understanding the relationships between objects in an image.
By merging these complementary capabilities, the DenseFusion-1M model can gain a deeper and more nuanced understanding of the visual world, which could be useful for a wide range of applications, from autonomous vehicles to assistive technologies. The researchers have also developed a specialized training process to help the model learn how to effectively utilize the information from these various vision experts.
Technical Explanation
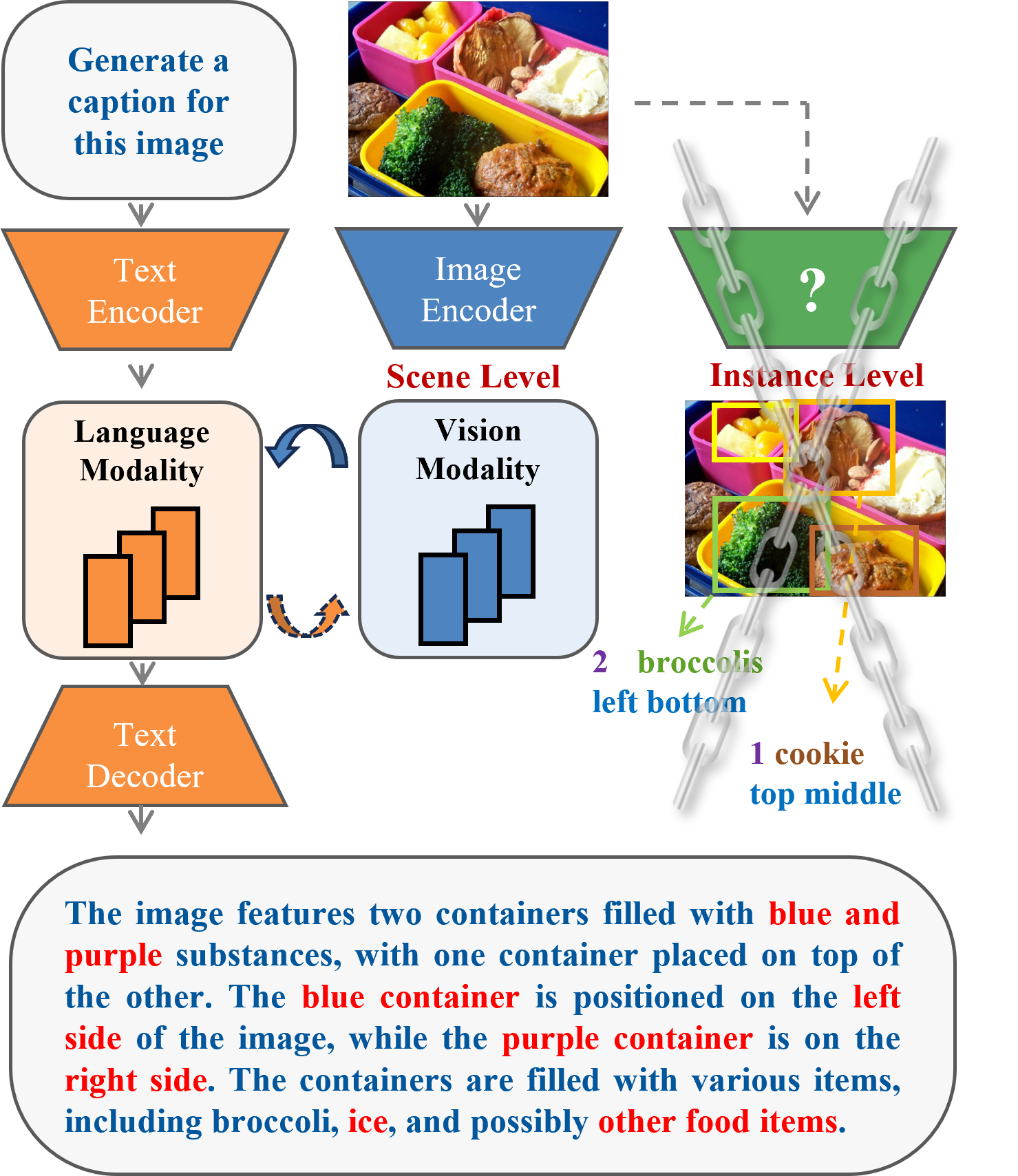
The paper proposes a novel multimodal perception model called "DenseFusion-1M" that leverages the strengths of various vision experts to achieve comprehensive multimodal understanding. The key innovations include:
-
Dense Fusion Mechanism: The model employs a dense fusion mechanism that seamlessly integrates the outputs of different vision experts, such as image classification models (MR-MLLM), object detection models (Enhancing MLLM), and image-text matching models (CapsFusion). This allows the model to draw on the complementary strengths of these experts to build a robust and versatile multimodal perception system.
-
Specialized Training Procedure: The researchers have developed a specialized training procedure to effectively leverage the knowledge from these various vision experts. This involves carefully aligning and fusing the outputs of the different experts during the training process, enabling the model to learn how to optimally utilize the information from each expert.
The technical details of the model architecture and training process are described in the paper, including the specific neural network layers and optimization techniques used. The researchers also present extensive experimental results, demonstrating the superior performance of DenseFusion-1M on a range of multimodal benchmarks compared to existing state-of-the-art models.
Critical Analysis
The paper presents a well-designed and comprehensive approach to building a multimodal perception system. The dense fusion mechanism and specialized training procedure are novel contributions that could significantly advance the field of multimodal learning.
However, the paper does not address some potential limitations and areas for further research. For instance, the performance and scalability of the model when dealing with larger and more diverse datasets, or the interpretability of the fused representations (Explaining MLLM), are not thoroughly explored.
Additionally, the paper could have provided more insights into the specific trade-offs and synergies between the different vision experts, and how the dense fusion process mitigates their individual weaknesses. A deeper analysis of the model's strengths and weaknesses in different multimodal tasks would also help readers understand the broader implications of this research.
Conclusion
The DenseFusion-1M model presented in this paper represents a significant advancement in the field of multimodal perception. By leveraging the complementary strengths of various vision experts, the model is able to achieve a more comprehensive and robust understanding of the visual world, with potential applications in a wide range of domains.
The dense fusion mechanism and specialized training procedure are innovative contributions that could inspire future research in multimodal learning. While the paper doesn't address all potential limitations, it lays a solid foundation for further exploring the synergies between different vision models and developing more advanced multimodal perception systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DenseFusion-1M: Merging Vision Experts for Comprehensive Multimodal Perception
Xiaotong Li, Fan Zhang, Haiwen Diao, Yueze Wang, Xinlong Wang, Ling-Yu Duan
Existing Multimodal Large Language Models (MLLMs) increasingly emphasize complex understanding of various visual elements, including multiple objects, text information, and spatial relations. Their development for comprehensive visual perception hinges on the availability of high-quality image-text datasets that offer diverse visual elements and throughout image descriptions. However, the scarcity of such hyper-detailed datasets currently hinders progress within the MLLM community. The bottleneck stems from the limited perceptual capabilities of current caption engines, which fall short in providing complete and accurate annotations. To facilitate the cutting-edge research of MLLMs on comprehensive vision perception, we thereby propose Perceptual Fusion, using a low-budget but highly effective caption engine for complete and accurate image descriptions. Specifically, Perceptual Fusion integrates diverse perception experts as image priors to provide explicit information on visual elements and adopts an efficient MLLM as a centric pivot to mimic advanced MLLMs' perception abilities. We carefully select 1M highly representative images from uncurated LAION dataset and generate dense descriptions using our engine, dubbed DenseFusion-1M. Extensive experiments validate that our engine outperforms its counterparts, where the resulting dataset significantly improves the perception and cognition abilities of existing MLLMs across diverse vision-language benchmarks, especially with high-resolution images as inputs. The dataset and code are publicly available at https://github.com/baaivision/DenseFusion.
Read more7/12/2024
0
MR-MLLM: Mutual Reinforcement of Multimodal Comprehension and Vision Perception
Guanqun Wang, Xinyu Wei, Jiaming Liu, Ray Zhang, Yichi Zhang, Kevin Zhang, Maurice Chong, Shanghang Zhang
In recent years, multimodal large language models (MLLMs) have shown remarkable capabilities in tasks like visual question answering and common sense reasoning, while visual perception models have made significant strides in perception tasks, such as detection and segmentation. However, MLLMs mainly focus on high-level image-text interpretations and struggle with fine-grained visual understanding, and vision perception models usually suffer from open-world distribution shifts due to their limited model capacity. To overcome these challenges, we propose the Mutually Reinforced Multimodal Large Language Model (MR-MLLM), a novel framework that synergistically enhances visual perception and multimodal comprehension. First, a shared query fusion mechanism is proposed to harmonize detailed visual inputs from vision models with the linguistic depth of language models, enhancing multimodal comprehension and vision perception synergistically. Second, we propose the perception-enhanced cross-modal integration method, incorporating novel modalities from vision perception outputs, like object detection bounding boxes, to capture subtle visual elements, thus enriching the understanding of both visual and textual data. In addition, an innovative perception-embedded prompt generation mechanism is proposed to embed perceptual information into the language model's prompts, aligning the responses contextually and perceptually for a more accurate multimodal interpretation. Extensive experiments demonstrate MR-MLLM's superior performance in various multimodal comprehension and vision perception tasks, particularly those requiring corner case vision perception and fine-grained language comprehension.
Read more6/26/2024

0
Enhancing Multimodal Large Language Models with Vision Detection Models: An Empirical Study
Qirui Jiao, Daoyuan Chen, Yilun Huang, Yaliang Li, Ying Shen
Despite the impressive capabilities of Multimodal Large Language Models (MLLMs) in integrating text and image modalities, challenges remain in accurately interpreting detailed visual elements. This paper presents an empirical study on enhancing MLLMs with state-of-the-art (SOTA) object detection and Optical Character Recognition (OCR) models to improve fine-grained understanding and reduce hallucination in responses. We investigate the embedding-based infusion of textual detection information, the impact of such infusion on MLLMs' original abilities, and the interchangeability of detection models. We conduct systematic and extensive experiments with representative models such as LLaVA-1.5, DINO, PaddleOCRv2, and Grounding DINO, revealing that our simple yet general approach not only refines MLLMs' performance in fine-grained visual tasks but also maintains their original strengths. Notably, the enhanced LLaVA-1.5 outperforms its original 7B/13B models on all 10 benchmarks, achieving an improvement of up to 12.5% on the normalized average score. We release our codes to facilitate further exploration into the fine-grained multimodal capabilities of MLLMs.
Read more5/31/2024
💬
0
Explaining Multi-modal Large Language Models by Analyzing their Vision Perception
Loris Giulivi, Giacomo Boracchi
Multi-modal Large Language Models (MLLMs) have demonstrated remarkable capabilities in understanding and generating content across various modalities, such as images and text. However, their interpretability remains a challenge, hindering their adoption in critical applications. This research proposes a novel approach to enhance the interpretability of MLLMs by focusing on the image embedding component. We combine an open-world localization model with a MLLM, thus creating a new architecture able to simultaneously produce text and object localization outputs from the same vision embedding. The proposed architecture greatly promotes interpretability, enabling us to design a novel saliency map to explain any output token, to identify model hallucinations, and to assess model biases through semantic adversarial perturbations.
Read more5/29/2024