Dependence Analysis and Structured Construction for Batched Sparse Code

0
Sign in to get full access
Overview
- This paper presents a new approach for constructing batched sparse code, which is important for efficient machine learning and data processing on hardware like GPUs and CPUs.
- The key ideas are using a structured dependence analysis to organize the code in a way that improves performance, and a new construction method to generate the batched sparse code.
- The paper demonstrates how this approach can outperform existing methods on several benchmarks, making it a promising technique for improving the efficiency of machine learning and data processing workloads.
Plain English Explanation
When working with large datasets or complex machine learning models, it's important to be able to process the data efficiently, especially on hardware like graphics processors (GPUs) and regular processors (CPUs). One way to do this is through a technique called "batched sparse code", which organizes the data and computations in a way that reduces the amount of work required.
This paper introduces a new method for constructing batched sparse code that has some key advantages. First, the authors use a "structured dependence analysis" to understand how the different parts of the code depend on each other. This allows them to organize the code in a way that improves performance, by minimizing the amount of unnecessary work that needs to be done.
Second, the paper describes a new "construction method" for generating the batched sparse code itself. This method is designed to produce code that is more efficient and can take better advantage of the capabilities of modern hardware like GPUs and CPUs.
The authors demonstrate that this new approach to batched sparse code can outperform existing methods on a variety of benchmark tests. This suggests that it could be a valuable tool for improving the efficiency of machine learning and other data-intensive applications, helping to make them run faster and use less power.
Technical Explanation
The key technical contributions of this paper are:
-
Structured Dependence Analysis: The authors develop a new method for analyzing the dependencies between different parts of the batched sparse code. This allows them to organize the code in a way that minimizes redundant computations and improves overall efficiency.
-
Batched Sparse Code Construction: Building on the dependence analysis, the paper introduces a new technique for constructing the batched sparse code itself. This construction method is designed to produce code that can better leverage the parallel processing capabilities of modern hardware like GPUs.
-
Experimental Evaluation: The authors evaluate their approach on several benchmark tasks, demonstrating that it can outperform existing methods for batched sparse code generation. This includes improvements in terms of runtime, memory usage, and energy efficiency.
The structured dependence analysis works by modeling the relationships between different sparse matrix elements and the computations that operate on them. This allows the code construction process to avoid redundant work and organize the computations in a way that maximizes parallelism.
The new construction method takes advantage of this dependence analysis to generate batched sparse code with an optimized structure. This includes techniques like reordering computations, fusing related operations, and exploiting specific hardware features to improve performance.
Overall, this paper presents a promising approach for improving the efficiency of machine learning and other data-intensive applications that rely on batched sparse computations. The techniques developed could have broader applicability in areas like structured probabilistic coding, error-correcting codes, and [distributed learning](https://aimodels.fyi/papers/arxiv/coded-computing-learning-theoretic-framework, https://aimodels.fyi/papers/arxiv/design-optimization-hierarchical-gradient-coding-distributed-learning).
Critical Analysis
The paper presents a well-designed and thoroughly evaluated approach for improving the efficiency of batched sparse code. However, there are a few potential limitations and areas for further research that could be explored:
-
Hardware Specificity: The paper focuses on optimizing batched sparse code for modern CPUs and GPUs. While this is an important target, the techniques may not generalize as well to other hardware architectures or specialized accelerators.
-
Sparsity Patterns: The paper assumes a certain structure and distribution of sparsity in the input data. It's not clear how well the approach would perform on more irregular or dynamic sparsity patterns that may arise in real-world applications.
-
Compiler Integration: The authors mention that their approach could be integrated into existing compilers, but they don't provide details on how this might be accomplished. Seamless integration with popular compiler frameworks could be an important next step for practical adoption.
-
Broader Applications: While the paper demonstrates the benefits of this approach for machine learning workloads, the techniques may have applications in other domains that rely on batched sparse computations, such as distributed sparse block codes. Exploring these broader use cases could further validate the generality of the proposed methods.
Overall, this paper presents a compelling and well-executed approach for improving the efficiency of batched sparse code. The structured dependence analysis and code construction techniques are innovative and could have a significant impact on the performance of machine learning and other data-intensive applications. With further research to address the potential limitations, this work could become an important contribution to the field.
Conclusion
This paper introduces a new method for constructing batched sparse code that outperforms existing approaches. The key ideas are a structured dependence analysis to organize the code in an efficient way, and a new construction technique that can better leverage the capabilities of modern hardware like GPUs and CPUs.
The experimental results demonstrate significant improvements in runtime, memory usage, and energy efficiency compared to previous methods for batched sparse code generation. This suggests that the techniques developed in this paper could be valuable tools for improving the performance of machine learning and other data-intensive applications.
While the paper focuses on specific hardware targets, the general principles of structured dependence analysis and optimized code construction could have broader applicability in areas like structured probabilistic coding, error-correcting codes, and distributed learning. Further research to address potential limitations and explore these wider use cases could help solidify the impact of this work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dependence Analysis and Structured Construction for Batched Sparse Code
Jiaxin Qing, Xiaohong Cai, Yijun Fan, Mingyang Zhu, Raymond W. Yeung
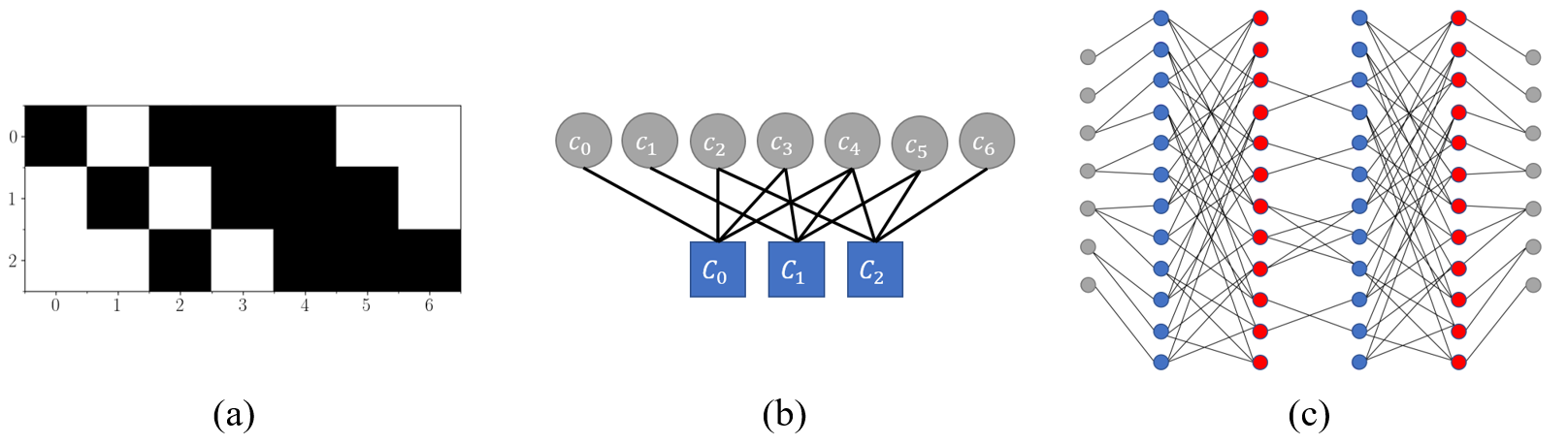
In coding theory, codes are usually designed with a certain level of randomness to facilitate analysis and accommodate different channel conditions. However, the resulting random code constructed can be suboptimal in practical implementations. Represented by a bipartite graph, the Batched Sparse Code (BATS Code) is a randomly constructed erasure code that utilizes network coding to achieve near-optimal performance in wireless multi-hop networks. In the performance analysis in the previous research, it is implicitly assumed that the coded batches in the BATS code are independent. This assumption holds only asymptotically when the number of input symbols is infinite, but it does not generally hold in a practical setting where the number of input symbols is finite, especially when the code is constructed randomly. We show that dependence among the batches significantly degrades the code's performance. In order to control the batch dependence through graphical design, we propose constructing the BATS code in a structured manner. A hardware-friendly structured BATS code called the Cyclic-Shift BATS (CS-BATS) code is proposed, which constructs the code from a small base graph using light-weight cyclic-shift operations. We demonstrate that when the base graph is properly designed, a higher decoding rate and a smaller complexity can be achieved compared with the random BATS code.
Read more6/27/2024

0
Structured Probabilistic Coding
Dou Hu, Lingwei Wei, Yaxin Liu, Wei Zhou, Songlin Hu
This paper presents a new supervised representation learning framework, namely structured probabilistic coding (SPC), to learn compact and informative representations from input related to the target task. SPC is an encoder-only probabilistic coding technology with a structured regularization from the target space. It can enhance the generalization ability of pre-trained language models for better language understanding. Specifically, our probabilistic coding simultaneously performs information encoding and task prediction in one module to more fully utilize the effective information from input data. It uses variational inference in the output space to reduce randomness and uncertainty. Besides, to better control the learning process of probabilistic representations, a structured regularization is proposed to promote uniformity across classes in the latent space. With the regularization term, SPC can preserve the Gaussian structure of the latent code and achieve better coverage of the hidden space with class uniformly. Experimental results on 12 natural language understanding tasks demonstrate that our SPC effectively improves the performance of pre-trained language models for classification and regression. Extensive experiments show that SPC can enhance the generalization capability, robustness to label noise, and clustering quality of output representations.
Read more5/3/2024
0
Factor Graph Optimization of Error-Correcting Codes for Belief Propagation Decoding
Yoni Choukroun, Lior Wolf
The design of optimal linear block codes capable of being efficiently decoded is of major concern, especially for short block lengths. As near capacity-approaching codes, Low-Density Parity-Check (LDPC) codes possess several advantages over other families of codes, the most notable being its efficient decoding via Belief Propagation. While many LDPC code design methods exist, the development of efficient sparse codes that meet the constraints of modern short code lengths and accommodate new channel models remains a challenge. In this work, we propose for the first time a data-driven approach for the design of sparse codes. We develop locally optimal codes with respect to Belief Propagation decoding via the learning on the Factor graph (also called the Tanner graph) under channel noise simulations. This is performed via a novel tensor representation of the Belief Propagation algorithm, optimized over finite fields via backpropagation coupled with an efficient line-search method. The proposed approach is shown to outperform the decoding performance of existing popular codes by orders of magnitude and demonstrates the power of data-driven approaches for code design.
Read more6/21/2024
📊
0
Entropy Coding of Unordered Data Structures
Julius Kunze, Daniel Severo, Giulio Zani, Jan-Willem van de Meent, James Townsend
We present shuffle coding, a general method for optimal compression of sequences of unordered objects using bits-back coding. Data structures that can be compressed using shuffle coding include multisets, graphs, hypergraphs, and others. We release an implementation that can easily be adapted to different data types and statistical models, and demonstrate that our implementation achieves state-of-the-art compression rates on a range of graph datasets including molecular data.
Read more8/19/2024