Detecting Dataset Abuse in Fine-Tuning Stable Diffusion Models for Text-to-Image Synthesis

0
⚙️
Sign in to get full access
Overview
- Text-to-image synthesis is a popular technique for generating realistic and stylized images.
- Researchers often fine-tune generative models with domain-specific datasets for specialized tasks.
- These valuable datasets face risks of unauthorized usage and unapproved sharing, compromising the rights of the owners.
Plain English Explanation
The paper focuses on the issue of dataset abuse during the fine-tuning of Stable Diffusion models for text-to-image synthesis. The researchers present a dataset watermarking framework designed to detect unauthorized usage and trace data leaks. This framework employs two key strategies across multiple watermarking schemes, proving effective for large-scale dataset authorization.
Technical Explanation
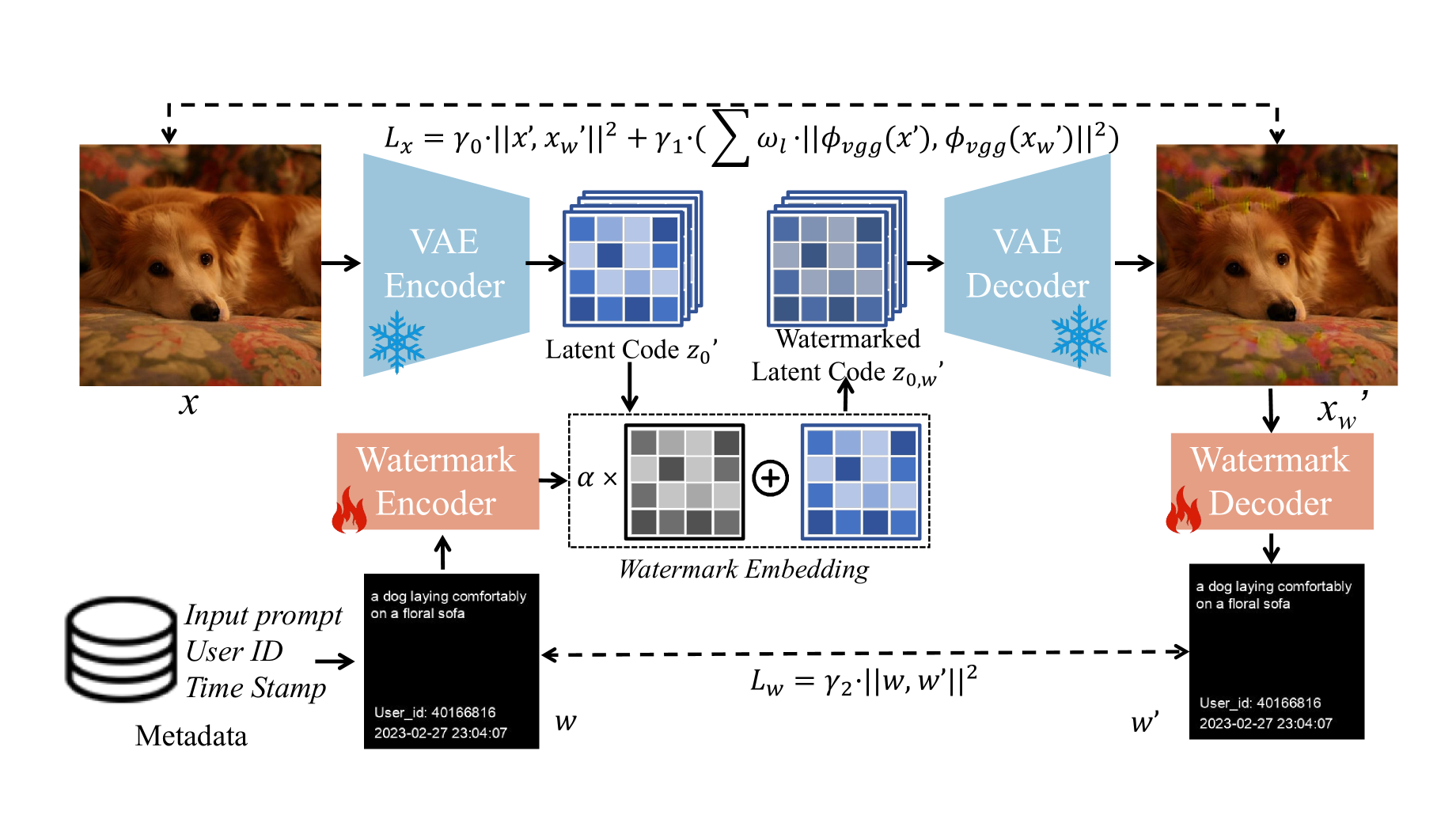
The researchers developed a dataset watermarking framework to address the issue of dataset abuse during the fine-tuning of Stable Diffusion models for text-to-image synthesis. The framework employs two key strategies:
- Watermarking the dataset across multiple schemes to increase detection accuracy and robustness.
- Ensuring the framework has minimal impact on the dataset, with only 2% of the data requiring modification for high detection accuracy.
Extensive experiments demonstrate the framework's effectiveness in tracing data leaks and its practical applicability in detecting dataset abuse.
Critical Analysis
The paper addresses an important issue in the field of text-to-image synthesis, where valuable datasets face the risk of unauthorized usage and unapproved sharing. The proposed watermarking framework is a practical solution that effectively detects dataset abuse and traces data leaks.
However, the paper could have provided more details on the specific watermarking schemes used and their individual strengths and weaknesses. Additionally, it would be helpful to understand the potential limitations of the framework, such as its performance against advanced data obfuscation techniques or its ability to handle large-scale leaks.
Further research could explore the framework's adaptability to different types of generative models and domains beyond text-to-image synthesis. Investigating the framework's resilience against adversarial attacks or its integration with other data protection mechanisms could also be valuable.
Conclusion
The paper presents a compelling dataset watermarking framework that addresses the critical issue of dataset abuse in text-to-image synthesis. The framework's effectiveness, minimal impact on the dataset, and ability to trace data leaks highlight its practical applicability in protecting the rights of dataset owners. This research paves the way for more robust data protection strategies in the rapidly evolving field of generative AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
0
Detecting Dataset Abuse in Fine-Tuning Stable Diffusion Models for Text-to-Image Synthesis
Songrui Wang, Yubo Zhu, Wei Tong, Sheng Zhong
Text-to-image synthesis has become highly popular for generating realistic and stylized images, often requiring fine-tuning generative models with domain-specific datasets for specialized tasks. However, these valuable datasets face risks of unauthorized usage and unapproved sharing, compromising the rights of the owners. In this paper, we address the issue of dataset abuse during the fine-tuning of Stable Diffusion models for text-to-image synthesis. We present a dataset watermarking framework designed to detect unauthorized usage and trace data leaks. The framework employs two key strategies across multiple watermarking schemes and is effective for large-scale dataset authorization. Extensive experiments demonstrate the framework's effectiveness, minimal impact on the dataset (only 2% of the data required to be modified for high detection accuracy), and ability to trace data leaks. Our results also highlight the robustness and transferability of the framework, proving its practical applicability in detecting dataset abuse.
Read more9/30/2024
📊
0
DIAGNOSIS: Detecting Unauthorized Data Usages in Text-to-image Diffusion Models
Zhenting Wang, Chen Chen, Lingjuan Lyu, Dimitris N. Metaxas, Shiqing Ma
Recent text-to-image diffusion models have shown surprising performance in generating high-quality images. However, concerns have arisen regarding the unauthorized data usage during the training or fine-tuning process. One example is when a model trainer collects a set of images created by a particular artist and attempts to train a model capable of generating similar images without obtaining permission and giving credit to the artist. To address this issue, we propose a method for detecting such unauthorized data usage by planting the injected memorization into the text-to-image diffusion models trained on the protected dataset. Specifically, we modify the protected images by adding unique contents on these images using stealthy image warping functions that are nearly imperceptible to humans but can be captured and memorized by diffusion models. By analyzing whether the model has memorized the injected content (i.e., whether the generated images are processed by the injected post-processing function), we can detect models that had illegally utilized the unauthorized data. Experiments on Stable Diffusion and VQ Diffusion with different model training or fine-tuning methods (i.e, LoRA, DreamBooth, and standard training) demonstrate the effectiveness of our proposed method in detecting unauthorized data usages. Code: https://github.com/ZhentingWang/DIAGNOSIS.
Read more4/10/2024

0
FT-Shield: A Watermark Against Unauthorized Fine-tuning in Text-to-Image Diffusion Models
Yingqian Cui, Jie Ren, Yuping Lin, Han Xu, Pengfei He, Yue Xing, Lingjuan Lyu, Wenqi Fan, Hui Liu, Jiliang Tang
Text-to-image generative models, especially those based on latent diffusion models (LDMs), have demonstrated outstanding ability in generating high-quality and high-resolution images from textual prompts. With this advancement, various fine-tuning methods have been developed to personalize text-to-image models for specific applications such as artistic style adaptation and human face transfer. However, such advancements have raised copyright concerns, especially when the data are used for personalization without authorization. For example, a malicious user can employ fine-tuning techniques to replicate the style of an artist without consent. In light of this concern, we propose FT-Shield, a watermarking solution tailored for the fine-tuning of text-to-image diffusion models. FT-Shield addresses copyright protection challenges by designing new watermark generation and detection strategies. In particular, it introduces an innovative algorithm for watermark generation. It ensures the seamless transfer of watermarks from training images to generated outputs, facilitating the identification of copyrighted material use. To tackle the variability in fine-tuning methods and their impact on watermark detection, FT-Shield integrates a Mixture of Experts (MoE) approach for watermark detection. Comprehensive experiments validate the effectiveness of our proposed FT-Shield.
Read more5/7/2024
0
A Training-Free Plug-and-Play Watermark Framework for Stable Diffusion
Guokai Zhang, Lanjun Wang, Yuting Su, An-An Liu
Nowadays, the family of Stable Diffusion (SD) models has gained prominence for its high quality outputs and scalability. This has also raised security concerns on social media, as malicious users can create and disseminate harmful content. Existing approaches involve training components or entire SDs to embed a watermark in generated images for traceability and responsibility attribution. However, in the era of AI-generated content (AIGC), the rapid iteration of SDs renders retraining with watermark models costly. To address this, we propose a training-free plug-and-play watermark framework for SDs. Without modifying any components of SDs, we embed diverse watermarks in the latent space, adapting to the denoising process. Our experimental findings reveal that our method effectively harmonizes image quality and watermark invisibility. Furthermore, it performs robustly under various attacks. We also have validated that our method is generalized to multiple versions of SDs, even without retraining the watermark model.
Read more4/9/2024