Detecting Hallucinations in Large Language Model Generation: A Token Probability Approach
2405.19648
0
0

Abstract
Concerns regarding the propensity of Large Language Models (LLMs) to produce inaccurate outputs, also known as hallucinations, have escalated. Detecting them is vital for ensuring the reliability of applications relying on LLM-generated content. Current methods often demand substantial resources and rely on extensive LLMs or employ supervised learning with multidimensional features or intricate linguistic and semantic analyses difficult to reproduce and largely depend on using the same LLM that hallucinated. This paper introduces a supervised learning approach employing two simple classifiers utilizing only four numerical features derived from tokens and vocabulary probabilities obtained from other LLM evaluators, which are not necessarily the same. The method yields promising results, surpassing state-of-the-art outcomes in multiple tasks across three different benchmarks. Additionally, we provide a comprehensive examination of the strengths and weaknesses of our approach, highlighting the significance of the features utilized and the LLM employed as an evaluator. We have released our code publicly at https://github.com/Baylor-AI/HalluDetect.
Create account to get full access
Overview
- This paper proposes a method for detecting hallucinations in the output of large language models (LLMs).
- Hallucinations refer to the generation of content that is not grounded in the input or training data.
- The authors introduce a token probability approach to identify potentially hallucinated content in LLM-generated text.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can sometimes produce content that is not actually based on their training data, a phenomenon known as "hallucination." This paper describes a method to detect hallucinated content in LLM outputs.
The key idea is to look at the probability that the model assigns to each generated token. If the model assigns a very low probability to a token, it may indicate that the content is not well-grounded and could be hallucinated. The authors use this "token probability" approach to flag potentially hallucinated text.
This can be useful for applications like text summarization, where hallucinations could lead to inaccurate or misleading summaries. It can also help provide transparency into how LLMs are reasoning and generating content.
Technical Explanation
The paper first reviews related work on detecting hallucinations in LLMs, including approaches that look at semantic coherence or consistency with the input.
The authors then propose their token probability approach. For each token generated by the LLM, they calculate the probability the model assigns to that token. Tokens with very low probabilities are flagged as potentially hallucinated. This builds on the intuition that hallucinated content would likely have low model confidence.
The paper evaluates this approach on several benchmark datasets, including summarization and code generation tasks. The results show that the token probability method can effectively identify hallucinated content, outperforming alternative techniques.
Critical Analysis
The paper provides a promising approach for detecting hallucinations in LLM outputs. However, the authors acknowledge that the method has some limitations. For example, it may not work as well for very low-probability tokens that are nonetheless factually correct.
Additionally, the paper focuses on textual outputs, but hallucinations can also occur in multimodal LLMs that generate images or other content. Further research would be needed to extend the token probability approach to these domains.
Overall, this work represents an important step towards improving the transparency and reliability of large language models. By giving users better tools to identify hallucinated content, it can help build trust in these AI systems and enable more responsible application of their capabilities.
Conclusion
This paper introduces a token probability approach for detecting hallucinations in the output of large language models. By flagging low-probability tokens, the method can identify content that is not well-grounded in the model's training data. Evaluations show this technique outperforms alternative hallucination detection approaches.
While not a perfect solution, this work provides a useful tool for enhancing the reliability of LLM-generated text. As these models become more widely deployed, techniques like this will be crucial for building trust and ensuring their outputs are accurate and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Don't Believe Everything You Read: Enhancing Summarization Interpretability through Automatic Identification of Hallucinations in Large Language Models
Priyesh Vakharia, Devavrat Joshi, Meenal Chavan, Dhananjay Sonawane, Bhrigu Garg, Parsa Mazaheri
0
0
Large Language Models (LLMs) are adept at text manipulation -- tasks such as machine translation and text summarization. However, these models can also be prone to hallucination, which can be detrimental to the faithfulness of any answers that the model provides. Recent works in combating hallucinations in LLMs deal with identifying hallucinated sentences and categorizing the different ways in which models hallucinate. This paper takes a deep dive into LLM behavior with respect to hallucinations, defines a token-level approach to identifying different kinds of hallucinations, and further utilizes this token-level tagging to improve the interpretability and faithfulness of LLMs in dialogue summarization tasks. Through this, the paper presents a new, enhanced dataset and a new training paradigm.
4/4/2024
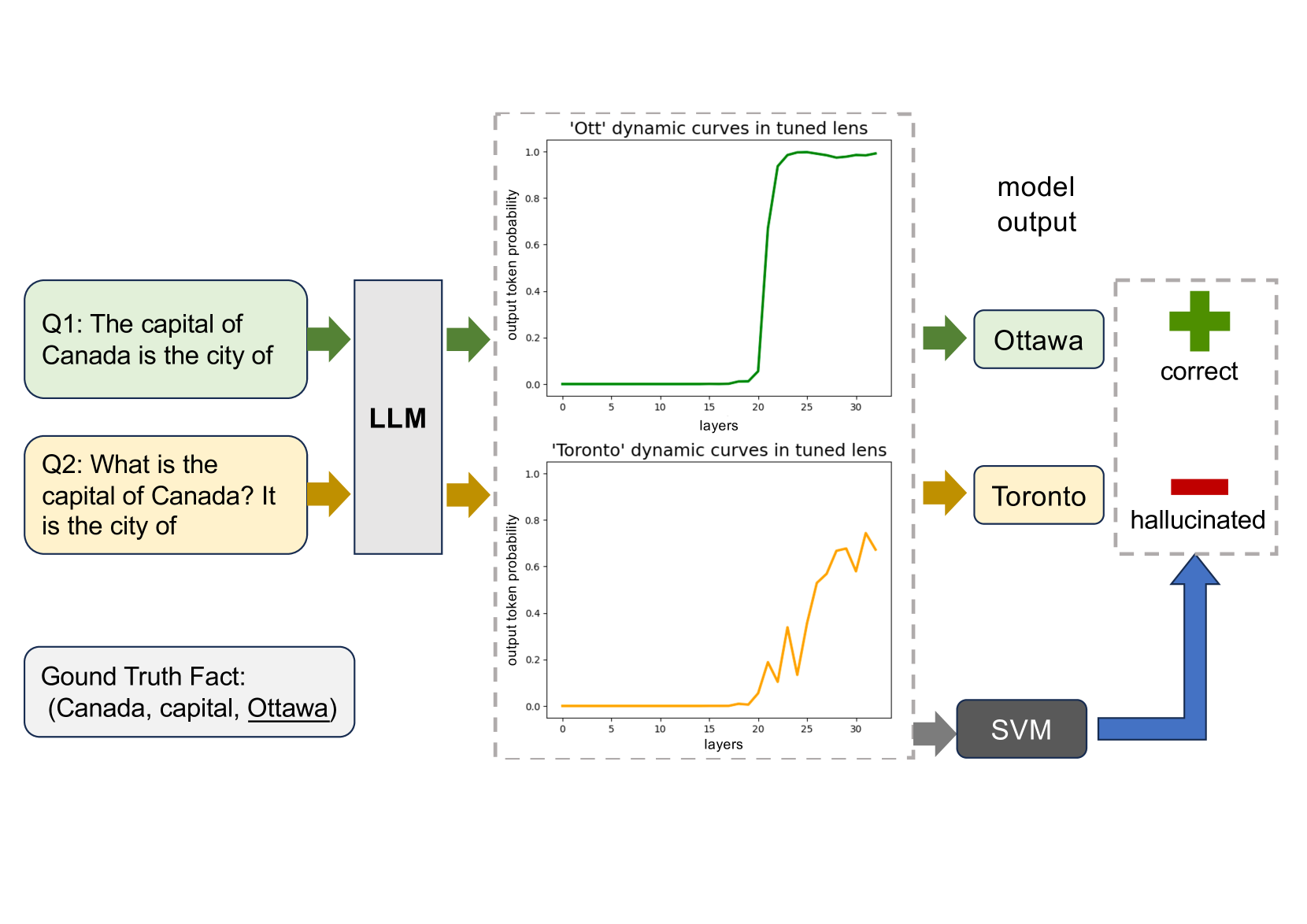
On Large Language Models' Hallucination with Regard to Known Facts
Che Jiang, Biqing Qi, Xiangyu Hong, Dayuan Fu, Yang Cheng, Fandong Meng, Mo Yu, Bowen Zhou, Jie Zhou
0
0
Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.
4/1/2024
💬
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, Mike Zheng Shou
0
0
This survey presents a comprehensive analysis of the phenomenon of hallucination in multimodal large language models (MLLMs), also known as Large Vision-Language Models (LVLMs), which have demonstrated significant advancements and remarkable abilities in multimodal tasks. Despite these promising developments, MLLMs often generate outputs that are inconsistent with the visual content, a challenge known as hallucination, which poses substantial obstacles to their practical deployment and raises concerns regarding their reliability in real-world applications. This problem has attracted increasing attention, prompting efforts to detect and mitigate such inaccuracies. We review recent advances in identifying, evaluating, and mitigating these hallucinations, offering a detailed overview of the underlying causes, evaluation benchmarks, metrics, and strategies developed to address this issue. Additionally, we analyze the current challenges and limitations, formulating open questions that delineate potential pathways for future research. By drawing the granular classification and landscapes of hallucination causes, evaluation benchmarks, and mitigation methods, this survey aims to deepen the understanding of hallucinations in MLLMs and inspire further advancements in the field. Through our thorough and in-depth review, we contribute to the ongoing dialogue on enhancing the robustness and reliability of MLLMs, providing valuable insights and resources for researchers and practitioners alike. Resources are available at: https://github.com/showlab/Awesome-MLLM-Hallucination.
4/30/2024
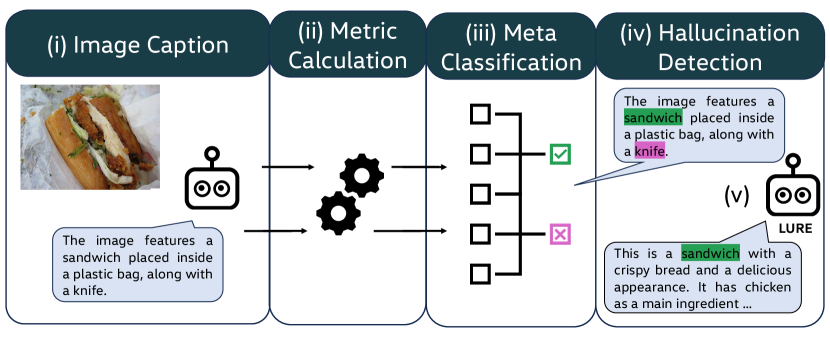
MetaToken: Detecting Hallucination in Image Descriptions by Meta Classification
Laura Fieback (Volkswagen AG, TU Berlin), Jakob Spiegelberg (Volkswagen AG), Hanno Gottschalk (TU Berlin)
0
0
Large Vision Language Models (LVLMs) have shown remarkable capabilities in multimodal tasks like visual question answering or image captioning. However, inconsistencies between the visual information and the generated text, a phenomenon referred to as hallucinations, remain an unsolved problem with regard to the trustworthiness of LVLMs. To address this problem, recent works proposed to incorporate computationally costly Large (Vision) Language Models in order to detect hallucinations on a sentence- or subsentence-level. In this work, we introduce MetaToken, a lightweight binary classifier to detect hallucinations on the token-level at negligible cost. Based on a statistical analysis, we reveal key factors of hallucinations in LVLMs which have been overseen in previous works. MetaToken can be applied to any open-source LVLM without any knowledge about ground truth data providing a reliable detection of hallucinations. We evaluate our method on four state-of-the-art LVLMs demonstrating the effectiveness of our approach.
5/30/2024