Detection-Correction Structure via General Language Model for Grammatical Error Correction
2405.17804
0
0
Abstract
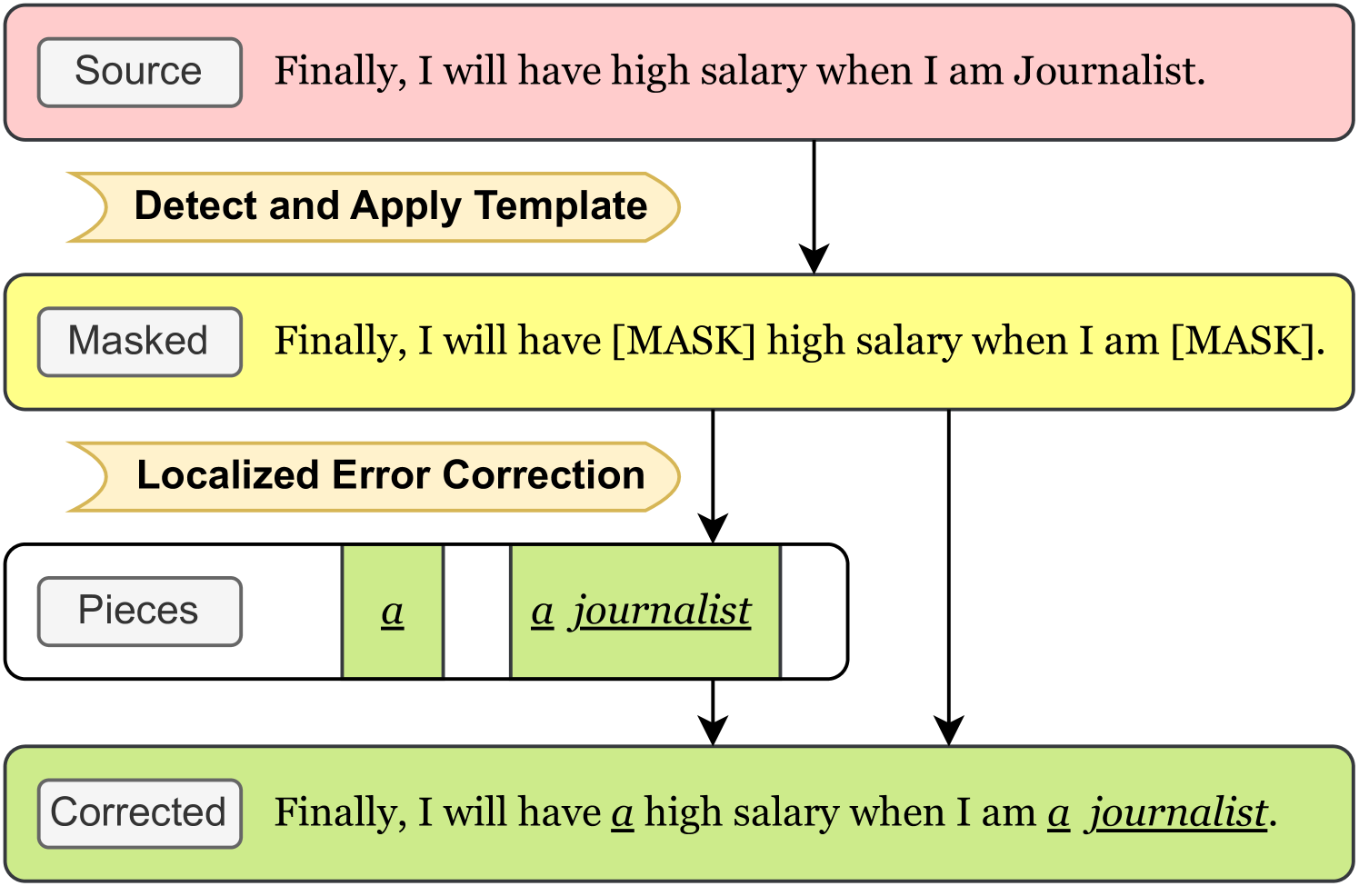
Grammatical error correction (GEC) is a task dedicated to rectifying texts with minimal edits, which can be decoupled into two components: detection and correction. However, previous works have predominantly focused on direct correction, with no prior efforts to integrate both into a single model. Moreover, the exploration of the detection-correction paradigm by large language models (LLMs) remains underdeveloped. This paper introduces an integrated detection-correction structure, named DeCoGLM, based on the General Language Model (GLM). The detection phase employs a fault-tolerant detection template, while the correction phase leverages autoregressive mask infilling for localized error correction. Through the strategic organization of input tokens and modification of attention masks, we facilitate multi-task learning within a single model. Our model demonstrates competitive performance against the state-of-the-art models on English and Chinese GEC datasets. Further experiments present the effectiveness of the detection-correction structure in LLMs, suggesting a promising direction for GEC.
Create account to get full access
Overview
- This paper presents a novel grammatical error correction (GEC) approach called the "Detection-Correction Structure via General Language Model" (DCSGLM).
- The proposed method leverages a general-purpose language model to simultaneously detect and correct grammatical errors in text.
- The authors demonstrate the effectiveness of their approach on several benchmark GEC datasets, outperforming state-of-the-art models.
Plain English Explanation
The paper describes a new way to automatically fix grammatical mistakes in written text. Many existing GEC systems use separate models for detecting errors and then correcting them. However, the authors of this paper propose a more integrated approach that uses a single, general-purpose language model to both identify grammatical issues and suggest the correct fixes.
The key idea is to train the language model to not just predict the next word in a sequence, but also to classify whether each word is grammatically correct or not. By combining these two tasks - error detection and error correction - the model can learn to recognize and repair errors more effectively. The authors show that this "detection-correction" structure leads to better performance compared to previous GEC systems on standard evaluation datasets.
This is an important advance in the field of natural language processing. Improving grammatical error correction has many practical applications, such as helping people write better emails and documents, providing feedback to language learners, and ensuring the quality of machine-generated text. The authors' novel approach demonstrates how state-of-the-art language models can be adapted and fine-tuned to tackle specific language tasks in an efficient and effective manner.
Technical Explanation
The authors propose a new GEC framework called [DCSGLM], which stands for "Detection-Correction Structure via General Language Model." The core idea is to leverage a pre-trained general-purpose language model, such as [GPT-35], and fine-tune it to jointly detect and correct grammatical errors.
Compared to traditional GEC systems that use separate models for error detection and correction, the [DCSGLM] approach integrates these two tasks into a single model. Specifically, the language model is trained to not only predict the next word in a sequence, but also to classify each word as either correct or incorrect. This "detection-correction" structure allows the model to learn the interdependencies between error identification and error rectification.
The authors evaluate their [DCSGLM] model on several benchmark GEC datasets, including [Pillars], [LARGE LANGUAGE MODELS], and [REVISITING META-EVALUATION]. They show that their approach outperforms state-of-the-art GEC models, demonstrating the effectiveness of the joint detection-correction framework.
Furthermore, the authors conduct extensive ablation studies to understand the contributions of different components of their model, such as the language model pretraining, the multi-task training setup, and the error detection mechanism. These insights provide a comprehensive understanding of the factors that enable the [DCSGLM] model to achieve strong GEC performance.
Critical Analysis
The [DCSGLM] approach presented in this paper is a promising step forward in grammatical error correction. By integrating detection and correction into a single model, the authors have demonstrated the potential advantages of this more holistic approach over traditional GEC systems.
One key strength of the [DCSGLM] model is its ability to leverage a large, pre-trained language model, which has been shown to be a highly effective foundation for various natural language tasks, including [GPT-35] and [WHO WROTE THIS]. By fine-tuning this general-purpose model on the GEC task, the authors are able to benefit from the rich linguistic knowledge and contextual understanding encoded in the pre-trained weights.
However, the paper also acknowledges some limitations of the [DCSGLM] approach. For instance, the authors note that their model may struggle with certain types of rare or complex grammatical errors, as the language model's predictions can be biased towards more common patterns. Additionally, the authors mention that further research is needed to understand the interpretability and explainability of the model's error detection and correction mechanisms.
Future work could explore ways to address these limitations, such as incorporating more targeted error-specific modules or leveraging additional external resources to enhance the model's coverage of diverse grammatical constructs. Investigating the model's generalization capabilities across different domains and languages would also be valuable.
Overall, the [DCSGLM] model presented in this paper represents a significant advancement in grammatical error correction, demonstrating the power of integrating detection and correction within a unified language model architecture. As the field of natural language processing continues to progress, innovations like this are likely to have far-reaching impacts on applications that require high-quality, grammatically correct text generation and editing.
Conclusion
This paper introduces a novel grammatical error correction (GEC) approach called the "Detection-Correction Structure via General Language Model" (DCSGLM). The key innovation of the DCSGLM model is its ability to jointly detect and correct grammatical errors using a single, pre-trained language model.
The authors show that this integrated detection-correction structure outperforms state-of-the-art GEC models on several benchmark datasets. Their findings highlight the potential benefits of leveraging general-purpose language models and combining error identification and rectification into a unified framework.
The DCSGLM approach represents an important step forward in the field of natural language processing, with practical applications in areas like document editing, language learning, and machine-generated text quality assurance. While the model has some limitations, the authors' comprehensive analysis and insights provide a solid foundation for future research and development in grammatical error correction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Pillars of Grammatical Error Correction: Comprehensive Inspection Of Contemporary Approaches In The Era of Large Language Models
Kostiantyn Omelianchuk, Andrii Liubonko, Oleksandr Skurzhanskyi, Artem Chernodub, Oleksandr Korniienko, Igor Samokhin
0
0
In this paper, we carry out experimental research on Grammatical Error Correction, delving into the nuances of single-model systems, comparing the efficiency of ensembling and ranking methods, and exploring the application of large language models to GEC as single-model systems, as parts of ensembles, and as ranking methods. We set new state-of-the-art performance with F_0.5 scores of 72.8 on CoNLL-2014-test and 81.4 on BEA-test, respectively. To support further advancements in GEC and ensure the reproducibility of our research, we make our code, trained models, and systems' outputs publicly available.
4/24/2024
🤔
Alirector: Alignment-Enhanced Chinese Grammatical Error Corrector
Haihui Yang, Xiaojun Quan
0
0
Chinese grammatical error correction (CGEC) faces serious overcorrection challenges when employing autoregressive generative models such as sequence-to-sequence (Seq2Seq) models and decoder-only large language models (LLMs). While previous methods aim to address overcorrection in Seq2Seq models, they are difficult to adapt to decoder-only LLMs. In this paper, we propose an alignment-enhanced corrector for the overcorrection problem that applies to both Seq2Seq models and decoder-only LLMs. Our method first trains a correction model to generate an initial correction of the source sentence. Then, we combine the source sentence with the initial correction and feed it through an alignment model for another round of correction, aiming to enforce the alignment model to focus on potential overcorrection. Moreover, to enhance the model's ability to identify nuances, we further explore the reverse alignment of the source sentence and the initial correction. Finally, we transfer the alignment knowledge from two alignment models to the correction model, instructing it on how to avoid overcorrection. Experimental results on three CGEC datasets demonstrate the effectiveness of our approach in alleviating overcorrection and improving overall performance. Our code has been made publicly available.
6/4/2024
Large Language Models Are State-of-the-Art Evaluator for Grammatical Error Correction
Masamune Kobayashi, Masato Mita, Mamoru Komachi
0
0
Large Language Models (LLMs) have been reported to outperform existing automatic evaluation metrics in some tasks, such as text summarization and machine translation. However, there has been a lack of research on LLMs as evaluators in grammatical error correction (GEC). In this study, we investigate the performance of LLMs in GEC evaluation by employing prompts designed to incorporate various evaluation criteria inspired by previous research. Our extensive experimental results demonstrate that GPT-4 achieved Kendall's rank correlation of 0.662 with human judgments, surpassing all existing methods. Furthermore, in recent GEC evaluations, we have underscored the significance of the LLMs scale and particularly emphasized the importance of fluency among evaluation criteria.
5/28/2024
🖼️
GPT-3.5 for Grammatical Error Correction
Anisia Katinskaia, Roman Yangarber
0
0
This paper investigates the application of GPT-3.5 for Grammatical Error Correction (GEC) in multiple languages in several settings: zero-shot GEC, fine-tuning for GEC, and using GPT-3.5 to re-rank correction hypotheses generated by other GEC models. In the zero-shot setting, we conduct automatic evaluations of the corrections proposed by GPT-3.5 using several methods: estimating grammaticality with language models (LMs), the Scribendi test, and comparing the semantic embeddings of sentences. GPT-3.5 has a known tendency to over-correct erroneous sentences and propose alternative corrections. For several languages, such as Czech, German, Russian, Spanish, and Ukrainian, GPT-3.5 substantially alters the source sentences, including their semantics, which presents significant challenges for evaluation with reference-based metrics. For English, GPT-3.5 demonstrates high recall, generates fluent corrections, and generally preserves sentence semantics. However, human evaluation for both English and Russian reveals that, despite its strong error-detection capabilities, GPT-3.5 struggles with several error types, including punctuation mistakes, tense errors, syntactic dependencies between words, and lexical compatibility at the sentence level.
5/15/2024