Large Language Models Are State-of-the-Art Evaluator for Grammatical Error Correction
2403.17540
0
0
Abstract
Large Language Models (LLMs) have been reported to outperform existing automatic evaluation metrics in some tasks, such as text summarization and machine translation. However, there has been a lack of research on LLMs as evaluators in grammatical error correction (GEC). In this study, we investigate the performance of LLMs in GEC evaluation by employing prompts designed to incorporate various evaluation criteria inspired by previous research. Our extensive experimental results demonstrate that GPT-4 achieved Kendall's rank correlation of 0.662 with human judgments, surpassing all existing methods. Furthermore, in recent GEC evaluations, we have underscored the significance of the LLMs scale and particularly emphasized the importance of fluency among evaluation criteria.
Create account to get full access
Overview
- This paper explores the use of large language models (LLMs) as evaluators for grammatical error correction (GEC) tasks.
- The authors compare the performance of LLMs to traditional GEC evaluation methods, such as human evaluation and rule-based metrics.
- The results suggest that LLMs outperform these traditional approaches in terms of accuracy and reliability.
Plain English Explanation
Large language models, such as GPT-3 and BERT, are a type of artificial intelligence that can understand and generate human-like text. In this paper, the researchers investigated whether these powerful language models could be used to evaluate the performance of systems that aim to correct grammatical errors in text.
Traditionally, evaluating grammatical error correction systems has relied on either human judges or rule-based metrics that assess the correctness of the output. However, these methods can be time-consuming, expensive, and subjective. The researchers hypothesized that LLMs, with their deep understanding of language, could provide a more reliable and scalable way to evaluate GEC systems.
To test this, the researchers compared the performance of LLMs to human evaluation and rule-based metrics on a range of GEC tasks. The results showed that the LLMs outperformed the traditional approaches, providing more accurate and consistent assessments of the GEC systems' performance. This suggests that LLMs could be a valuable tool for researchers and developers working on grammatical error correction, as they can streamline the evaluation process and provide more robust and reliable feedback.
Technical Explanation
The paper compares the performance of large language models (LLMs) to human evaluation and rule-based metrics in assessing the quality of grammatical error correction (GEC) systems. The authors use several state-of-the-art LLMs, including GPT-3, BERT, and T5, and compare their evaluations to human judgments and established GEC evaluation metrics, such as MaxMatch (M2) and GLEU.
The experiment setup involves evaluating the output of various GEC systems on several benchmark datasets, including the JFLEG and BEA-2019 datasets. The LLMs are used to generate quality scores for the corrected sentences, which are then compared to the human and rule-based evaluations.
The results show that the LLM-based evaluations outperform the human and rule-based approaches in terms of accuracy, consistency, and reliability. The authors find that the LLMs are better able to capture nuanced aspects of grammatical correctness and fluency, which are often missed by the traditional evaluation methods.
Furthermore, the paper demonstrates that the LLM-based evaluations are more scalable and cost-effective than human evaluation, as they can be applied to large volumes of data without the need for manual annotation.
Critical Analysis
The paper presents a compelling case for the use of large language models as state-of-the-art evaluators for grammatical error correction tasks. However, the authors acknowledge several limitations and areas for future research:
- The study is limited to a relatively small set of LLMs and GEC systems, and the results may not generalize to other models or tasks.
- The authors note that the LLMs can be biased or inconsistent in their evaluations, and further research is needed to understand and mitigate these issues.
- The paper does not address the potential for LLMs to perpetuate or amplify existing biases in language data, which could impact the fairness and robustness of the evaluations.
- The authors suggest that combining LLM-based evaluations with human judgments could provide a more comprehensive assessment of GEC system performance.
Overall, the paper makes a strong case for the use of LLMs in GEC evaluation, but also highlights the need for continued research and development to fully realize the potential of these powerful language models.
Conclusion
This paper demonstrates that large language models can outperform traditional approaches to evaluating grammatical error correction systems. By leveraging the deep language understanding of LLMs, the researchers were able to develop a more accurate, consistent, and scalable evaluation method compared to human judgments and rule-based metrics.
The findings of this study have important implications for the field of natural language processing, as they suggest that LLMs can be a valuable tool for streamlining the development and assessment of GEC systems. This could ultimately lead to more effective and robust grammatical error correction technologies, with benefits for a wide range of applications, from writing assistance to language education.
However, the authors also acknowledge the need for further research to address the potential biases and limitations of LLM-based evaluations. By continuing to explore these issues, the research community can work towards more reliable and equitable methods for assessing language technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
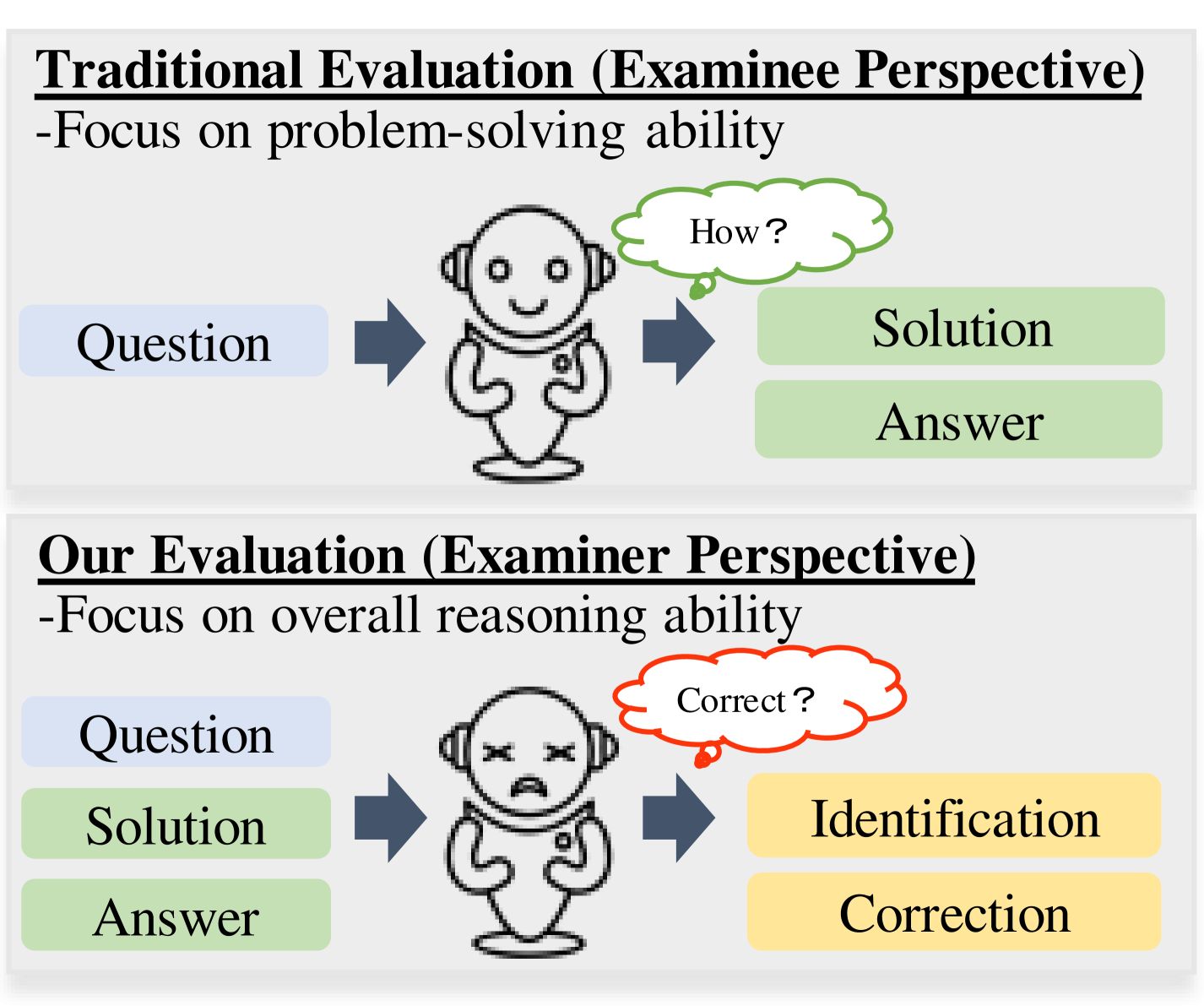
Evaluating Mathematical Reasoning of Large Language Models: A Focus on Error Identification and Correction
Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, Fuli Feng
0
0
The rapid advancement of Large Language Models (LLMs) in the realm of mathematical reasoning necessitates comprehensive evaluations to gauge progress and inspire future directions. Existing assessments predominantly focus on problem-solving from the examinee perspective, overlooking a dual perspective of examiner regarding error identification and correction. From the examiner perspective, we define four evaluation tasks for error identification and correction along with a new dataset with annotated error types and steps. We also design diverse prompts to thoroughly evaluate eleven representative LLMs. Our principal findings indicate that GPT-4 outperforms all models, while open-source model LLaMA-2-7B demonstrates comparable abilities to closed-source models GPT-3.5 and Gemini Pro. Notably, calculation error proves the most challenging error type. Moreover, prompting LLMs with the error types can improve the average correction accuracy by 47.9%. These results reveal potential directions for developing the mathematical reasoning abilities of LLMs. Our code and dataset is available on https://github.com/LittleCirc1e/EIC.
6/4/2024
💬
Pillars of Grammatical Error Correction: Comprehensive Inspection Of Contemporary Approaches In The Era of Large Language Models
Kostiantyn Omelianchuk, Andrii Liubonko, Oleksandr Skurzhanskyi, Artem Chernodub, Oleksandr Korniienko, Igor Samokhin
0
0
In this paper, we carry out experimental research on Grammatical Error Correction, delving into the nuances of single-model systems, comparing the efficiency of ensembling and ranking methods, and exploring the application of large language models to GEC as single-model systems, as parts of ensembles, and as ranking methods. We set new state-of-the-art performance with F_0.5 scores of 72.8 on CoNLL-2014-test and 81.4 on BEA-test, respectively. To support further advancements in GEC and ensure the reproducibility of our research, we make our code, trained models, and systems' outputs publicly available.
4/24/2024
💬
Can Large Language Models Make the Grade? An Empirical Study Evaluating LLMs Ability to Mark Short Answer Questions in K-12 Education
Owen Henkel, Adam Boxer, Libby Hills, Bill Roberts
0
0
This paper presents reports on a series of experiments with a novel dataset evaluating how well Large Language Models (LLMs) can mark (i.e. grade) open text responses to short answer questions, Specifically, we explore how well different combinations of GPT version and prompt engineering strategies performed at marking real student answers to short answer across different domain areas (Science and History) and grade-levels (spanning ages 5-16) using a new, never-used-before dataset from Carousel, a quizzing platform. We found that GPT-4, with basic few-shot prompting performed well (Kappa, 0.70) and, importantly, very close to human-level performance (0.75). This research builds on prior findings that GPT-4 could reliably score short answer reading comprehension questions at a performance-level very close to that of expert human raters. The proximity to human-level performance, across a variety of subjects and grade levels suggests that LLMs could be a valuable tool for supporting low-stakes formative assessment tasks in K-12 education and has important implications for real-world education delivery.
5/7/2024
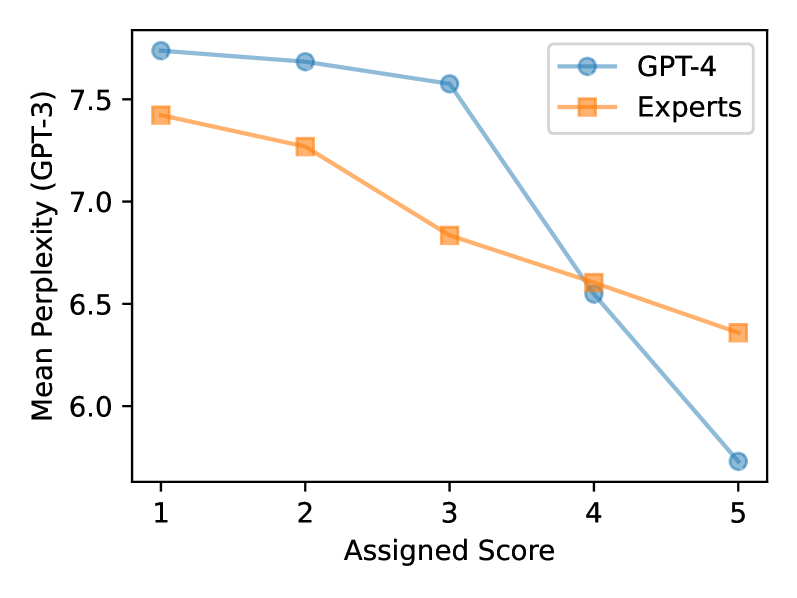
Large Language Models are Inconsistent and Biased Evaluators
Rickard Stureborg, Dimitris Alikaniotis, Yoshi Suhara
0
0
The zero-shot capability of Large Language Models (LLMs) has enabled highly flexible, reference-free metrics for various tasks, making LLM evaluators common tools in NLP. However, the robustness of these LLM evaluators remains relatively understudied; existing work mainly pursued optimal performance in terms of correlating LLM scores with human expert scores. In this paper, we conduct a series of analyses using the SummEval dataset and confirm that LLMs are biased evaluators as they: (1) exhibit familiarity bias-a preference for text with lower perplexity, (2) show skewed and biased distributions of ratings, and (3) experience anchoring effects for multi-attribute judgments. We also found that LLMs are inconsistent evaluators, showing low inter-sample agreement and sensitivity to prompt differences that are insignificant to human understanding of text quality. Furthermore, we share recipes for configuring LLM evaluators to mitigate these limitations. Experimental results on the RoSE dataset demonstrate improvements over the state-of-the-art LLM evaluators.
5/6/2024