DeTra: A Unified Model for Object Detection and Trajectory Forecasting
2406.04426
0
0

Abstract
The tasks of object detection and trajectory forecasting play a crucial role in understanding the scene for autonomous driving. These tasks are typically executed in a cascading manner, making them prone to compounding errors. Furthermore, there is usually a very thin interface between the two tasks, creating a lossy information bottleneck. To address these challenges, our approach formulates the union of the two tasks as a trajectory refinement problem, where the first pose is the detection (current time), and the subsequent poses are the waypoints of the multiple forecasts (future time). To tackle this unified task, we design a refinement transformer that infers the presence, pose, and multi-modal future behaviors of objects directly from LiDAR point clouds and high-definition maps. We call this model DeTra, short for object Detection and Trajectory forecasting. In our experiments, we observe that ourmodel{} outperforms the state-of-the-art on Argoverse 2 Sensor and Waymo Open Dataset by a large margin, across a broad range of metrics. Last but not least, we perform extensive ablation studies that show the value of refinement for this task, that every proposed component contributes positively to its performance, and that key design choices were made.
Create account to get full access
Overview
• This paper presents DeTra, a unified model for object detection and trajectory forecasting in dynamic scenes.
• DeTra aims to jointly learn object detection and trajectory prediction, leveraging the synergies between these two tasks to improve overall performance.
• The key innovation is a novel dual-head architecture that shares a common feature backbone to efficiently extract multi-modal information for both tasks.
Plain English Explanation
DeTra is a new AI model that can do two things at once: detect objects in images and predict how those objects will move in the future. This is useful for applications like self-driving cars, where you need to know what's around you and where it's going.
The way DeTra works is by using a single set of features, or building blocks, to do both object detection and trajectory forecasting. This is more efficient than having separate models for each task. By sharing information between the two tasks, DeTra can get better at both of them.
For example, if DeTra sees a car in an image, it can use that information to also predict how that car will move in the future. This joint approach allows DeTra to make more accurate predictions than if it was just trying to do one task or the other.
Technical Explanation
• DeTra uses a dual-head architecture, where one head is responsible for object detection and the other for trajectory forecasting.
• The two heads share a common feature backbone, which allows them to efficiently extract and share multi-modal information relevant to both tasks.
• For object detection, DeTra uses a region proposal network to identify potential object locations, and then classifies and refines the bounding boxes.
• For trajectory forecasting, DeTra predicts future object locations based on the current detection, using a recurrent neural network to model the temporal dynamics.
• The model is trained end-to-end on datasets that provide both object annotations and trajectory information, allowing it to learn the connections between the two tasks.
Critical Analysis
• The paper acknowledges that the joint training approach introduces additional complexity compared to separate models for each task.
• While the results show performance improvements, the authors note that there is still room for further refinement of the architecture and training strategies.
• One potential limitation is that the model may struggle in highly cluttered or occluded scenes, where the shared features may not be sufficient to disentangle the individual objects and their trajectories.
• Additional research is needed to fully understand the trade-offs and limitations of the unified approach compared to more specialized models.
Conclusion
• DeTra demonstrates the potential benefits of jointly learning object detection and trajectory forecasting, by leveraging the synergies between the two tasks.
• The unified architecture provides a more efficient and effective way to extract and utilize multi-modal information, leading to improved performance on both tasks.
• While further refinements are needed, DeTra represents an important step towards developing more robust and capable AI systems for dynamic scene understanding, with applications in areas like autonomous navigation and surveillance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Learning Temporal Cues by Predicting Objects Move for Multi-camera 3D Object Detection
Seokha Moon, Hongbeen Park, Jungphil Kwon, Jaekoo Lee, Jinkyu Kim
0
0
In autonomous driving and robotics, there is a growing interest in utilizing short-term historical data to enhance multi-camera 3D object detection, leveraging the continuous and correlated nature of input video streams. Recent work has focused on spatially aligning BEV-based features over timesteps. However, this is often limited as its gain does not scale well with long-term past observations. To address this, we advocate for supervising a model to predict objects' poses given past observations, thus explicitly guiding to learn objects' temporal cues. To this end, we propose a model called DAP (Detection After Prediction), consisting of a two-branch network: (i) a branch responsible for forecasting the current objects' poses given past observations and (ii) another branch that detects objects based on the current and past observations. The features predicting the current objects from branch (i) is fused into branch (ii) to transfer predictive knowledge. We conduct extensive experiments with the large-scale nuScenes datasets, and we observe that utilizing such predictive information significantly improves the overall detection performance. Our model can be used plug-and-play, showing consistent performance gain.
4/3/2024

TrACT: A Training Dynamics Aware Contrastive Learning Framework for Long-tail Trajectory Prediction
Junrui Zhang, Mozhgan Pourkeshavarz, Amir Rasouli
0
0
As a safety critical task, autonomous driving requires accurate predictions of road users' future trajectories for safe motion planning, particularly under challenging conditions. Yet, many recent deep learning methods suffer from a degraded performance on the challenging scenarios, mainly because these scenarios appear less frequently in the training data. To address such a long-tail issue, existing methods force challenging scenarios closer together in the feature space during training to trigger information sharing among them for more robust learning. These methods, however, primarily rely on the motion patterns to characterize scenarios, omitting more informative contextual information, such as interactions and scene layout. We argue that exploiting such information not only improves prediction accuracy but also scene compliance of the generated trajectories. In this paper, we propose to incorporate richer training dynamics information into a prototypical contrastive learning framework. More specifically, we propose a two-stage process. First, we generate rich contextual features using a baseline encoder-decoder framework. These features are split into clusters based on the model's output errors, using the training dynamics information, and a prototype is computed within each cluster. Second, we retrain the model using the prototypes in a contrastive learning framework. We conduct empirical evaluations of our approach using two large-scale naturalistic datasets and show that our method achieves state-of-the-art performance by improving accuracy and scene compliance on the long-tail samples. Furthermore, we perform experiments on a subset of the clusters to highlight the additional benefit of our approach in reducing training bias.
5/1/2024

New!StreamMOTP: Streaming and Unified Framework for Joint 3D Multi-Object Tracking and Trajectory Prediction
Jiaheng Zhuang, Guoan Wang, Siyu Zhang, Xiyang Wang, Hangning Zhou, Ziyao Xu, Chi Zhang, Zhiheng Li
0
0
3D multi-object tracking and trajectory prediction are two crucial modules in autonomous driving systems. Generally, the two tasks are handled separately in traditional paradigms and a few methods have started to explore modeling these two tasks in a joint manner recently. However, these approaches suffer from the limitations of single-frame training and inconsistent coordinate representations between tracking and prediction tasks. In this paper, we propose a streaming and unified framework for joint 3D Multi-Object Tracking and trajectory Prediction (StreamMOTP) to address the above challenges. Firstly, we construct the model in a streaming manner and exploit a memory bank to preserve and leverage the long-term latent features for tracked objects more effectively. Secondly, a relative spatio-temporal positional encoding strategy is introduced to bridge the gap of coordinate representations between the two tasks and maintain the pose-invariance for trajectory prediction. Thirdly, we further improve the quality and consistency of predicted trajectories with a dual-stream predictor. We conduct extensive experiments on popular nuSences dataset and the experimental results demonstrate the effectiveness and superiority of StreamMOTP, which outperforms previous methods significantly on both tasks. Furthermore, we also prove that the proposed framework has great potential and advantages in actual applications of autonomous driving.
7/1/2024
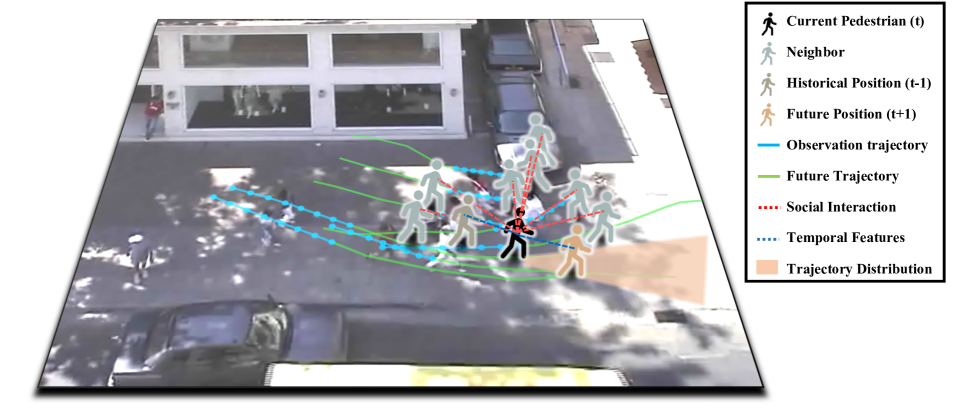
Attention-aware Social Graph Transformer Networks for Stochastic Trajectory Prediction
Yao Liu, Binghao Li, Xianzhi Wang, Claude Sammut, Lina Yao
0
0
Trajectory prediction is fundamental to various intelligent technologies, such as autonomous driving and robotics. The motion prediction of pedestrians and vehicles helps emergency braking, reduces collisions, and improves traffic safety. Current trajectory prediction research faces problems of complex social interactions, high dynamics and multi-modality. Especially, it still has limitations in long-time prediction. We propose Attention-aware Social Graph Transformer Networks for multi-modal trajectory prediction. We combine Graph Convolutional Networks and Transformer Networks by generating stable resolution pseudo-images from Spatio-temporal graphs through a designed stacking and interception method. Furthermore, we design the attention-aware module to handle social interaction information in scenarios involving mixed pedestrian-vehicle traffic. Thus, we maintain the advantages of the Graph and Transformer, i.e., the ability to aggregate information over an arbitrary number of neighbors and the ability to perform complex time-dependent data processing. We conduct experiments on datasets involving pedestrian, vehicle, and mixed trajectories, respectively. Our results demonstrate that our model minimizes displacement errors across various metrics and significantly reduces the likelihood of collisions. It is worth noting that our model effectively reduces the final displacement error, illustrating the ability of our model to predict for a long time.
5/14/2024