DeTurb: Atmospheric Turbulence Mitigation with Deformable 3D Convolutions and 3D Swin Transformers

0
Sign in to get full access
Overview
- DeTurb is a deep learning model for mitigating the effects of atmospheric turbulence in images.
- It uses deformable 3D convolutions and 3D Swin Transformers to handle the spatial and temporal aspects of turbulence.
- The model is trained on a large-scale dataset of turbulence-affected images to learn how to restore clear, sharp images.
Plain English Explanation
Atmospheric turbulence can cause images captured from a distance to appear blurry or distorted. This is a common problem in applications like astronomy, remote sensing, and aerial photography. DeTurb is a deep learning model that aims to mitigate the effects of atmospheric turbulence and restore clear, sharp images.
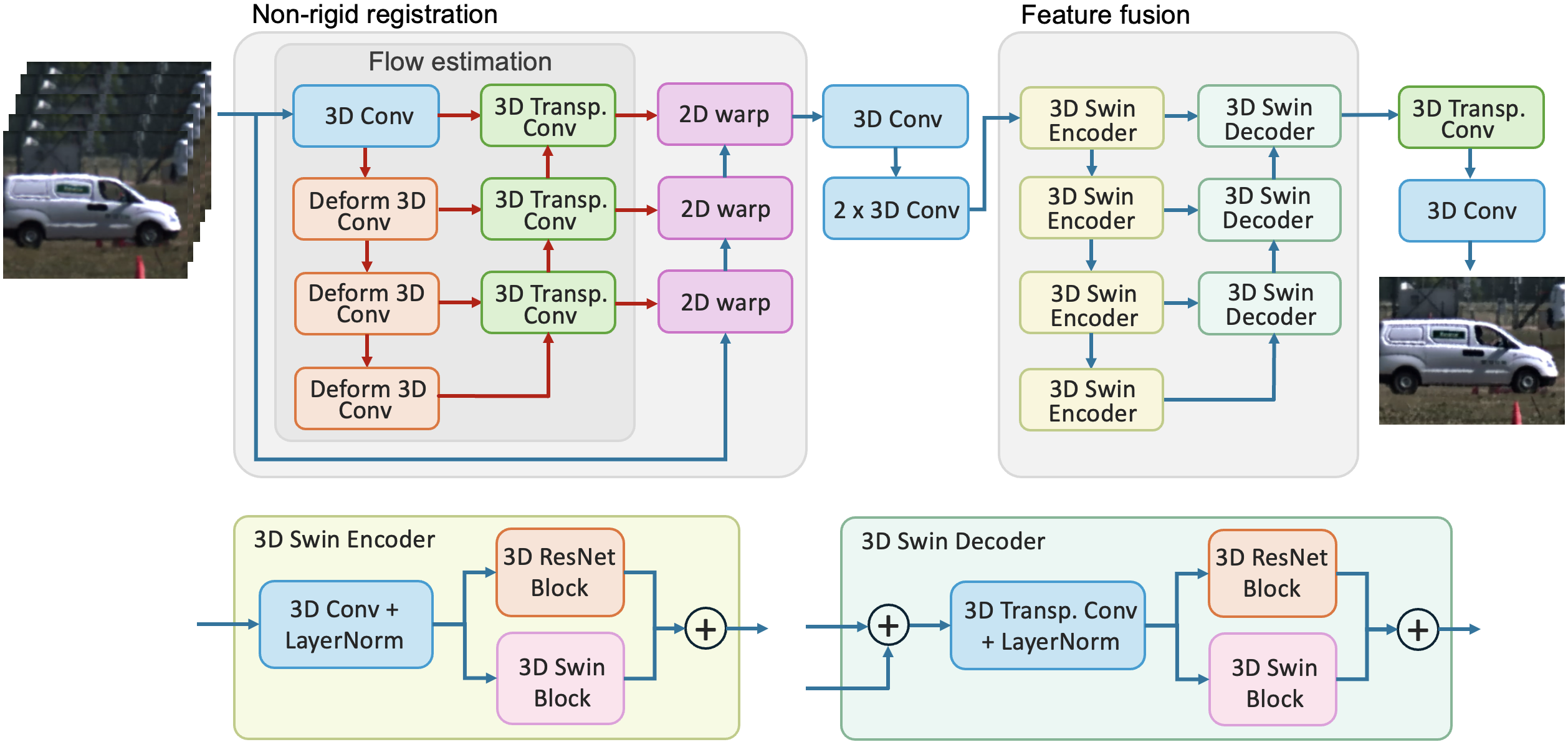
The key innovations in DeTurb are the use of deformable 3D convolutions and 3D Swin Transformers. Deformable convolutions allow the model to adaptively modify the shape of its filters to better match the distortions caused by turbulence. The 3D Swin Transformers capture the spatio-temporal nature of turbulence, modeling both the spatial and temporal aspects of the distortion.
DeTurb is trained on a large dataset of turbulence-affected images, learning to segment the distorted regions and then apply the appropriate deformations to restore the image. This allows it to generalize to a wide range of turbulence patterns and produce high-quality restored images.
Technical Explanation
DeTurb is a deep learning model designed to mitigate the effects of atmospheric turbulence in images. It uses a combination of deformable 3D convolutions and 3D Swin Transformers to handle the spatial and temporal aspects of turbulence.
The model's architecture consists of several key components:
-
Deformable 3D Convolutions: These convolutions allow the model to adaptively modify the shape of its filters to better match the distortions caused by turbulence, improving the model's ability to capture and correct these distortions.
-
3D Swin Transformers: The 3D Swin Transformers capture the spatio-temporal nature of turbulence, modeling both the spatial and temporal aspects of the distortion. This helps the model understand the dynamic nature of the turbulence and apply the appropriate corrections.
-
Turbulence Segmentation and Restoration: DeTurb first segments the distorted regions of the image, then applies the necessary deformations to restore the image to its clear, sharp state. This two-step process allows the model to handle a wide range of turbulence patterns and produce high-quality results.
The model is trained on a large-scale dataset of turbulence-affected images, enabling it to generalize to a variety of real-world scenarios. The deformable 3D convolutions and 3D Swin Transformers are key to the model's performance, as they allow it to effectively capture and correct the complex spatio-temporal distortions caused by atmospheric turbulence.
Critical Analysis
The paper presents a well-designed and effective solution for mitigating the effects of atmospheric turbulence in images. The use of deformable 3D convolutions and 3D Swin Transformers is a novel and promising approach that addresses the key challenges in this domain.
One potential limitation of the research is the reliance on a large-scale dataset of turbulence-affected images for training. While this dataset provides a comprehensive training set, it may not fully capture the diversity of real-world turbulence patterns, especially in less-studied or geographically limited regions. Further research into data augmentation techniques or alternative training strategies could help address this limitation.
Additionally, the paper does not provide a detailed analysis of the model's performance on different types of turbulence or its sensitivity to various environmental factors. Exploring these aspects could yield valuable insights and help identify potential areas for improvement.
Overall, the DeTurb model represents a significant advancement in the field of atmospheric turbulence mitigation. The innovative use of deformable 3D convolutions and 3D Swin Transformers demonstrates the potential of deep learning to address complex spatio-temporal distortions, and the model's performance on the provided dataset is impressive. Continued research and refinement of the approach could further expand its applicability and impact.
Conclusion
DeTurb is a deep learning model that effectively mitigates the effects of atmospheric turbulence in images. By leveraging deformable 3D convolutions and 3D Swin Transformers, the model is able to capture and correct the complex spatio-temporal distortions caused by turbulence, restoring clear and sharp images.
The model's performance on a large-scale dataset of turbulence-affected images is a promising step forward in the field of atmospheric turbulence mitigation. While the research has some limitations, such as the reliance on a specific dataset and the need for further analysis of the model's performance under different conditions, the innovative approaches used in DeTurb demonstrate the potential of deep learning to address this long-standing challenge.
As remote sensing, astronomy, and other applications continue to rely on high-quality images captured from a distance, tools like DeTurb will become increasingly valuable in overcoming the effects of atmospheric turbulence and enabling more accurate and reliable image-based analysis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DeTurb: Atmospheric Turbulence Mitigation with Deformable 3D Convolutions and 3D Swin Transformers
Zhicheng Zou, Nantheera Anantrasirichai
Atmospheric turbulence in long-range imaging significantly degrades the quality and fidelity of captured scenes due to random variations in both spatial and temporal dimensions. These distortions present a formidable challenge across various applications, from surveillance to astronomy, necessitating robust mitigation strategies. While model-based approaches achieve good results, they are very slow. Deep learning approaches show promise in image and video restoration but have struggled to address these spatiotemporal variant distortions effectively. This paper proposes a new framework that combines geometric restoration with an enhancement module. Random perturbations and geometric distortion are removed using a pyramid architecture with deformable 3D convolutions, resulting in aligned frames. These frames are then used to reconstruct a sharp, clear image via a multi-scale architecture of 3D Swin Transformers. The proposed framework demonstrates superior performance over the state of the art for both synthetic and real atmospheric turbulence effects, with reasonable speed and model size.
Read more7/31/2024

0
Spatio-Temporal Turbulence Mitigation: A Translational Perspective
Xingguang Zhang, Nicholas Chimitt, Yiheng Chi, Zhiyuan Mao, Stanley H. Chan
Recovering images distorted by atmospheric turbulence is a challenging inverse problem due to the stochastic nature of turbulence. Although numerous turbulence mitigation (TM) algorithms have been proposed, their efficiency and generalization to real-world dynamic scenarios remain severely limited. Building upon the intuitions of classical TM algorithms, we present the Deep Atmospheric TUrbulence Mitigation network (DATUM). DATUM aims to overcome major challenges when transitioning from classical to deep learning approaches. By carefully integrating the merits of classical multi-frame TM methods into a deep network structure, we demonstrate that DATUM can efficiently perform long-range temporal aggregation using a recurrent fashion, while deformable attention and temporal-channel attention seamlessly facilitate pixel registration and lucky imaging. With additional supervision, tilt and blur degradation can be jointly mitigated. These inductive biases empower DATUM to significantly outperform existing methods while delivering a tenfold increase in processing speed. A large-scale training dataset, ATSyn, is presented as a co-invention to enable generalization in real turbulence. Our code and datasets are available at https://xg416.github.io/DATUM.
Read more4/9/2024

0
Long-range Turbulence Mitigation: A Large-scale Dataset and A Coarse-to-fine Framework
Shengqi Xu, Run Sun, Yi Chang, Shuning Cao, Xueyao Xiao, Luxin Yan
Long-range imaging inevitably suffers from atmospheric turbulence with severe geometric distortions due to random refraction of light. The further the distance, the more severe the disturbance. Despite existing research has achieved great progress in tackling short-range turbulence, there is less attention paid to long-range turbulence with significant distortions. To address this dilemma and advance the field, we construct a large-scale real long-range atmospheric turbulence dataset (RLR-AT), including 1500 turbulence sequences spanning distances from 1 Km to 13 Km. The advantages of RLR-AT compared to existing ones: turbulence with longer-distances and higher-diversity, scenes with greater-variety and larger-scale. Moreover, most existing work adopts either registration-based or decomposition-based methods to address distortions through one-step mitigation. However, they fail to effectively handle long-range turbulence due to its significant pixel displacements. In this work, we propose a coarse-to-fine framework to handle severe distortions, which cooperates dynamic turbulence and static background priors (CDSP). On the one hand, we discover the pixel motion statistical prior of turbulence, and propose a frequency-aware reference frame for better large-scale distortion registration, greatly reducing the burden of refinement. On the other hand, we take advantage of the static prior of background, and propose a subspace-based low-rank tensor refinement model to eliminate the misalignments inevitably left by registration while well preserving details. The dynamic and static priors complement to each other, facilitating us to progressively mitigate long-range turbulence with severe distortions. Extensive experiments demonstrate that the proposed method outperforms SOTA methods on different datasets.
Read more7/18/2024

0
How to Augment for Atmospheric Turbulence Effects on Thermal Adapted Object Detection Models?
Engin Uzun, Erdem Akagunduz
Atmospheric turbulence poses a significant challenge to the performance of object detection models. Turbulence causes distortions, blurring, and noise in images by bending and scattering light rays due to variations in the refractive index of air. This results in non-rigid geometric distortions and temporal fluctuations in the electromagnetic radiation received by optical systems. This paper explores the effectiveness of turbulence image augmentation techniques in improving the accuracy and robustness of thermal-adapted and deep learning-based object detection models under atmospheric turbulence. Three distinct approximation-based turbulence simulators (geometric, Zernike-based, and P2S) are employed to generate turbulent training and test datasets. The performance of three state-of-the-art deep learning-based object detection models: RTMDet-x, DINO-4scale, and YOLOv8-x, is employed on these turbulent datasets with and without turbulence augmentation during training. The results demonstrate that utilizing turbulence-specific augmentations during model training can significantly improve detection accuracy and robustness against distorted turbulent images. Turbulence augmentation enhances performance even for a non-turbulent test set.
Read more5/13/2024