DiffCAD: Weakly-Supervised Probabilistic CAD Model Retrieval and Alignment from an RGB Image
2311.18610
0
0

Abstract
Perceiving 3D structures from RGB images based on CAD model primitives can enable an effective, efficient 3D object-based representation of scenes. However, current approaches rely on supervision from expensive annotations of CAD models associated with real images, and encounter challenges due to the inherent ambiguities in the task -- both in depth-scale ambiguity in monocular perception, as well as inexact matches of CAD database models to real observations. We thus propose DiffCAD, the first weakly-supervised probabilistic approach to CAD retrieval and alignment from an RGB image. We formulate this as a conditional generative task, leveraging diffusion to learn implicit probabilistic models capturing the shape, pose, and scale of CAD objects in an image. This enables multi-hypothesis generation of different plausible CAD reconstructions, requiring only a few hypotheses to characterize ambiguities in depth/scale and inexact shape matches. Our approach is trained only on synthetic data, leveraging monocular depth and mask estimates to enable robust zero-shot adaptation to various real target domains. Despite being trained solely on synthetic data, our multi-hypothesis approach can even surpass the supervised state-of-the-art on the Scan2CAD dataset by 5.9% with 8 hypotheses.
Create account to get full access
Overview
- This paper presents DiffCAD, a weakly-supervised approach for retrieving and aligning 3D CAD models from a single RGB image.
- DiffCAD uses a probabilistic model to estimate the 3D pose and shape of an object in an image, without requiring any 3D ground truth annotations.
- The model is trained using differentiable rendering, which allows it to be optimized end-to-end using only 2D image data.
- DiffCAD demonstrates strong performance on benchmark datasets for 3D object retrieval and pose estimation.
Plain English Explanation
DiffCAD is a new computer vision system that can identify 3D CAD (computer-aided design) models that match objects in a 2D photograph, and also estimate the 3D pose and shape of those objects. Typically, training these kinds of 3D recognition systems requires having a lot of 3D ground truth data, which can be expensive and time-consuming to obtain.
Instead, DiffCAD uses a probabilistic approach that can be trained using just 2D photographs, without needing any 3D annotations. It does this by incorporating a differentiable rendering step into the model, which allows it to be optimized end-to-end using only the 2D image data. In other words, the model can learn to match 2D photos to 3D CAD models and estimate their 3D properties, just by looking at the 2D images, without any explicit 3D supervision.
This weakly-supervised approach makes DiffCAD more practical and scalable than previous methods that required 3D ground truth data. The paper shows that DiffCAD performs well on standard benchmarks for 3D object retrieval and pose estimation, demonstrating the power of this new technique.
Technical Explanation
DiffCAD is a deep learning-based system for retrieving and aligning 3D CAD models from a single RGB image. It uses a probabilistic model to estimate the 3D pose and shape of an object in an image, without requiring any 3D ground truth annotations during training.
The core innovation of DiffCAD is its use of differentiable rendering, which allows the model to be optimized end-to-end using only 2D image data. Specifically, the model consists of an encoder network that takes in the input image and predicts the latent parameters of a 3D CAD model, along with its 3D pose. These latent parameters are then fed into a differentiable renderer, which generates a 2D rendering of the predicted 3D object. This rendering is compared to the input image, and the model is trained to minimize the difference between them.
By incorporating this differentiable rendering step, DiffCAD can be trained in a weakly-supervised manner, without needing any 3D ground truth data. The model learns to match 2D images to 3D CAD models and estimate their 3D properties, simply by observing the correspondences between the input images and the renderings.
The paper demonstrates that DiffCAD achieves strong performance on benchmark datasets for 3D object retrieval and pose estimation, outperforming previous state-of-the-art methods that required 3D supervision. This highlights the power of the weakly-supervised, differentiable rendering-based approach used in DiffCAD.
Critical Analysis
The paper presents a compelling approach to 3D object recognition that is more scalable and practical than previous methods that required 3D ground truth data. By using differentiable rendering, DiffCAD is able to learn effective 3D representations from 2D image data alone, which is a significant advancement.
That said, the paper does not fully address the limitations of this approach. For example, the performance of DiffCAD may be sensitive to the quality and diversity of the 3D CAD model database used during training. If the database does not contain accurate or representative models, the system's predictions may be inaccurate or biased.
Additionally, the paper does not explore how well DiffCAD would generalize to real-world scenarios with varying lighting conditions, occlusions, and background clutter. The experiments are conducted on relatively simple and controlled datasets, and it's unclear how the model would perform in more complex, unconstrained environments.
Further research is needed to better understand the robustness and scalability of the DiffCAD approach, as well as its potential biases and limitations. Nonetheless, the core idea of using differentiable rendering for weakly-supervised 3D object recognition is a significant contribution to the field.
Conclusion
The DiffCAD paper presents a novel approach to 3D object retrieval and pose estimation that leverages differentiable rendering to enable weakly-supervised training. This is a significant advancement over previous methods that required expensive 3D ground truth data.
By demonstrating strong performance on benchmark datasets, DiffCAD shows the potential of this differentiable rendering-based, weakly-supervised approach to scale 3D object recognition to real-world applications. While the current system has some limitations, the core ideas behind DiffCAD represent an important step forward in making 3D computer vision more practical and accessible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
ContrastCAD: Contrastive Learning-based Representation Learning for Computer-Aided Design Models
Minseop Jung, Minseong Kim, Jibum Kim
0
0
The success of Transformer-based models has encouraged many researchers to learn CAD models using sequence-based approaches. However, learning CAD models is still a challenge, because they can be represented as complex shapes with long construction sequences. Furthermore, the same CAD model can be expressed using different CAD construction sequences. We propose a novel contrastive learning-based approach, named ContrastCAD, that effectively captures semantic information within the construction sequences of the CAD model. ContrastCAD generates augmented views using dropout techniques without altering the shape of the CAD model. We also propose a new CAD data augmentation method, called a Random Replace and Extrude (RRE) method, to enhance the learning performance of the model when training an imbalanced training CAD dataset. Experimental results show that the proposed RRE augmentation method significantly enhances the learning performance of Transformer-based autoencoders, even for complex CAD models having very long construction sequences. The proposed ContrastCAD model is shown to be robust to permutation changes of construction sequences and performs better representation learning by generating representation spaces where similar CAD models are more closely clustered. Our codes are available at https://github.com/cm8908/ContrastCAD.
4/3/2024

Self-supervised Graph Neural Network for Mechanical CAD Retrieval
Yuhan Quan, Huan Zhao, Jinfeng Yi, Yuqiang Chen
0
0
CAD (Computer-Aided Design) plays a crucial role in mechanical industry, where large numbers of similar-shaped CAD parts are often created. Efficiently reusing these parts is key to reducing design and production costs for enterprises. Retrieval systems are vital for achieving CAD reuse, but the complex shapes of CAD models are difficult to accurately describe using text or keywords, making traditional retrieval methods ineffective. While existing representation learning approaches have been developed for CAD, manually labeling similar samples in these methods is expensive. Additionally, CAD models' unique parameterized data structure presents challenges for applying existing 3D shape representation learning techniques directly. In this work, we propose GC-CAD, a self-supervised contrastive graph neural network-based method for mechanical CAD retrieval that directly models parameterized CAD raw files. GC-CAD consists of two key modules: structure-aware representation learning and contrastive graph learning framework. The method leverages graph neural networks to extract both geometric and topological information from CAD models, generating feature representations. We then introduce a simple yet effective contrastive graph learning framework approach, enabling the model to train without manual labels and generate retrieval-ready representations. Experimental results on four datasets including human evaluation demonstrate that the proposed method achieves significant accuracy improvements and up to 100 times efficiency improvement over the baseline methods.
6/19/2024

PT43D: A Probabilistic Transformer for Generating 3D Shapes from Single Highly-Ambiguous RGB Images
Yiheng Xiong, Angela Dai
0
0
Generating 3D shapes from single RGB images is essential in various applications such as robotics. Current approaches typically target images containing clear and complete visual descriptions of the object, without considering common realistic cases where observations of objects that are largely occluded or truncated. We thus propose a transformer-based autoregressive model to generate the probabilistic distribution of 3D shapes conditioned on an RGB image containing potentially highly ambiguous observations of the object. To handle realistic scenarios such as occlusion or field-of-view truncation, we create simulated image-to-shape training pairs that enable improved fine-tuning for real-world scenarios. We then adopt cross-attention to effectively identify the most relevant region of interest from the input image for shape generation. This enables inference of sampled shapes with reasonable diversity and strong alignment with the input image. We train and test our model on our synthetic data then fine-tune and test it on real-world data. Experiments demonstrate that our model outperforms state of the art in both scenarios
5/21/2024
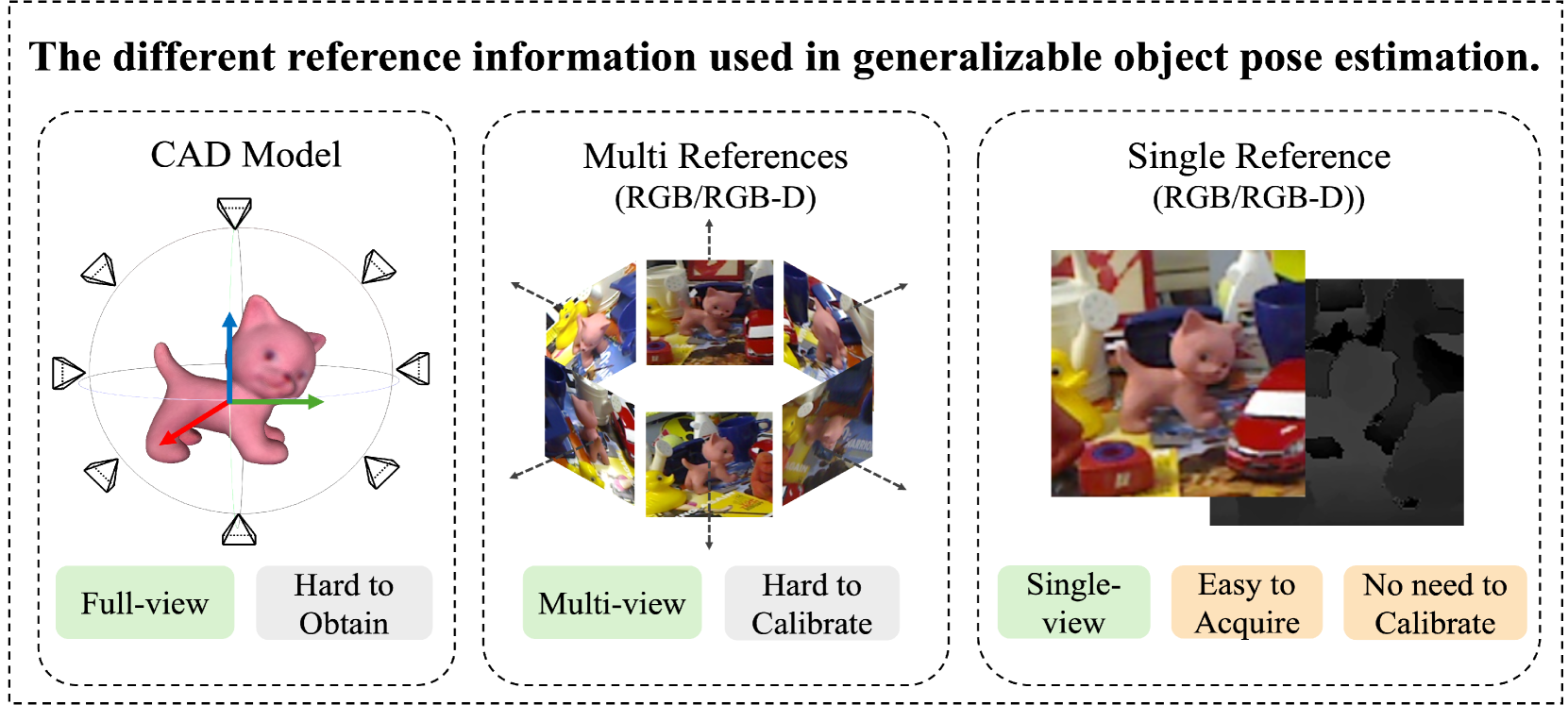
Towards Human-Level 3D Relative Pose Estimation: Generalizable, Training-Free, with Single Reference
Yuan Gao, Yajing Luo, Junhong Wang, Kui Jia, Gui-Song Xia
0
0
Humans can easily deduce the relative pose of an unseen object, without label/training, given only a single query-reference image pair. This is arguably achieved by incorporating (i) 3D/2.5D shape perception from a single image, (ii) render-and-compare simulation, and (iii) rich semantic cue awareness to furnish (coarse) reference-query correspondence. Existing methods implement (i) by a 3D CAD model or well-calibrated multiple images and (ii) by training a network on specific objects, which necessitate laborious ground-truth labeling and tedious training, potentially leading to challenges in generalization. Moreover, (iii) was less exploited in the paradigm of (ii), despite that the coarse correspondence from (iii) enhances the compare process by filtering out non-overlapped parts under substantial pose differences/occlusions. Motivated by this, we propose a novel 3D generalizable relative pose estimation method by elaborating (i) with a 2.5D shape from an RGB-D reference, (ii) with an off-the-shelf differentiable renderer, and (iii) with semantic cues from a pretrained model like DINOv2. Specifically, our differentiable renderer takes the 2.5D rotatable mesh textured by the RGB and the semantic maps (obtained by DINOv2 from the RGB input), then renders new RGB and semantic maps (with back-surface culling) under a novel rotated view. The refinement loss comes from comparing the rendered RGB and semantic maps with the query ones, back-propagating the gradients through the differentiable renderer to refine the 3D relative pose. As a result, our method can be readily applied to unseen objects, given only a single RGB-D reference, without label/training. Extensive experiments on LineMOD, LM-O, and YCB-V show that our training-free method significantly outperforms the SOTA supervised methods, especially under the rigorous Acc@5/10/15{deg} metrics and the challenging cross-dataset settings.
6/27/2024