Towards Human-Level 3D Relative Pose Estimation: Generalizable, Training-Free, with Single Reference

0
Sign in to get full access
Overview
- This paper presents a novel approach to 3D relative pose estimation that aims to achieve human-level performance.
- Key features of the method include generalizability, training-free operation, and the use of a single reference image.
- The method utilizes a differentiable renderer to enable zero-shot unseen generalization and a label/training-free refinement process.
Plain English Explanation
The research described in this paper tackles the challenge of estimating the 3D relative pose between objects or people in an image. This is an important capability for various computer vision applications, such as 3D pose estimation, object detection and tracking, and augmented reality.
The key innovation of this approach is its ability to generalize to a wide range of scenarios, including "unseen" cases, without requiring extensive training or labeling of data. The method uses a differentiable renderer, which is a type of computer graphics algorithm that can be integrated into neural networks and optimized end-to-end. This enables the system to learn to estimate 3D poses directly from a single reference image, without the need for labeled training data.
The paper also introduces a "label/training-free refinement" process, which allows the system to further improve its pose estimates by iteratively refining the 3D models based on the input image, without relying on any ground truth annotations. This makes the system more robust and scalable, as it can be applied to a wide variety of scenarios without the need for expensive data collection and annotation efforts.
Overall, this research represents an important step towards achieving human-level performance in 3D relative pose estimation, with potential applications in areas like robotics, augmented reality, and computer-aided design.
Technical Explanation
The core of the proposed approach is a differentiable renderer, which allows the system to learn to estimate 3D poses directly from a single reference image, without the need for labeled training data. The differentiable renderer acts as a bridge between the 3D scene representation and the 2D image, enabling the network to optimize the 3D pose parameters end-to-end using gradient-based methods.
The researchers also introduce a "label/training-free refinement" process, which allows the system to further improve its pose estimates by iteratively refining the 3D models based on the input image. This is achieved by using the differentiable renderer to generate a synthetic 2D image from the current 3D pose estimate, and then comparing this to the input image to compute a loss function that can be used to update the 3D pose parameters.
One of the key advantages of this approach is its ability to generalize to "unseen" scenarios, thanks to the use of the differentiable renderer. By learning to estimate 3D poses directly from the image, the system can be applied to a wide range of objects and scenes without the need for extensive training on labeled data.
The paper presents extensive experimental results, demonstrating the effectiveness of the proposed method on a variety of 3D pose estimation tasks, including object pose estimation and multi-person 3D pose estimation. The authors show that their approach outperforms state-of-the-art methods, particularly in scenarios involving unseen objects or poses.
Critical Analysis
One potential limitation of the proposed approach is its reliance on a differentiable renderer, which may be computationally expensive and require specialized hardware for efficient implementation. The paper does not provide a detailed analysis of the runtime and resource requirements of the system, which could be an important consideration for real-world applications.
Additionally, while the method demonstrates strong performance on the evaluated benchmarks, it is not clear how well it would generalize to more complex or highly occluded scenes, where the 3D pose estimation task becomes significantly more challenging. Further research and testing in more diverse and challenging environments would be valuable to better understand the limits of this approach.
Another area for potential improvement is the integration of the method with other computer vision techniques, such as object detection or segmentation, to enable more comprehensive scene understanding and further enhance the utility of the 3D pose estimation capabilities.
Conclusion
Overall, this research represents an exciting advance in the field of 3D relative pose estimation, with the potential to enable more robust and scalable solutions for a wide range of computer vision applications. The use of a differentiable renderer and the label/training-free refinement process are particularly noteworthy contributions that could inspire future work in this area.
As the field continues to evolve, it will be important to explore ways to address the potential limitations of the proposed approach and integrate it with other complementary techniques to create even more powerful and versatile tools for 3D scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Human-Level 3D Relative Pose Estimation: Generalizable, Training-Free, with Single Reference
Yuan Gao, Yajing Luo, Junhong Wang, Kui Jia, Gui-Song Xia
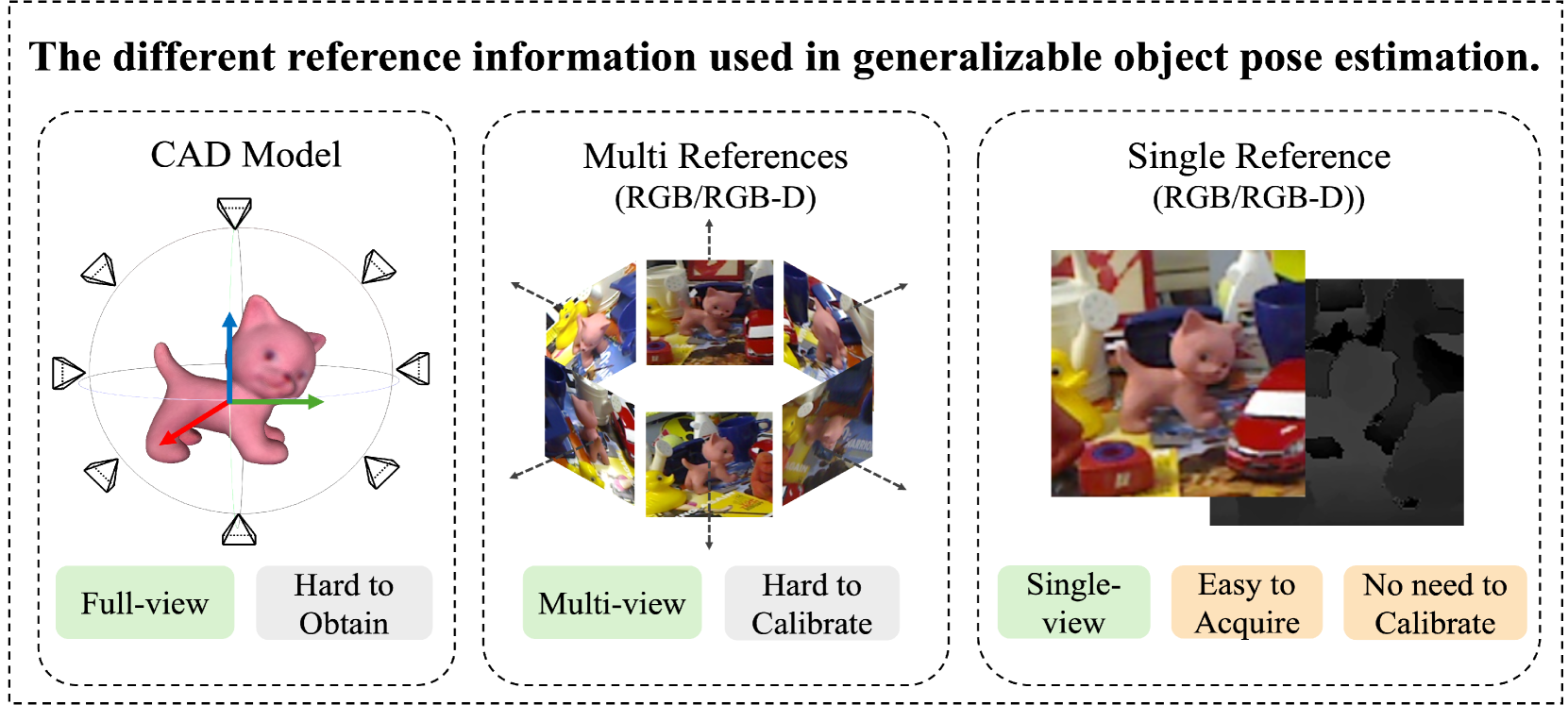
Humans can easily deduce the relative pose of an unseen object, without label/training, given only a single query-reference image pair. This is arguably achieved by incorporating (i) 3D/2.5D shape perception from a single image, (ii) render-and-compare simulation, and (iii) rich semantic cue awareness to furnish (coarse) reference-query correspondence. Existing methods implement (i) by a 3D CAD model or well-calibrated multiple images and (ii) by training a network on specific objects, which necessitate laborious ground-truth labeling and tedious training, potentially leading to challenges in generalization. Moreover, (iii) was less exploited in the paradigm of (ii), despite that the coarse correspondence from (iii) enhances the compare process by filtering out non-overlapped parts under substantial pose differences/occlusions. Motivated by this, we propose a novel 3D generalizable relative pose estimation method by elaborating (i) with a 2.5D shape from an RGB-D reference, (ii) with an off-the-shelf differentiable renderer, and (iii) with semantic cues from a pretrained model like DINOv2. Specifically, our differentiable renderer takes the 2.5D rotatable mesh textured by the RGB and the semantic maps (obtained by DINOv2 from the RGB input), then renders new RGB and semantic maps (with back-surface culling) under a novel rotated view. The refinement loss comes from comparing the rendered RGB and semantic maps with the query ones, back-propagating the gradients through the differentiable renderer to refine the 3D relative pose. As a result, our method can be readily applied to unseen objects, given only a single RGB-D reference, without label/training. Extensive experiments on LineMOD, LM-O, and YCB-V show that our training-free method significantly outperforms the SOTA supervised methods, especially under the rigorous Acc@5/10/15{deg} metrics and the challenging cross-dataset settings.
Read more6/27/2024

0
Unsupervised Learning of Category-Level 3D Pose from Object-Centric Videos
Leonhard Sommer, Artur Jesslen, Eddy Ilg, Adam Kortylewski
Category-level 3D pose estimation is a fundamentally important problem in computer vision and robotics, e.g. for embodied agents or to train 3D generative models. However, so far methods that estimate the category-level object pose require either large amounts of human annotations, CAD models or input from RGB-D sensors. In contrast, we tackle the problem of learning to estimate the category-level 3D pose only from casually taken object-centric videos without human supervision. We propose a two-step pipeline: First, we introduce a multi-view alignment procedure that determines canonical camera poses across videos with a novel and robust cyclic distance formulation for geometric and appearance matching using reconstructed coarse meshes and DINOv2 features. In a second step, the canonical poses and reconstructed meshes enable us to train a model for 3D pose estimation from a single image. In particular, our model learns to estimate dense correspondences between images and a prototypical 3D template by predicting, for each pixel in a 2D image, a feature vector of the corresponding vertex in the template mesh. We demonstrate that our method outperforms all baselines at the unsupervised alignment of object-centric videos by a large margin and provides faithful and robust predictions in-the-wild. Our code and data is available at https://github.com/GenIntel/uns-obj-pose3d.
Read more7/8/2024
📊
0
Multi-person 3D pose estimation from unlabelled data
Daniel Rodriguez-Criado, Pilar Bachiller, George Vogiatzis, Luis J. Manso
Its numerous applications make multi-human 3D pose estimation a remarkably impactful area of research. Nevertheless, assuming a multiple-view system composed of several regular RGB cameras, 3D multi-pose estimation presents several challenges. First of all, each person must be uniquely identified in the different views to separate the 2D information provided by the cameras. Secondly, the 3D pose estimation process from the multi-view 2D information of each person must be robust against noise and potential occlusions in the scenario. In this work, we address these two challenges with the help of deep learning. Specifically, we present a model based on Graph Neural Networks capable of predicting the cross-view correspondence of the people in the scenario along with a Multilayer Perceptron that takes the 2D points to yield the 3D poses of each person. These two models are trained in a self-supervised manner, thus avoiding the need for large datasets with 3D annotations.
Read more4/10/2024

0
FoundPose: Unseen Object Pose Estimation with Foundation Features
Evin P{i}nar Ornek, Yann Labb'e, Bugra Tekin, Lingni Ma, Cem Keskin, Christian Forster, Tomas Hodan
We propose FoundPose, a model-based method for 6D pose estimation of unseen objects from a single RGB image. The method can quickly onboard new objects using their 3D models without requiring any object- or task-specific training. In contrast, existing methods typically pre-train on large-scale, task-specific datasets in order to generalize to new objects and to bridge the image-to-model domain gap. We demonstrate that such generalization capabilities can be observed in a recent vision foundation model trained in a self-supervised manner. Specifically, our method estimates the object pose from image-to-model 2D-3D correspondences, which are established by matching patch descriptors from the recent DINOv2 model between the image and pre-rendered object templates. We find that reliable correspondences can be established by kNN matching of patch descriptors from an intermediate DINOv2 layer. Such descriptors carry stronger positional information than descriptors from the last layer, and we show their importance when semantic information is ambiguous due to object symmetries or a lack of texture. To avoid establishing correspondences against all object templates, we develop an efficient template retrieval approach that integrates the patch descriptors into the bag-of-words representation and can promptly propose a handful of similarly looking templates. Additionally, we apply featuremetric alignment to compensate for discrepancies in the 2D-3D correspondences caused by coarse patch sampling. The resulting method noticeably outperforms existing RGB methods for refinement-free pose estimation on the standard BOP benchmark with seven diverse datasets and can be seamlessly combined with an existing render-and-compare refinement method to achieve RGB-only state-of-the-art results. Project page: evinpinar.github.io/foundpose.
Read more7/22/2024