Differential Privacy for Anomaly Detection: Analyzing the Trade-off Between Privacy and Explainability

0

Sign in to get full access
Overview
- This paper explores the trade-off between privacy and explainability in the context of anomaly detection using differential privacy.
- The researchers analyze the impact of applying differential privacy techniques on the performance and interpretability of anomaly detection models.
- They investigate how different levels of privacy protection affect the ability to explain the model's decisions and identify anomalies.
Plain English Explanation
Differential privacy is a technique used to protect the privacy of individuals in a dataset by adding controlled noise to the data. This helps prevent the identification of specific individuals while still allowing useful insights to be extracted from the data.
<a href="https://aimodels.fyi/papers/arxiv/from-theory-to-comprehension-comparative-study-differential">Differential privacy</a> is particularly important when dealing with sensitive or personal information, as it allows for the analysis of data without compromising the privacy of the individuals involved.
In the context of anomaly detection, the researchers in this paper explored how applying differential privacy affects the ability to identify unusual or suspicious patterns in the data, and how well the model can explain the reasons for its decisions.
<a href="https://aimodels.fyi/papers/arxiv/generalization-face-adaptivity-bayesian-perspective">Anomaly detection</a> is a crucial task in many applications, such as fraud detection, network security, and quality control, where identifying unusual or unexpected events is crucial. However, it's also important that the model can explain its decisions, so that users can understand why certain patterns are flagged as anomalies.
The researchers investigated the trade-off between maintaining individual privacy and preserving the model's ability to accurately and transparently detect anomalies. By understanding this trade-off, they aim to help researchers and practitioners make informed decisions about balancing privacy and explainability in their anomaly detection systems.
Technical Explanation
The researchers used a <a href="https://aimodels.fyi/papers/arxiv/aaa-adaptive-mechanism-locally-differential-private-mean">differentially private version</a> of the Isolation Forest algorithm, a popular unsupervised anomaly detection technique, to evaluate the impact of privacy-preserving mechanisms on the model's performance and interpretability.
They conducted experiments on several real-world datasets, varying the level of privacy protection (i.e., the privacy budget) and analyzing the resulting effects on the model's ability to detect anomalies and explain its decisions. The researchers measured the trade-off between privacy and explainability using metrics such as the F1-score for anomaly detection and the fidelity of the model's explanations.
The results showed that as the level of privacy protection increased (i.e., more noise was added to the data), the anomaly detection performance generally decreased, but the model's ability to explain its decisions improved. Conversely, when the privacy protection was reduced, the anomaly detection performance increased, but the explainability of the model's decisions decreased.
The researchers also <a href="https://aimodels.fyi/papers/arxiv/provable-privacy-non-private-pre-processing">explored techniques</a> to mitigate the impact of privacy on explainability, such as using post-hoc explanation methods to provide additional insights into the model's decision-making process.
Critical Analysis
The paper provides a valuable contribution to the field of <a href="https://aimodels.fyi/papers/arxiv/incentives-private-collaborative-machine-learning">privacy-preserving machine learning</a>, particularly in the context of anomaly detection, where the trade-off between privacy and explainability is a crucial concern.
One limitation of the study is that it focuses on a specific anomaly detection algorithm (Isolation Forest) and may not fully capture the nuances of the privacy-explainability trade-off in other anomaly detection techniques. Further research could explore the generalizability of the findings to a broader range of anomaly detection algorithms and datasets.
Additionally, the paper does not delve into the potential real-world implications and practical challenges of implementing such privacy-preserving anomaly detection systems. Exploring the deployment and user acceptance of these systems would be an important next step in understanding the broader impact of this research.
Conclusion
This paper provides valuable insights into the complex relationship between differential privacy and the explainability of anomaly detection models. By analyzing the trade-off between privacy and model interpretability, the researchers offer guidance to practitioners and researchers on how to balance these competing objectives when developing anomaly detection systems.
The findings suggest that there is no one-size-fits-all solution, and that the optimal balance between privacy and explainability will depend on the specific requirements and constraints of the application domain. This underscores the importance of carefully considering the unique needs and priorities of each use case when designing privacy-preserving machine learning systems.
Overall, this research contributes to the growing body of work on the intersection of differential privacy and explainable AI, and highlights the need for continued exploration and innovation in this important area of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Differential Privacy for Anomaly Detection: Analyzing the Trade-off Between Privacy and Explainability
Fatima Ezzeddine, Mirna Saad, Omran Ayoub, Davide Andreoletti, Martin Gjoreski, Ihab Sbeity, Marc Langheinrich, Silvia Giordano
Anomaly detection (AD), also referred to as outlier detection, is a statistical process aimed at identifying observations within a dataset that significantly deviate from the expected pattern of the majority of the data. Such a process finds wide application in various fields, such as finance and healthcare. While the primary objective of AD is to yield high detection accuracy, the requirements of explainability and privacy are also paramount. The first ensures the transparency of the AD process, while the second guarantees that no sensitive information is leaked to untrusted parties. In this work, we exploit the trade-off of applying Explainable AI (XAI) through SHapley Additive exPlanations (SHAP) and differential privacy (DP). We perform AD with different models and on various datasets, and we thoroughly evaluate the cost of privacy in terms of decreased accuracy and explainability. Our results show that the enforcement of privacy through DP has a significant impact on detection accuracy and explainability, which depends on both the dataset and the considered AD model. We further show that the visual interpretation of explanations is also influenced by the choice of the AD algorithm.
Read more4/10/2024

0
Explainable Hyperdimensional Computing for Balancing Privacy and Transparency in Additive Manufacturing Monitoring
Fardin Jalil Piran, Prathyush P. Poduval, Hamza Errahmouni Barkam, Mohsen Imani, Farhad Imani
In-situ sensing, in conjunction with learning models, presents a unique opportunity to address persistent defect issues in Additive Manufacturing (AM) processes. However, this integration introduces significant data privacy concerns, such as data leakage, sensor data compromise, and model inversion attacks, revealing critical details about part design, material composition, and machine parameters. Differential Privacy (DP) models, which inject noise into data under mathematical guarantees, offer a nuanced balance between data utility and privacy by obscuring traces of sensing data. However, the introduction of noise into learning models, often functioning as black boxes, complicates the prediction of how specific noise levels impact model accuracy. This study introduces the Differential Privacy-HyperDimensional computing (DP-HD) framework, leveraging the explainability of the vector symbolic paradigm to predict the noise impact on the accuracy of in-situ monitoring, safeguarding sensitive data while maintaining operational efficiency. Experimental results on real-world high-speed melt pool data of AM for detecting overhang anomalies demonstrate that DP-HD achieves superior operational efficiency, prediction accuracy, and robust privacy protection, outperforming state-of-the-art Machine Learning (ML) models. For example, when implementing the same level of privacy protection (with a privacy budget set at 1), our model achieved an accuracy of 94.43%, surpassing the performance of traditional models such as ResNet50 (52.30%), GoogLeNet (23.85%), AlexNet (55.78%), DenseNet201 (69.13%), and EfficientNet B2 (40.81%). Notably, DP-HD maintains high performance under substantial noise additions designed to enhance privacy, unlike current models that suffer significant accuracy declines under high privacy constraints.
Read more7/11/2024

0
ATTAXONOMY: Unpacking Differential Privacy Guarantees Against Practical Adversaries
Rachel Cummings, Shlomi Hod, Jayshree Sarathy, Marika Swanberg
Differential Privacy (DP) is a mathematical framework that is increasingly deployed to mitigate privacy risks associated with machine learning and statistical analyses. Despite the growing adoption of DP, its technical privacy parameters do not lend themselves to an intelligible description of the real-world privacy risks associated with that deployment: the guarantee that most naturally follows from the DP definition is protection against membership inference by an adversary who knows all but one data record and has unlimited auxiliary knowledge. In many settings, this adversary is far too strong to inform how to set real-world privacy parameters. One approach for contextualizing privacy parameters is via defining and measuring the success of technical attacks, but doing so requires a systematic categorization of the relevant attack space. In this work, we offer a detailed taxonomy of attacks, showing the various dimensions of attacks and highlighting that many real-world settings have been understudied. Our taxonomy provides a roadmap for analyzing real-world deployments and developing theoretical bounds for more informative privacy attacks. We operationalize our taxonomy by using it to analyze a real-world case study, the Israeli Ministry of Health's recent release of a birth dataset using DP, showing how the taxonomy enables fine-grained threat modeling and provides insight towards making informed privacy parameter choices. Finally, we leverage the taxonomy towards defining a more realistic attack than previously considered in the literature, namely a distributional reconstruction attack: we generalize Balle et al.'s notion of reconstruction robustness to a less-informed adversary with distributional uncertainty, and extend the worst-case guarantees of DP to this average-case setting.
Read more5/6/2024
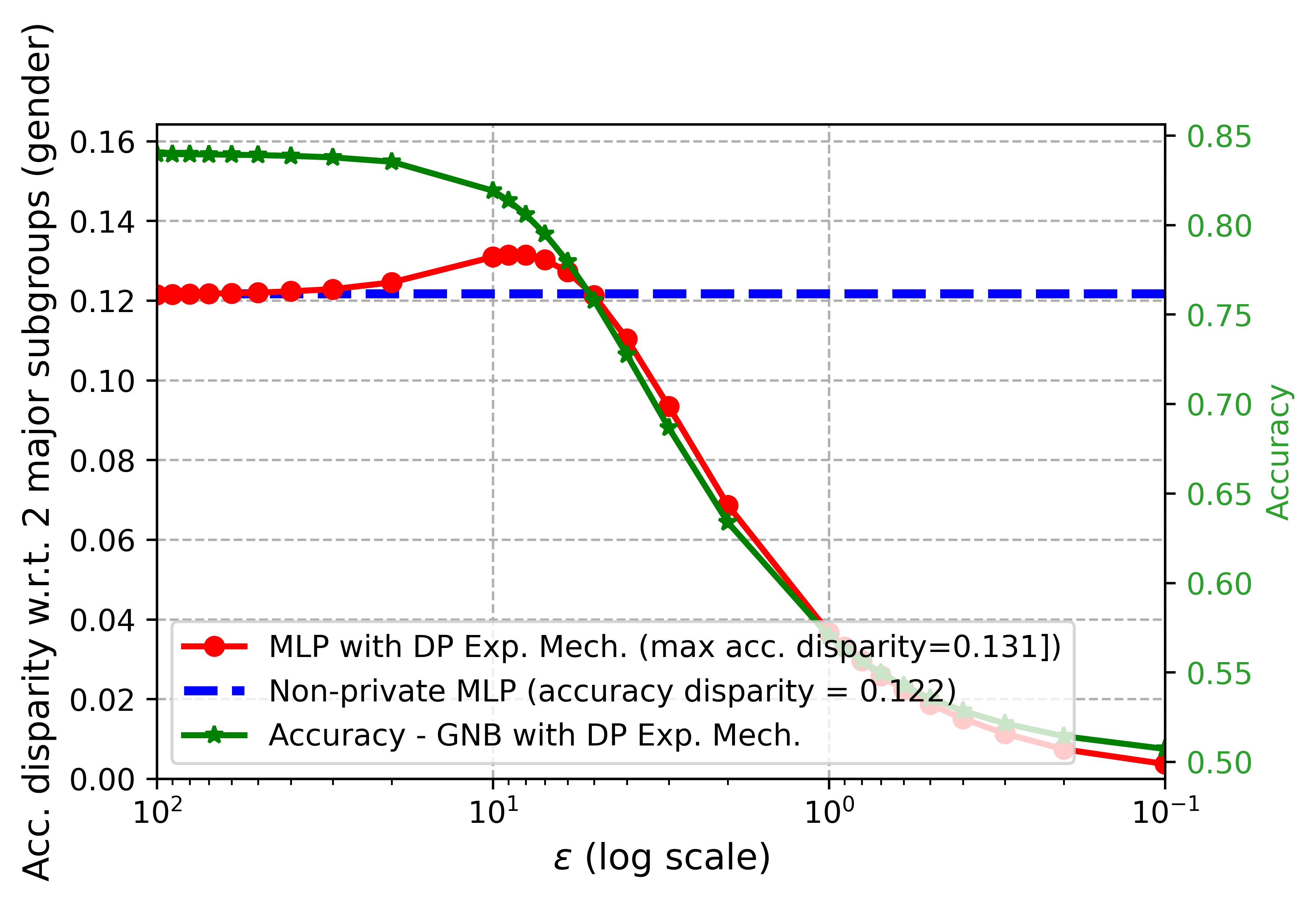
0
Privacy at a Price: Exploring its Dual Impact on AI Fairness
Mengmeng Yang, Ming Ding, Youyang Qu, Wei Ni, David Smith, Thierry Rakotoarivelo
The worldwide adoption of machine learning (ML) and deep learning models, particularly in critical sectors, such as healthcare and finance, presents substantial challenges in maintaining individual privacy and fairness. These two elements are vital to a trustworthy environment for learning systems. While numerous studies have concentrated on protecting individual privacy through differential privacy (DP) mechanisms, emerging research indicates that differential privacy in machine learning models can unequally impact separate demographic subgroups regarding prediction accuracy. This leads to a fairness concern, and manifests as biased performance. Although the prevailing view is that enhancing privacy intensifies fairness disparities, a smaller, yet significant, subset of research suggests the opposite view. In this article, with extensive evaluation results, we demonstrate that the impact of differential privacy on fairness is not monotonous. Instead, we observe that the accuracy disparity initially grows as more DP noise (enhanced privacy) is added to the ML process, but subsequently diminishes at higher privacy levels with even more noise. Moreover, implementing gradient clipping in the differentially private stochastic gradient descent ML method can mitigate the negative impact of DP noise on fairness. This mitigation is achieved by moderating the disparity growth through a lower clipping threshold.
Read more4/16/2024