Differentially Private Data Release on Graphs: Inefficiencies and Unfairness

0

Sign in to get full access
Overview
- This paper examines the challenges and unfairness that can arise when using differential privacy to release data on graphs.
- The researchers found that existing differential privacy techniques can lead to significant information loss and unfair outcomes for certain subgroups in the data.
- They propose new approaches to address these issues and provide a comprehensive analysis of the trade-offs involved.
Plain English Explanation
Differential privacy is a technique used to protect people's privacy when sharing data. The idea is to add a small amount of "noise" or randomness to the data so that it's hard to identify individuals. This allows the data to be shared publicly without compromising people's privacy.
However, the paper shows that when using differential privacy on graph data (like social networks), there can be some significant downsides. The researchers found that existing techniques can lead to a lot of information being lost, making the data much less useful. They also discovered that the noise added to protect privacy can unfairly impact certain groups in the data more than others.
For example, if the graph represents a social network, the differential privacy techniques might end up hiding important details about smaller or marginalized communities, while preserving more information about larger or dominant groups. This could lead to biased or inaccurate analyses.
The paper proposes new ways to apply differential privacy to graph data that aim to address these issues. The goal is to find a better balance between protecting privacy and maintaining the usefulness and fairness of the shared data.
Technical Explanation
The paper starts by highlighting the growing importance of differentially private data release on graph-structured data, such as social networks, communication networks, and biological networks. While differential privacy provides strong privacy guarantees, the researchers show that existing approaches can lead to significant information loss and unfair outcomes.
To demonstrate these issues, the paper conducts a systematic empirical evaluation of several differentially private graph release techniques. The experiments assess the utility of the released data across different graph properties and downstream tasks, as well as the fairness of the outcomes for different subgroups within the data.
The results reveal that existing differentially private graph release methods can suffer from substantial information loss, making the shared data much less useful for analysis and decision-making. Moreover, the researchers find that the noise added to preserve privacy can disproportionately affect certain subgroups, leading to unfair and potentially biased outcomes.
To address these limitations, the paper proposes new differentially private graph release algorithms that aim to improve both utility and fairness. These approaches incorporate techniques like adaptive noise addition and targeted subgroup preservation to better balance the privacy-utility-fairness trade-off.
Critical Analysis
The paper provides a comprehensive and rigorous analysis of the challenges faced when applying differential privacy to graph-structured data. The researchers acknowledge that while differential privacy offers strong privacy guarantees, the current techniques can lead to significant inefficiencies and unfairness.
One potential limitation of the study is that it focuses primarily on evaluating the utility and fairness of the released data, without extensively exploring the privacy implications. While the paper shows that existing methods can lead to unfair outcomes, it would be valuable to also assess the actual level of privacy protection provided by the proposed approaches.
Additionally, the paper does not delve deeply into the computational complexity and scalability of the new differentially private graph release algorithms. As real-world graph datasets can be extremely large and complex, it would be important to understand the practical feasibility of implementing these techniques in various application scenarios.
Conclusion
The paper makes a significant contribution to the field of differentially private data release by highlighting the important challenges of inefficiency and unfairness that can arise when applying these techniques to graph-structured data. The proposed solutions represent an important step towards addressing these issues and finding a better balance between privacy, utility, and fairness.
As the use of graph data continues to grow across various domains, such as social networks, communication networks, and biology, the insights from this paper will be crucial for developing more effective and equitable data sharing practices. The findings and recommendations presented here can inform the design of future differentially private data release algorithms and spur further research in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Differentially Private Data Release on Graphs: Inefficiencies and Unfairness
Ferdinando Fioretto, Diptangshu Sen, Juba Ziani
Networks are crucial components of many sectors, including telecommunications, healthcare, finance, energy, and transportation.The information carried in such networks often contains sensitive user data, like location data for commuters and packet data for online users. Therefore, when considering data release for networks, one must ensure that data release mechanisms do not leak information about individuals, quantified in a precise mathematical sense. Differential Privacy (DP) is the widely accepted, formal, state-of-the-art technique, which has found use in a variety of real-life settings including the 2020 U.S. Census, Apple users' device data, or Google's location data. Yet, the use of DP comes with new challenges, as the noise added for privacy introduces inaccuracies or biases and further, DP techniques can also distribute these biases disproportionately across different populations, inducing fairness issues. The goal of this paper is to characterize the impact of DP on bias and unfairness in the context of releasing information about networks, taking a departure from previous work which has studied these effects in the context of private population counts release (such as in the U.S. Census). To this end, we consider a network release problem where the network structure is known to all, but the weights on edges must be released privately. We consider the impact of this private release on a simple downstream decision-making task run by a third-party, which is to find the shortest path between any two pairs of nodes and recommend the best route to users. This setting is of highly practical relevance, mirroring scenarios in transportation networks, where preserving privacy while providing accurate routing information is crucial. Our work provides theoretical foundations and empirical evidence into the bias and unfairness arising due to privacy in these networked decision problems.
Read more8/13/2024
🤷
0
A Systematic and Formal Study of the Impact of Local Differential Privacy on Fairness: Preliminary Results
Karima Makhlouf, Tamara Stefanovic, Heber H. Arcolezi, Catuscia Palamidessi
Machine learning (ML) algorithms rely primarily on the availability of training data, and, depending on the domain, these data may include sensitive information about the data providers, thus leading to significant privacy issues. Differential privacy (DP) is the predominant solution for privacy-preserving ML, and the local model of DP is the preferred choice when the server or the data collector are not trusted. Recent experimental studies have shown that local DP can impact ML prediction for different subgroups of individuals, thus affecting fair decision-making. However, the results are conflicting in the sense that some studies show a positive impact of privacy on fairness while others show a negative one. In this work, we conduct a systematic and formal study of the effect of local DP on fairness. Specifically, we perform a quantitative study of how the fairness of the decisions made by the ML model changes under local DP for different levels of privacy and data distributions. In particular, we provide bounds in terms of the joint distributions and the privacy level, delimiting the extent to which local DP can impact the fairness of the model. We characterize the cases in which privacy reduces discrimination and those with the opposite effect. We validate our theoretical findings on synthetic and real-world datasets. Our results are preliminary in the sense that, for now, we study only the case of one sensitive attribute, and only statistical disparity, conditional statistical disparity, and equal opportunity difference.
Read more5/24/2024
❗
0
What to Consider When Considering Differential Privacy for Policy
Priyanka Nanayakkara, Jessica Hullman
Differential privacy (DP) is a mathematical definition of privacy that can be widely applied when publishing data. DP has been recognized as a potential means of adhering to various privacy-related legal requirements. However, it can be difficult to reason about whether DP may be appropriate for a given context due to tensions that arise when it is brought from theory into practice. To aid policymaking around privacy concerns, we identify three categories of challenges to understanding DP along with associated questions that policymakers can ask about the potential deployment context to anticipate its impacts.
Read more9/19/2024
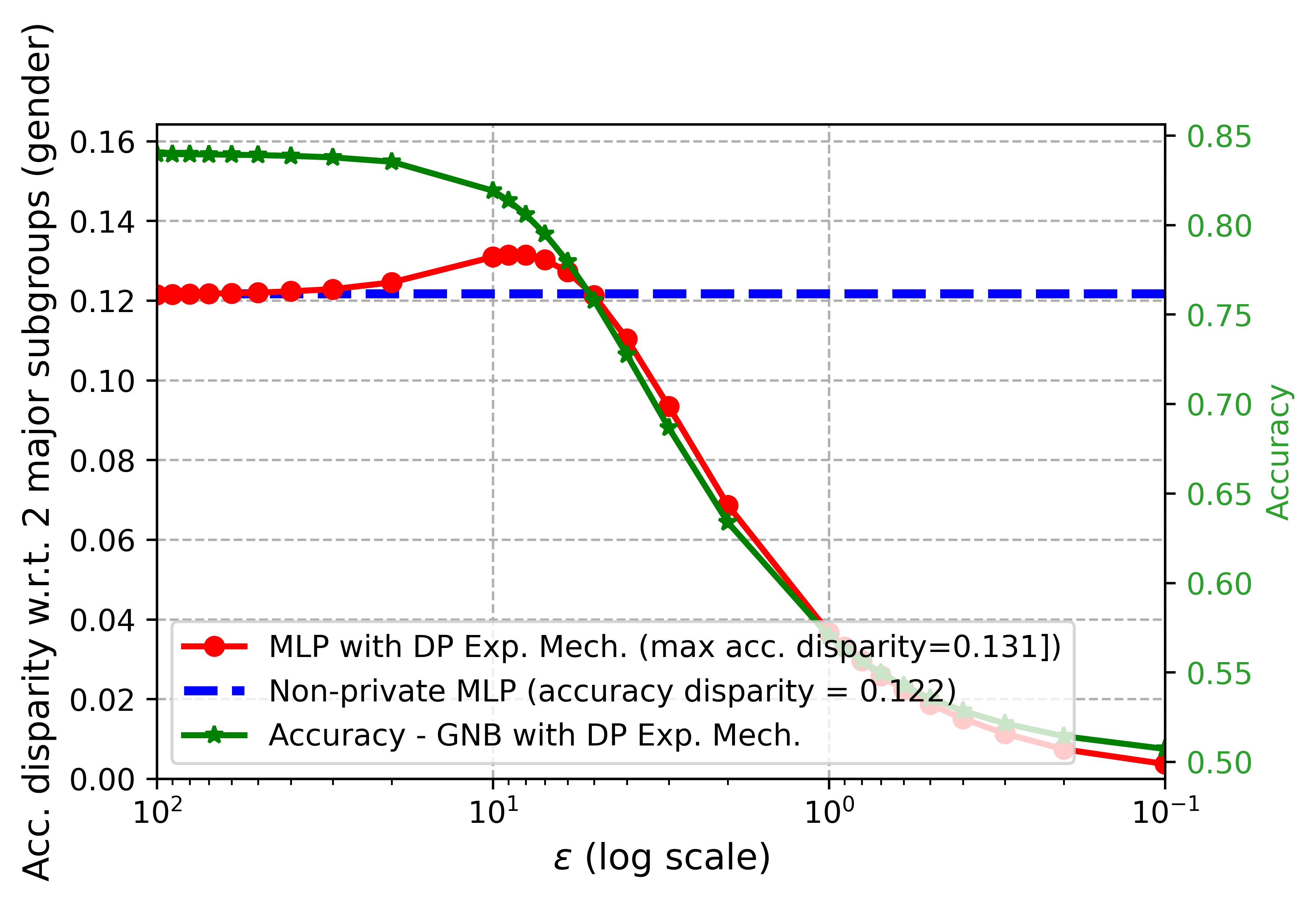
0
Privacy at a Price: Exploring its Dual Impact on AI Fairness
Mengmeng Yang, Ming Ding, Youyang Qu, Wei Ni, David Smith, Thierry Rakotoarivelo
The worldwide adoption of machine learning (ML) and deep learning models, particularly in critical sectors, such as healthcare and finance, presents substantial challenges in maintaining individual privacy and fairness. These two elements are vital to a trustworthy environment for learning systems. While numerous studies have concentrated on protecting individual privacy through differential privacy (DP) mechanisms, emerging research indicates that differential privacy in machine learning models can unequally impact separate demographic subgroups regarding prediction accuracy. This leads to a fairness concern, and manifests as biased performance. Although the prevailing view is that enhancing privacy intensifies fairness disparities, a smaller, yet significant, subset of research suggests the opposite view. In this article, with extensive evaluation results, we demonstrate that the impact of differential privacy on fairness is not monotonous. Instead, we observe that the accuracy disparity initially grows as more DP noise (enhanced privacy) is added to the ML process, but subsequently diminishes at higher privacy levels with even more noise. Moreover, implementing gradient clipping in the differentially private stochastic gradient descent ML method can mitigate the negative impact of DP noise on fairness. This mitigation is achieved by moderating the disparity growth through a lower clipping threshold.
Read more4/16/2024