DiffGEPCI: 3D MRI Synthesis from mGRE Signals using 2.5D Diffusion Model
2311.18073
0
0
📈
Abstract
We introduce a new framework called DiffGEPCI for cross-modality generation in magnetic resonance imaging (MRI) using a 2.5D conditional diffusion model. DiffGEPCI can synthesize high-quality Fluid Attenuated Inversion Recovery (FLAIR) and Magnetization Prepared-Rapid Gradient Echo (MPRAGE) images, without acquiring corresponding measurements, by leveraging multi-Gradient-Recalled Echo (mGRE) MRI signals as conditional inputs. DiffGEPCI operates in a two-step fashion: it initially estimates a 3D volume slice-by-slice using the axial plane and subsequently applies a refinement algorithm (referred to as 2.5D) to enhance the quality of the coronal and sagittal planes. Experimental validation on real mGRE data shows that DiffGEPCI achieves excellent performance, surpassing generative adversarial networks (GANs) and traditional diffusion models.
Create account to get full access
Overview
- Introduces a new framework called DiffGEPCI for cross-modality generation in magnetic resonance imaging (MRI) using a 2.5D conditional diffusion model.
- DiffGEPCI can synthesize high-quality Fluid Attenuated Inversion Recovery (FLAIR) and Magnetization Prepared-Rapid Gradient Echo (MPRAGE) images without acquiring corresponding measurements, by leveraging multi-Gradient-Recalled Echo (mGRE) MRI signals as conditional inputs.
- DiffGEPCI operates in a two-step fashion: it initially estimates a 3D volume slice-by-slice using the axial plane and subsequently applies a refinement algorithm (referred to as 2.5D) to enhance the quality of the coronal and sagittal planes.
- Experimental validation on real mGRE data shows that DiffGEPCI achieves excellent performance, surpassing generative adversarial networks (GANs) and traditional diffusion models.
Plain English Explanation
DiffGEPCI is a new framework that can generate high-quality brain MRI images without needing to physically scan the brain. It does this by using a special type of MRI data called multi-Gradient-Recalled Echo (mGRE) as input to a machine learning model. The model first estimates a 3D volume of the brain using just the axial (top-down) plane, and then refines the coronal (side) and sagittal (front-back) planes to enhance the overall image quality.
This is significant because generating accurate MRI images without having to scan the brain could save time and resources, especially in situations where repeated scans are required, such as for monitoring disease progression or treatment response. By leveraging existing mGRE data, DiffGEPCI can produce synthetic Fluid Attenuated Inversion Recovery (FLAIR) and Magnetization Prepared-Rapid Gradient Echo (MPRAGE) images that are better than those generated by existing techniques like generative adversarial networks (GANs) and traditional diffusion models.
Technical Explanation
DiffGEPCI uses a 2.5D conditional diffusion model to synthesize FLAIR and MPRAGE images from mGRE data. This means the model first generates a 3D volume of the brain slice-by-slice using the axial plane, and then applies a refinement algorithm to enhance the quality of the coronal and sagittal planes.
The key innovation of DiffGEPCI is its ability to leverage multi-Gradient-Recalled Echo (mGRE) MRI signals as conditional inputs to the model. mGRE is a type of MRI acquisition that captures multiple echoes, providing additional information about the scanned tissue. By using mGRE data as the conditional input, DiffGEPCI can generate high-quality FLAIR and MPRAGE images without the need for corresponding measurements.
Experimental results on real mGRE data show that DiffGEPCI outperforms both generative adversarial networks (GANs) and traditional diffusion models in terms of image quality and fidelity. This suggests that the conditional diffusion approach and the use of mGRE data as input are effective for cross-modality MRI image synthesis.
Critical Analysis
The paper provides a thorough evaluation of DiffGEPCI, including comparisons to other state-of-the-art methods. However, the authors acknowledge some limitations:
- The current implementation of DiffGEPCI is limited to 2.5D synthesis, and extending it to true 3D synthesis may further improve the image quality.
- The model was trained and evaluated on a relatively small dataset, and its performance on larger, more diverse datasets remains to be investigated.
- The paper does not explore the potential clinical applications or implications of the proposed framework, which would be an important next step.
Additionally, while DiffGEPCI demonstrates impressive results, it is essential to consider the broader implications of synthetic medical imaging data. Potential concerns around the ethical use of such technology, data privacy, and model robustness should be carefully addressed as the field of conditional diffusion models continues to evolve.
Conclusion
DiffGEPCI introduces a novel framework for cross-modality MRI image synthesis using a 2.5D conditional diffusion model. By leveraging mGRE data as conditional inputs, the model can generate high-quality FLAIR and MPRAGE images without the need for corresponding measurements. The experimental results demonstrate that DiffGEPCI outperforms existing methods, highlighting the potential of this approach for applications that require repeated MRI scans or where physical scanning is not feasible.
While the paper provides a solid technical foundation, further research is needed to address the identified limitations and explore the broader implications of synthetic medical imaging data. As the field of conditional diffusion models continues to advance, it will be crucial to ensure that these technologies are developed and deployed responsibly, with a focus on their potential benefits and ethical considerations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
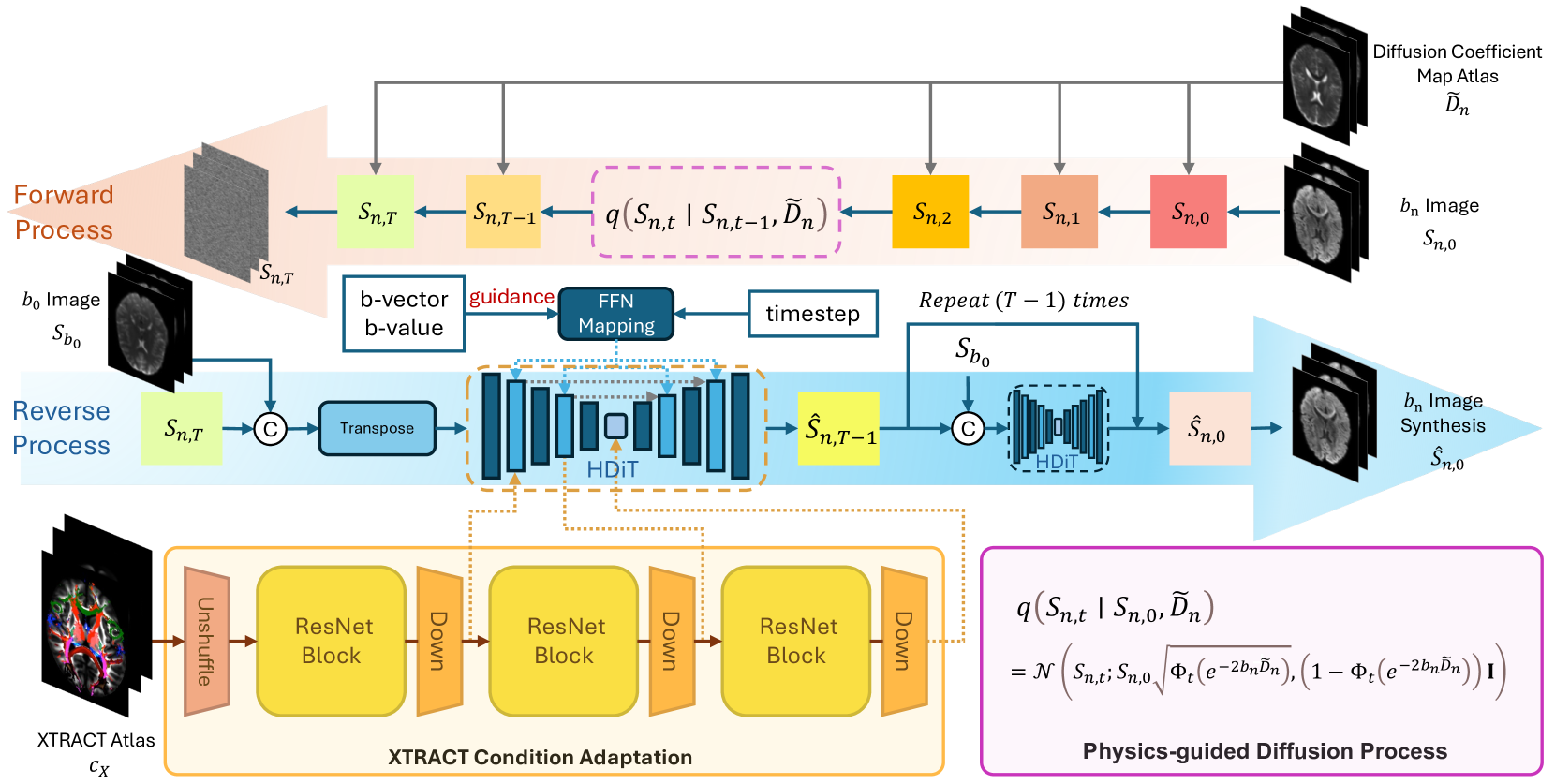
Phy-Diff: Physics-guided Hourglass Diffusion Model for Diffusion MRI Synthesis
Juanhua Zhang, Ruodan Yan, Alessandro Perelli, Xi Chen, Chao Li
0
0
Diffusion MRI (dMRI) is an important neuroimaging technique with high acquisition costs. Deep learning approaches have been used to enhance dMRI and predict diffusion biomarkers through undersampled dMRI. To generate more comprehensive raw dMRI, generative adversarial network based methods are proposed to include b-values and b-vectors as conditions, but they are limited by unstable training and less desirable diversity. The emerging diffusion model (DM) promises to improve generative performance. However, it remains challenging to include essential information in conditioning DM for more relevant generation, i.e., the physical principles of dMRI and white matter tract structures. In this study, we propose a physics-guided diffusion model to generate high-quality dMRI. Our model introduces the physical principles of dMRI in the noise evolution in the diffusion process and introduce a query-based conditional mapping within the difussion model. In addition, to enhance the anatomical fine detials of the generation, we introduce the XTRACT atlas as prior of white matter tracts by adopting an adapter technique. Our experiment results show that our method outperforms other state-of-the-art methods and has the potential to advance dMRI enhancement.
6/6/2024

Generative Enhancement for 3D Medical Images
Lingting Zhu, Noel Codella, Dongdong Chen, Zhenchao Jin, Lu Yuan, Lequan Yu
0
0
The limited availability of 3D medical image datasets, due to privacy concerns and high collection or annotation costs, poses significant challenges in the field of medical imaging. While a promising alternative is the use of synthesized medical data, there are few solutions for realistic 3D medical image synthesis due to difficulties in backbone design and fewer 3D training samples compared to 2D counterparts. In this paper, we propose GEM-3D, a novel generative approach to the synthesis of 3D medical images and the enhancement of existing datasets using conditional diffusion models. Our method begins with a 2D slice, noted as the informed slice to serve the patient prior, and propagates the generation process using a 3D segmentation mask. By decomposing the 3D medical images into masks and patient prior information, GEM-3D offers a flexible yet effective solution for generating versatile 3D images from existing datasets. GEM-3D can enable dataset enhancement by combining informed slice selection and generation at random positions, along with editable mask volumes to introduce large variations in diffusion sampling. Moreover, as the informed slice contains patient-wise information, GEM-3D can also facilitate counterfactual image synthesis and dataset-level de-enhancement with desired control. Experiments on brain MRI and abdomen CT images demonstrate that GEM-3D is capable of synthesizing high-quality 3D medical images with volumetric consistency, offering a straightforward solution for dataset enhancement during inference. The code is available at https://github.com/HKU-MedAI/GEM-3D.
5/27/2024
✅
Conditional Diffusion Models for Semantic 3D Brain MRI Synthesis
Zolnamar Dorjsembe, Hsing-Kuo Pao, Sodtavilan Odonchimed, Furen Xiao
0
0
Artificial intelligence (AI) in healthcare, especially in medical imaging, faces challenges due to data scarcity and privacy concerns. Addressing these, we introduce Med-DDPM, a diffusion model designed for 3D semantic brain MRI synthesis. This model effectively tackles data scarcity and privacy issues by integrating semantic conditioning. This involves the channel-wise concatenation of a conditioning image to the model input, enabling control in image generation. Med-DDPM demonstrates superior stability and performance compared to existing 3D brain imaging synthesis methods. It generates diverse, anatomically coherent images with high visual fidelity. In terms of dice score accuracy in the tumor segmentation task, Med-DDPM achieves 0.6207, close to the 0.6531 accuracy of real images, and outperforms baseline models. Combined with real images, it further increases segmentation accuracy to 0.6675, showing the potential of our proposed method for data augmentation. This model represents the first use of a diffusion model in 3D semantic brain MRI synthesis, producing high-quality images. Its semantic conditioning feature also shows potential for image anonymization in biomedical imaging, addressing data and privacy issues. We provide the code and model weights for Med-DDPM on our GitHub repository (https://github.com/mobaidoctor/med-ddpm/) to support reproducibility.
4/22/2024

CriDiff: Criss-cross Injection Diffusion Framework via Generative Pre-train for Prostate Segmentation
Tingwei Liu, Miao Zhang, Leiye Liu, Jialong Zhong, Shuyao Wang, Yongri Piao, Huchuan Lu
0
0
Recently, the Diffusion Probabilistic Model (DPM)-based methods have achieved substantial success in the field of medical image segmentation. However, most of these methods fail to enable the diffusion model to learn edge features and non-edge features effectively and to inject them efficiently into the diffusion backbone. Additionally, the domain gap between the images features and the diffusion model features poses a great challenge to prostate segmentation. In this paper, we proposed CriDiff, a two-stage feature injecting framework with a Crisscross Injection Strategy (CIS) and a Generative Pre-train (GP) approach for prostate segmentation. The CIS maximizes the use of multi-level features by efficiently harnessing the complementarity of high and low-level features. To effectively learn multi-level of edge features and non-edge features, we proposed two parallel conditioners in the CIS: the Boundary Enhance Conditioner (BEC) and the Core Enhance Conditioner (CEC), which discriminatively model the image edge regions and non-edge regions, respectively. Moreover, the GP approach eases the inconsistency between the images features and the diffusion model without adding additional parameters. Extensive experiments on four benchmark datasets demonstrate the effectiveness of the proposed method and achieve state-of-the-art performance on four evaluation metrics.
6/21/2024