Diffusion Features to Bridge Domain Gap for Semantic Segmentation
2406.00777
0
0

Abstract
Pre-trained diffusion models have demonstrated remarkable proficiency in synthesizing images across a wide range of scenarios with customizable prompts, indicating their effective capacity to capture universal features. Motivated by this, our study delves into the utilization of the implicit knowledge embedded within diffusion models to address challenges in cross-domain semantic segmentation. This paper investigates the approach that leverages the sampling and fusion techniques to harness the features of diffusion models efficiently. Contrary to the simplistic migration applications characterized by prior research, our finding reveals that the multi-step diffusion process inherent in the diffusion model manifests more robust semantic features. We propose DIffusion Feature Fusion (DIFF) as a backbone use for extracting and integrating effective semantic representations through the diffusion process. By leveraging the strength of text-to-image generation capability, we introduce a new training framework designed to implicitly learn posterior knowledge from it. Through rigorous evaluation in the contexts of domain generalization semantic segmentation, we establish that our methodology surpasses preceding approaches in mitigating discrepancies across distinct domains and attains the state-of-the-art (SOTA) benchmark. Within the synthetic-to-real (syn-to-real) context, our method significantly outperforms ResNet-based and transformer-based backbone methods, achieving an average improvement of $3.84%$ mIoU across various datasets. The implementation code will be released soon.
Create account to get full access
Overview
- This paper explores the use of diffusion features to bridge the domain gap in semantic segmentation tasks.
- Diffusion features are a type of image representation that can capture both local and global information, making them potentially useful for tasks that require understanding complex scenes.
- The authors propose a novel architecture that incorporates diffusion features to improve the performance of semantic segmentation models on target domains, even when the training and target domains are very different.
Plain English Explanation
The main idea of this paper is to use a new type of image representation called "diffusion features" to help improve the performance of semantic segmentation models when they are applied to a different domain than the one they were trained on.
Semantic segmentation is the task of labeling each pixel in an image with the object or material it represents. This is a challenging problem because the appearance of objects can vary a lot depending on factors like lighting, camera angle, and the surrounding environment.
The authors propose using diffusion features to help the segmentation model better understand the content of the images, even when they are from a different domain than the training data. Diffusion features are a way of representing images that can capture both local details and global context.
By incorporating these diffusion features into the segmentation model, the authors were able to improve its performance on target domains that were quite different from the training data. This is an important advance because it can help make these models more robust and useful in real-world applications where the environment may vary significantly from the training data.
Technical Explanation
The key technical contribution of this paper is a novel architecture that integrates diffusion features into a semantic segmentation model to improve its performance on target domains.
The authors first extract diffusion features from the input images using a pre-trained diffusion model. These features capture both local and global information about the image content, which can be helpful for understanding complex scenes.
The diffusion features are then concatenated with the features extracted by the segmentation model's encoder network. This allows the model to leverage the complementary information provided by the diffusion features to make more accurate predictions, even when the target domain is quite different from the training data.
The authors evaluate their approach on several standard semantic segmentation benchmarks, including PASCAL VOC and Cityscapes. They show that the diffusion feature-augmented model outperforms strong baselines, particularly when there is a significant domain gap between the training and target data.
Critical Analysis
One potential limitation of this approach is that it relies on having access to a pre-trained diffusion model, which may not always be available or easy to obtain. The authors do not provide much detail on how this diffusion model was trained or what kind of data it was trained on.
Additionally, the paper does not explore the use of subject-specific diffusion models or other personalized diffusion features that could potentially further improve the model's performance on target domains.
It would also be interesting to see how this approach compares to other domain adaptation techniques, such as adversarial training or self-supervised learning, in terms of both performance and computational cost.
Overall, this paper presents a promising new way to leverage diffusion features to bridge the domain gap in semantic segmentation, but there are still opportunities for further research and refinement of the approach.
Conclusion
This paper demonstrates the potential of using diffusion features to improve the performance of semantic segmentation models on target domains that are significantly different from the training data. By integrating diffusion features into the model architecture, the authors were able to achieve state-of-the-art results on several benchmark datasets.
The key insight is that diffusion features can capture both local and global image information, which can help the model better understand the complex scenes it is tasked with segmenting. This is an important step towards making these models more robust and practical for real-world applications, where the environment may vary considerably from the training data.
While there are still some open questions and areas for further research, this paper represents a significant advancement in the field of domain-adaptive semantic segmentation and highlights the value of exploring novel image representations like diffusion features.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
Diffusion Hyperfeatures: Searching Through Time and Space for Semantic Correspondence
Grace Luo, Lisa Dunlap, Dong Huk Park, Aleksander Holynski, Trevor Darrell
0
0
Diffusion models have been shown to be capable of generating high-quality images, suggesting that they could contain meaningful internal representations. Unfortunately, the feature maps that encode a diffusion model's internal information are spread not only over layers of the network, but also over diffusion timesteps, making it challenging to extract useful descriptors. We propose Diffusion Hyperfeatures, a framework for consolidating multi-scale and multi-timestep feature maps into per-pixel feature descriptors that can be used for downstream tasks. These descriptors can be extracted for both synthetic and real images using the generation and inversion processes. We evaluate the utility of our Diffusion Hyperfeatures on the task of semantic keypoint correspondence: our method achieves superior performance on the SPair-71k real image benchmark. We also demonstrate that our method is flexible and transferable: our feature aggregation network trained on the inversion features of real image pairs can be used on the generation features of synthetic image pairs with unseen objects and compositions. Our code is available at https://diffusion-hyperfeatures.github.io.
4/3/2024

New!Using diffusion model as constraint: Empower Image Restoration Network Training with Diffusion Model
Jiangtong Tan, Feng Zhao
0
0
Image restoration has made marvelous progress with the advent of deep learning. Previous methods usually rely on designing powerful network architecture to elevate performance, however, the natural visual effect of the restored results is limited by color and texture distortions. Besides the visual perceptual quality, the semantic perception recovery is an important but often overlooked perspective of restored image, which is crucial for the deployment in high-level tasks. In this paper, we propose a new perspective to resort these issues by introducing a naturalness-oriented and semantic-aware optimization mechanism, dubbed DiffLoss. Specifically, inspired by the powerful distribution coverage capability of the diffusion model for natural image generation, we exploit the Markov chain sampling property of diffusion model and project the restored results of existing networks into the sampling space. Besides, we reveal that the bottleneck feature of diffusion models, also dubbed h-space feature, is a natural high-level semantic space. We delve into this property and propose a semantic-aware loss to further unlock its potential of semantic perception recovery, which paves the way to connect image restoration task and downstream high-level recognition task. With these two strategies, the DiffLoss can endow existing restoration methods with both more natural and semantic-aware results. We verify the effectiveness of our method on substantial common image restoration tasks and benchmarks. Code will be available at https://github.com/JosephTiTan/DiffLoss.
6/28/2024
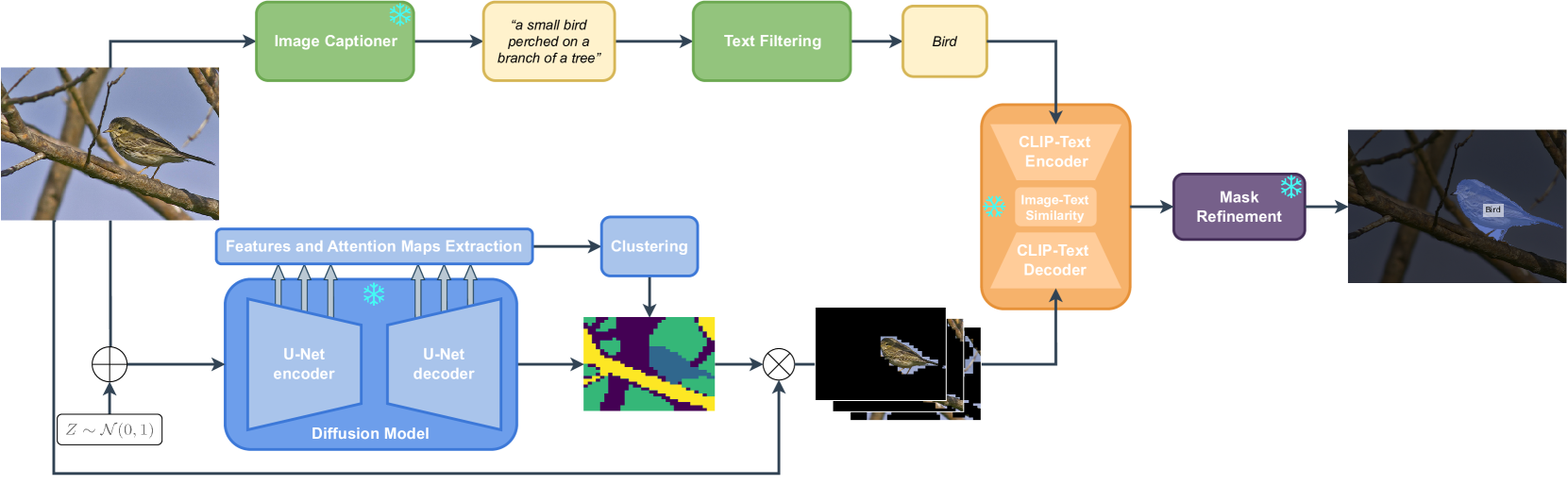
FreeSeg-Diff: Training-Free Open-Vocabulary Segmentation with Diffusion Models
Barbara Toniella Corradini, Mustafa Shukor, Paul Couairon, Guillaume Couairon, Franco Scarselli, Matthieu Cord
0
0
Foundation models have exhibited unprecedented capabilities in tackling many domains and tasks. Models such as CLIP are currently widely used to bridge cross-modal representations, and text-to-image diffusion models are arguably the leading models in terms of realistic image generation. Image generative models are trained on massive datasets that provide them with powerful internal spatial representations. In this work, we explore the potential benefits of such representations, beyond image generation, in particular, for dense visual prediction tasks. We focus on the task of image segmentation, which is traditionally solved by training models on closed-vocabulary datasets, with pixel-level annotations. To avoid the annotation cost or training large diffusion models, we constraint our setup to be zero-shot and training-free. In a nutshell, our pipeline leverages different and relatively small-sized, open-source foundation models for zero-shot open-vocabulary segmentation. The pipeline is as follows: the image is passed to both a captioner model (i.e. BLIP) and a diffusion model (i.e., Stable Diffusion Model) to generate a text description and visual representation, respectively. The features are clustered and binarized to obtain class agnostic masks for each object. These masks are then mapped to a textual class, using the CLIP model to support open-vocabulary. Finally, we add a refinement step that allows to obtain a more precise segmentation mask. Our approach (dubbed FreeSeg-Diff), which does not rely on any training, outperforms many training-based approaches on both Pascal VOC and COCO datasets. In addition, we show very competitive results compared to the recent weakly-supervised segmentation approaches. We provide comprehensive experiments showing the superiority of diffusion model features compared to other pretrained models. Project page: https://bcorrad.github.io/freesegdiff/
4/1/2024
🏋️
Exploring Limits of Diffusion-Synthetic Training with Weakly Supervised Semantic Segmentation
Ryota Yoshihashi, Yuya Otsuka, Kenji Doi, Tomohiro Tanaka, Hirokatsu Kataoka
0
0
The advance of generative models for images has inspired various training techniques for image recognition utilizing synthetic images. In semantic segmentation, one promising approach is extracting pseudo-masks from attention maps in text-to-image diffusion models, which enables real-image-and-annotation-free training. However, the pioneering training method using the diffusion-synthetic images and pseudo-masks, i.e., DiffuMask has limitations in terms of mask quality, scalability, and ranges of applicable domains. To overcome these limitations, this work introduces three techniques for diffusion-synthetic semantic segmentation training. First, reliability-aware robust training, originally used in weakly supervised learning, helps segmentation with insufficient synthetic mask quality. %Second, large-scale pretraining of whole segmentation models, not only backbones, on synthetic ImageNet-1k-class images with pixel-labels benefits downstream segmentation tasks. Second, we introduce prompt augmentation, data augmentation to the prompt text set to scale up and diversify training images with a limited text resources. Finally, LoRA-based adaptation of Stable Diffusion enables the transfer to a distant domain, e.g., auto-driving images. Experiments in PASCAL VOC, ImageNet-S, and Cityscapes show that our method effectively closes gap between real and synthetic training in semantic segmentation.
4/16/2024