Exploring Limits of Diffusion-Synthetic Training with Weakly Supervised Semantic Segmentation
2309.01369
0
0
🏋️
Abstract
The advance of generative models for images has inspired various training techniques for image recognition utilizing synthetic images. In semantic segmentation, one promising approach is extracting pseudo-masks from attention maps in text-to-image diffusion models, which enables real-image-and-annotation-free training. However, the pioneering training method using the diffusion-synthetic images and pseudo-masks, i.e., DiffuMask has limitations in terms of mask quality, scalability, and ranges of applicable domains. To overcome these limitations, this work introduces three techniques for diffusion-synthetic semantic segmentation training. First, reliability-aware robust training, originally used in weakly supervised learning, helps segmentation with insufficient synthetic mask quality. %Second, large-scale pretraining of whole segmentation models, not only backbones, on synthetic ImageNet-1k-class images with pixel-labels benefits downstream segmentation tasks. Second, we introduce prompt augmentation, data augmentation to the prompt text set to scale up and diversify training images with a limited text resources. Finally, LoRA-based adaptation of Stable Diffusion enables the transfer to a distant domain, e.g., auto-driving images. Experiments in PASCAL VOC, ImageNet-S, and Cityscapes show that our method effectively closes gap between real and synthetic training in semantic segmentation.
Create account to get full access
Overview
- The paper explores techniques for using synthetic images generated by diffusion models to train semantic segmentation models, aiming to reduce the need for real-world labeled data.
- The proposed methods include:
- Reliability-aware robust training to handle imperfect synthetic masks
- Large-scale pretraining of full segmentation models on synthetic data
- Prompt augmentation to scale up and diversify the synthetic training data
- LoRA-based adaptation to transfer the model to distant domains
Plain English Explanation
Generative models, like diffusion models, have made impressive progress at generating realistic-looking synthetic images. This has inspired researchers to explore using these synthetic images to train image recognition models, such as those used for semantic segmentation - the task of identifying and labeling different objects and regions in an image.
One promising approach is to extract pseudo-masks, or simulated label maps, directly from the attention patterns of the diffusion model. This enables training segmentation models without any real-world annotated data, through a process called diffusion-synthetic semantic segmentation.
However, the existing methods have limitations in terms of the quality of the synthetic masks, the scalability of the training process, and the ability to adapt the models to new domains. This paper introduces several techniques to address these challenges:
- Reliability-aware robust training: Borrowing ideas from weakly supervised learning, this approach helps the segmentation model cope with imperfect synthetic masks.
- Large-scale pretraining: The authors show that pretraining the full segmentation model, not just the backbone, on large-scale synthetic datasets can benefit downstream tasks.
- Prompt augmentation: By diversifying the text prompts used to generate the synthetic training images, the authors are able to scale up the available training data.
- LoRA-based adaptation: This technique allows the segmentation model to be efficiently transferred to new domains, such as autonomous driving images, without requiring a full model retraining.
The paper demonstrates the effectiveness of these methods on several benchmark datasets, showing that they can bridge the gap between training on real and synthetic data for semantic segmentation.
Technical Explanation
The paper introduces several techniques to improve the performance of semantic segmentation models trained on synthetic images generated by diffusion models:
-
Reliability-aware robust training: The authors observe that the pseudo-masks extracted from diffusion models can be imperfect, with errors and missing details. To address this, they adapt techniques from weakly supervised learning, which is designed to handle noisy or incomplete labels. This helps the segmentation model learn to produce accurate results despite the synthetic mask limitations.
-
Large-scale pretraining: Instead of only pretraining the backbone of the segmentation model, the authors show that pretraining the full model, including the head, on large-scale synthetic datasets (e.g., ImageNet-1k) can provide significant benefits for downstream segmentation tasks.
-
Prompt augmentation: To scale up and diversify the synthetic training data, the authors introduce prompt augmentation. This involves modifying the text prompts used to generate the synthetic images, allowing them to create a broader range of training samples from the same underlying diffusion model.
-
LoRA-based adaptation: To enable the segmentation model to be efficiently adapted to new domains, the authors use a technique called LoRA (Low-Rank Adaptation). This allows them to fine-tune the model on a target domain, such as autonomous driving images, without having to retrain the entire network from scratch.
The paper evaluates these techniques on several benchmarks, including PASCAL VOC, ImageNet-S, and Cityscapes, and demonstrates that they can effectively bridge the gap between training on real and synthetic data for semantic segmentation.
Critical Analysis
The paper presents a comprehensive set of techniques to address the limitations of the existing diffusion-synthetic semantic segmentation approaches. The authors demonstrate the effectiveness of their methods through extensive experiments, showcasing significant performance improvements on various benchmarks.
One potential limitation of the approach is the reliance on the quality of the pseudo-masks extracted from the diffusion models. While the proposed reliability-aware robust training helps mitigate the impact of imperfect masks, further advancements in mask generation or alternative techniques for leveraging diffusion models could potentially lead to even better results.
Additionally, the paper focuses on adapting the segmentation model to new domains using LoRA, which is an efficient fine-tuning approach. However, it would be interesting to explore other transfer learning techniques, such as using the synthetic data for pretraining and then fine-tuning on real-world data, to see if they can provide additional performance gains.
Overall, the paper presents a significant contribution to the field of diffusion-based synthetic data generation and its application to semantic segmentation. The proposed methods demonstrate the potential of leveraging generative models to reduce the reliance on expensive real-world annotated data, which could have important implications for practical deployment of image recognition systems.
Conclusion
This paper introduces several advanced techniques for training semantic segmentation models using synthetic images generated by diffusion models. By addressing key limitations of existing approaches, such as imperfect synthetic masks, scalability, and domain adaptation, the authors have made significant progress in bridging the gap between training on real and synthetic data.
The reliability-aware robust training, large-scale pretraining, prompt augmentation, and LoRA-based adaptation methods presented in this work represent a significant step forward in the field of diffusion-synthetic semantic segmentation. These techniques could have far-reaching implications, enabling more efficient and accessible development of robust image recognition models for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Diffusion Features to Bridge Domain Gap for Semantic Segmentation
Yuxiang Ji, Boyong He, Chenyuan Qu, Zhuoyue Tan, Chuan Qin, Liaoni Wu
0
0
Pre-trained diffusion models have demonstrated remarkable proficiency in synthesizing images across a wide range of scenarios with customizable prompts, indicating their effective capacity to capture universal features. Motivated by this, our study delves into the utilization of the implicit knowledge embedded within diffusion models to address challenges in cross-domain semantic segmentation. This paper investigates the approach that leverages the sampling and fusion techniques to harness the features of diffusion models efficiently. Contrary to the simplistic migration applications characterized by prior research, our finding reveals that the multi-step diffusion process inherent in the diffusion model manifests more robust semantic features. We propose DIffusion Feature Fusion (DIFF) as a backbone use for extracting and integrating effective semantic representations through the diffusion process. By leveraging the strength of text-to-image generation capability, we introduce a new training framework designed to implicitly learn posterior knowledge from it. Through rigorous evaluation in the contexts of domain generalization semantic segmentation, we establish that our methodology surpasses preceding approaches in mitigating discrepancies across distinct domains and attains the state-of-the-art (SOTA) benchmark. Within the synthetic-to-real (syn-to-real) context, our method significantly outperforms ResNet-based and transformer-based backbone methods, achieving an average improvement of $3.84%$ mIoU across various datasets. The implementation code will be released soon.
6/4/2024
📊
Using Diffusion Models to Generate Synthetic Labelled Data for Medical Image Segmentation
Daniel Saragih, Atsuhiro Hibi, Pascal Tyrrell
0
0
Medical image analysis has become a prominent area where machine learning has been applied. However, high quality, publicly available data is limited either due to patient privacy laws or the time and cost required for experts to annotate images. In this retrospective study, we designed and evaluated a pipeline to generate synthetic labeled polyp images for augmenting medical image segmentation models with the aim of reducing this data scarcity. In particular, we trained diffusion models on the HyperKvasir dataset, comprising 1000 images of polyps in the human GI tract from 2008 to 2016. Qualitative expert review, Fr'echet Inception Distance (FID), and Multi-Scale Structural Similarity (MS-SSIM) were tested for evaluation. Additionally, various segmentation models were trained with the generated data and evaluated using Dice score and Intersection over Union. We found that our pipeline produced images more akin to real polyp images based on FID scores, and segmentation performance also showed improvements over GAN methods when trained entirely, or partially, with synthetic data, despite requiring less compute for training. Moreover, the improvement persists when tested on different datasets, showcasing the transferability of the generated images.
5/13/2024
🔄
Mind the Gap Between Synthetic and Real: Utilizing Transfer Learning to Probe the Boundaries of Stable Diffusion Generated Data
Leonhard Hennicke, Christian Medeiros Adriano, Holger Giese, Jan Mathias Koehler, Lukas Schott
0
0
Generative foundation models like Stable Diffusion comprise a diverse spectrum of knowledge in computer vision with the potential for transfer learning, e.g., via generating data to train student models for downstream tasks. This could circumvent the necessity of collecting labeled real-world data, thereby presenting a form of data-free knowledge distillation. However, the resultant student models show a significant drop in accuracy compared to models trained on real data. We investigate possible causes for this drop and focus on the role of the different layers of the student model. By training these layers using either real or synthetic data, we reveal that the drop mainly stems from the model's final layers. Further, we briefly investigate other factors, such as differences in data-normalization between synthetic and real, the impact of data augmentations, texture vs. shape learning, and assuming oracle prompts. While we find that some of those factors can have an impact, they are not sufficient to close the gap towards real data. Building upon our insights that mainly later layers are responsible for the drop, we investigate the data-efficiency of fine-tuning a synthetically trained model with real data applied to only those last layers. Our results suggest an improved trade-off between the amount of real training data used and the model's accuracy. Our findings contribute to the understanding of the gap between synthetic and real data and indicate solutions to mitigate the scarcity of labeled real data.
5/7/2024
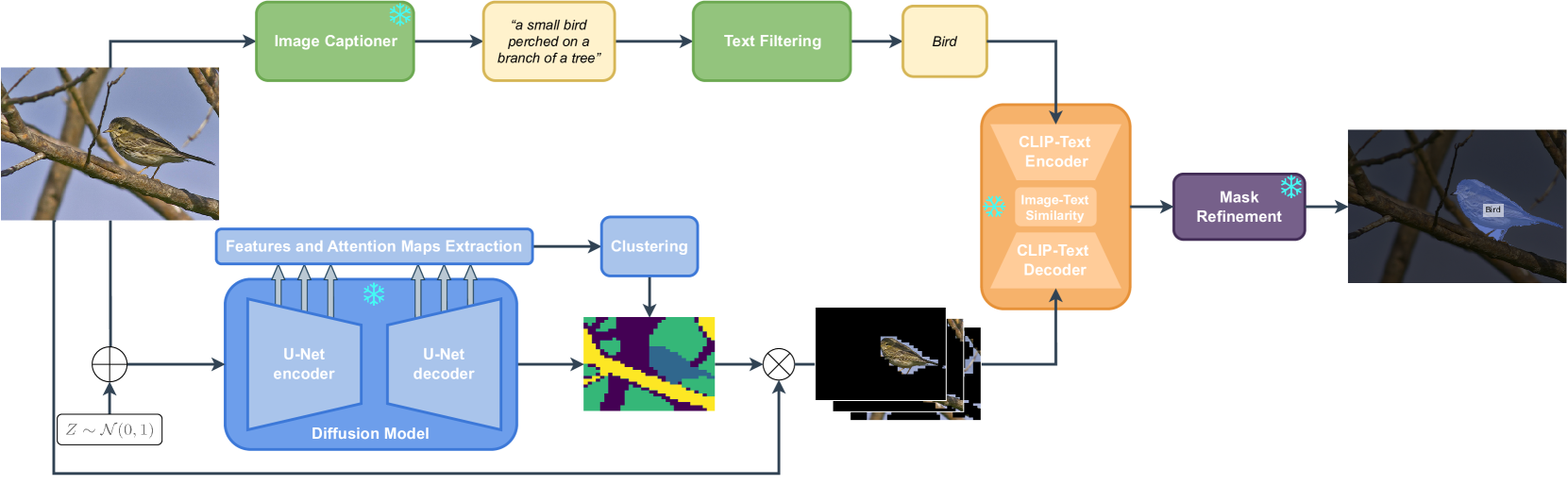
FreeSeg-Diff: Training-Free Open-Vocabulary Segmentation with Diffusion Models
Barbara Toniella Corradini, Mustafa Shukor, Paul Couairon, Guillaume Couairon, Franco Scarselli, Matthieu Cord
0
0
Foundation models have exhibited unprecedented capabilities in tackling many domains and tasks. Models such as CLIP are currently widely used to bridge cross-modal representations, and text-to-image diffusion models are arguably the leading models in terms of realistic image generation. Image generative models are trained on massive datasets that provide them with powerful internal spatial representations. In this work, we explore the potential benefits of such representations, beyond image generation, in particular, for dense visual prediction tasks. We focus on the task of image segmentation, which is traditionally solved by training models on closed-vocabulary datasets, with pixel-level annotations. To avoid the annotation cost or training large diffusion models, we constraint our setup to be zero-shot and training-free. In a nutshell, our pipeline leverages different and relatively small-sized, open-source foundation models for zero-shot open-vocabulary segmentation. The pipeline is as follows: the image is passed to both a captioner model (i.e. BLIP) and a diffusion model (i.e., Stable Diffusion Model) to generate a text description and visual representation, respectively. The features are clustered and binarized to obtain class agnostic masks for each object. These masks are then mapped to a textual class, using the CLIP model to support open-vocabulary. Finally, we add a refinement step that allows to obtain a more precise segmentation mask. Our approach (dubbed FreeSeg-Diff), which does not rely on any training, outperforms many training-based approaches on both Pascal VOC and COCO datasets. In addition, we show very competitive results compared to the recent weakly-supervised segmentation approaches. We provide comprehensive experiments showing the superiority of diffusion model features compared to other pretrained models. Project page: https://bcorrad.github.io/freesegdiff/
4/1/2024