Dinomaly: The Less Is More Philosophy in Multi-Class Unsupervised Anomaly Detection
2405.14325
0
0
🤷
Abstract
Recent studies highlighted a practical setting of unsupervised anomaly detection (UAD) that builds a unified model for multi-class images, serving as an alternative to the conventional one-class-one-model setup. Despite various advancements addressing this challenging task, the detection performance under the multi-class setting still lags far behind state-of-the-art class-separated models. Our research aims to bridge this substantial performance gap. In this paper, we introduce a minimalistic reconstruction-based anomaly detection framework, namely Dinomaly, which leverages pure Transformer architectures without relying on complex designs, additional modules, or specialized tricks. Given this powerful framework consisted of only Attentions and MLPs, we found four simple components that are essential to multi-class anomaly detection: (1) Foundation Transformers that extracts universal and discriminative features, (2) Noisy Bottleneck where pre-existing Dropouts do all the noise injection tricks, (3) Linear Attention that naturally cannot focus, and (4) Loose Reconstruction that does not force layer-to-layer and point-by-point reconstruction. Extensive experiments are conducted across three popular anomaly detection benchmarks including MVTec-AD, VisA, and the recently released Real-IAD. Our proposed Dinomaly achieves impressive image AUROC of 99.6%, 98.7%, and 89.3% on the three datasets respectively, which is not only superior to state-of-the-art multi-class UAD methods, but also surpasses the most advanced class-separated UAD records.
Create account to get full access
Overview
- Introduces a new reconstruction-based anomaly detection framework called Dinomaly that uses transformer architectures
- Aims to bridge the performance gap between multi-class and class-separated anomaly detection models
- Achieves state-of-the-art results on popular anomaly detection benchmarks
Plain English Explanation
Anomaly detection is the task of identifying unusual or unexpected data points in a dataset. Traditionally, anomaly detection models are trained separately for each class of data, which can be time-consuming and inefficient. This research explores a more unified approach where a single model is trained to detect anomalies across multiple classes of data.
The paper introduces a new anomaly detection framework called Dinomaly that uses transformer architectures, which are a type of neural network commonly used for natural language processing tasks. Dinomaly is designed to be minimalistic, relying only on attention mechanisms and multi-layer perceptrons (MLPs) without any complex additional components.
The key ideas behind Dinomaly are:
- Foundation Transformers: These extract universal and discriminative features from the input data.
- Noisy Bottleneck: This injects noise into the data, which can help the model learn more robust representations.
- Linear Attention: This attention mechanism is unable to focus on specific parts of the input, which can be beneficial for anomaly detection.
- Loose Reconstruction: The model does not enforce exact reconstruction of the input, but rather learns a more flexible representation.
By incorporating these simple yet effective components, Dinomaly is able to achieve state-of-the-art performance on several popular anomaly detection benchmarks, including MVTec-AD, VisA, and Real-IAD. This is particularly impressive given that Dinomaly is a unified model, whereas the previous state-of-the-art methods relied on separate models for each class of data.
Technical Explanation
The paper proposes a new reconstruction-based anomaly detection framework called Dinomaly that leverages transformer architectures to achieve state-of-the-art performance on multi-class anomaly detection tasks.
The core components of Dinomaly are:
-
Foundation Transformers: These are standard transformer encoder layers that extract universal and discriminative features from the input data. The authors found that using multiple foundation transformers can capture a more diverse set of features.
-
Noisy Bottleneck: This is a simple mechanism that injects noise into the latent representations learned by the foundation transformers. The authors found that this noise injection, which is implemented using pre-existing dropout layers, helps the model learn more robust representations.
-
Linear Attention: The attention mechanism used in Dinomaly is a linear attention, which is unable to focus on specific parts of the input. This property can be beneficial for anomaly detection, as the model is forced to learn a more holistic representation of the data.
-
Loose Reconstruction: The final component is a decoder that reconstructs the input, but without enforcing exact point-by-point or layer-to-layer reconstruction. This loose reconstruction objective allows the model to learn a more flexible representation of the data, which can be more effective for anomaly detection.
The authors conduct extensive experiments on three popular anomaly detection benchmarks: MVTec-AD, VisA, and Real-IAD. Dinomaly achieves impressive results, outperforming state-of-the-art multi-class anomaly detection methods as well as the most advanced class-separated models.
Critical Analysis
The paper presents a compelling approach to multi-class anomaly detection, but a few potential limitations are worth considering:
-
Generalization to Diverse Datasets: While Dinomaly achieves strong results on the benchmarks evaluated, it would be useful to see how well the framework generalizes to more diverse and challenging datasets, particularly those with long-tailed class distributions or a wider range of anomaly types. Additional research may be needed to fully understand the limits of Dinomaly's performance.
-
Interpretability and Explainability: As with many deep learning models, the inner workings of Dinomaly may be difficult to interpret. It could be valuable to explore techniques that provide more insight into how the model is making its anomaly detection decisions.
-
Computational Efficiency: While the authors emphasize the minimalistic nature of Dinomaly, the use of transformer architectures may still result in a relatively high computational burden, especially for deployment on resource-constrained devices. Further optimization or the exploration of more lightweight alternatives could be beneficial.
Overall, the Dinomaly framework represents a promising step forward in multi-class anomaly detection, and the authors' focus on simplicity and performance is commendable. As with any research, continued scrutiny and exploration of its strengths, weaknesses, and potential improvements will be crucial to advancing the field.
Conclusion
This paper introduces Dinomaly, a novel reconstruction-based anomaly detection framework that uses transformer architectures to achieve state-of-the-art performance on multi-class anomaly detection tasks. By incorporating four key components - Foundation Transformers, Noisy Bottleneck, Linear Attention, and Loose Reconstruction - Dinomaly is able to learn robust and flexible representations of data, surpassing the results of both multi-class and class-separated anomaly detection methods.
The authors' emphasis on simplicity and minimalism is particularly noteworthy, as Dinomaly demonstrates that complex designs and specialized tricks are not always necessary to push the boundaries of anomaly detection performance. This research represents an important step forward in the field, and the insights gained from Dinomaly's success could inform the development of future anomaly detection systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Absolute-Unified Multi-Class Anomaly Detection via Class-Agnostic Distribution Alignment
Jia Guo, Haonan Han, Shuai Lu, Weihang Zhang, Huiqi Li
0
0
Conventional unsupervised anomaly detection (UAD) methods build separate models for each object category. Recent studies have proposed to train a unified model for multiple classes, namely model-unified UAD. However, such methods still implement the unified model separately on each class during inference with respective anomaly decision thresholds, which hinders their application when the image categories are entirely unavailable. In this work, we present a simple yet powerful method to address multi-class anomaly detection without any class information, namely textit{absolute-unified} UAD. We target the crux of prior works in this challenging setting: different objects have mismatched anomaly score distributions. We propose Class-Agnostic Distribution Alignment (CADA) to align the mismatched score distribution of each implicit class without knowing class information, which enables unified anomaly detection for all classes and samples. The essence of CADA is to predict each class's score distribution of normal samples given any image, normal or anomalous, of this class. As a general component, CADA can activate the potential of nearly all UAD methods under absolute-unified setting. Our approach is extensively evaluated under the proposed setting on two popular UAD benchmark datasets, MVTec AD and VisA, where we exceed previous state-of-the-art by a large margin.
4/17/2024
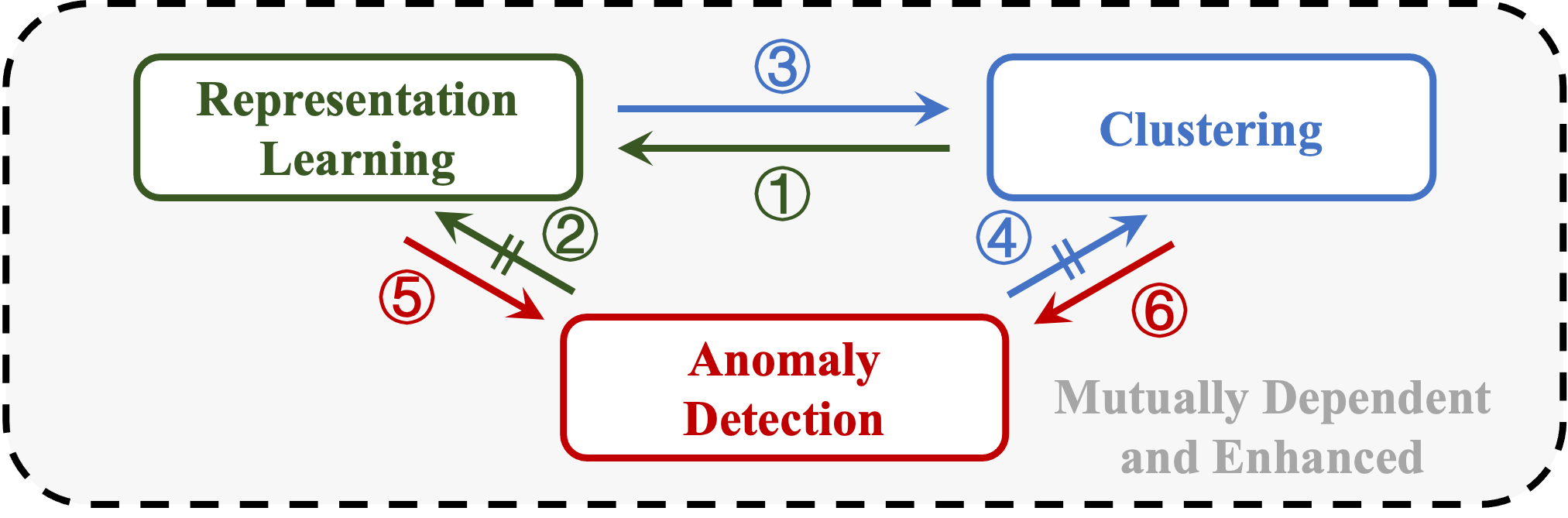
Towards a Unified Framework of Clustering-based Anomaly Detection
Zeyu Fang, Ming Gu, Sheng Zhou, Jiawei Chen, Qiaoyu Tan, Haishuai Wang, Jiajun Bu
0
0
Unsupervised Anomaly Detection (UAD) plays a crucial role in identifying abnormal patterns within data without labeled examples, holding significant practical implications across various domains. Although the individual contributions of representation learning and clustering to anomaly detection are well-established, their interdependencies remain under-explored due to the absence of a unified theoretical framework. Consequently, their collective potential to enhance anomaly detection performance remains largely untapped. To bridge this gap, in this paper, we propose a novel probabilistic mixture model for anomaly detection to establish a theoretical connection among representation learning, clustering, and anomaly detection. By maximizing a novel anomaly-aware data likelihood, representation learning and clustering can effectively reduce the adverse impact of anomalous data and collaboratively benefit anomaly detection. Meanwhile, a theoretically substantiated anomaly score is naturally derived from this framework. Lastly, drawing inspiration from gravitational analysis in physics, we have devised an improved anomaly score that more effectively harnesses the combined power of representation learning and clustering. Extensive experiments, involving 17 baseline methods across 30 diverse datasets, validate the effectiveness and generalization capability of the proposed method, surpassing state-of-the-art methods.
6/4/2024
❗
AnomalyDINO: Boosting Patch-based Few-shot Anomaly Detection with DINOv2
Simon Damm, Mike Laszkiewicz, Johannes Lederer, Asja Fischer
0
0
Recent advances in multimodal foundation models have set new standards in few-shot anomaly detection. This paper explores whether high-quality visual features alone are sufficient to rival existing state-of-the-art vision-language models. We affirm this by adapting DINOv2 for one-shot and few-shot anomaly detection, with a focus on industrial applications. We show that this approach does not only rival existing techniques but can even outmatch them in many settings. Our proposed vision-only approach, AnomalyDINO, is based on patch similarities and enables both image-level anomaly prediction and pixel-level anomaly segmentation. The approach is methodologically simple and training-free and, thus, does not require any additional data for fine-tuning or meta-learning. Despite its simplicity, AnomalyDINO achieves state-of-the-art results in one- and few-shot anomaly detection (e.g., pushing the one-shot performance on MVTec-AD from an AUROC of 93.1% to 96.6%). The reduced overhead, coupled with its outstanding few-shot performance, makes AnomalyDINO a strong candidate for fast deployment, for example, in industrial contexts.
5/24/2024

MiniMaxAD: A Lightweight Autoencoder for Feature-Rich Anomaly Detection
Fengjie Wang, Chengming Liu, Lei Shi, Pang Haibo
0
0
Previous unsupervised anomaly detection (UAD) methods often struggle with significant intra-class diversity; i.e., a class in a dataset contains multiple subclasses, which we categorize as Feature-Rich Anomaly Detection Datasets (FRADs). This challenge is evident in applications such as unified setting and unmanned supermarket scenarios. To address this challenge, we developed MiniMaxAD, a lightweight autoencoder designed to efficiently compress and memorize extensive information from normal images. Our model employs a technique that enhances feature diversity, thereby increasing the effective capacity limit of the network. It also utilizes large kernel convolution to extract highly abstract patterns, which contribute to efficient and compact feature embedding. Moreover, we introduce an Adaptive Contraction Loss (ADCLoss), specifically tailored to FRADs, to address the limitations of the global cosine distance loss. In our methodology, any dataset can be unified under the framework of feature-rich anomaly detection, in a way that the benefits far outweigh the drawbacks. MiniMaxAD underwent comprehensive testing across six challenging UAD benchmarks, achieving state-of-the-art results in four and highly competitive outcomes in the remaining two. Notably, our model not only achieved state-of-the-art performance in unmanned supermarket tasks but also exhibited an inference speed 37 times faster than the previous best method, demonstrating its effectiveness in complex UAD tasks.
5/24/2024