Long-Tailed Anomaly Detection with Learnable Class Names
2403.20236
0
0
❗
Abstract
Anomaly detection (AD) aims to identify defective images and localize their defects (if any). Ideally, AD models should be able to detect defects over many image classes; without relying on hard-coded class names that can be uninformative or inconsistent across datasets; learn without anomaly supervision; and be robust to the long-tailed distributions of real-world applications. To address these challenges, we formulate the problem of long-tailed AD by introducing several datasets with different levels of class imbalance and metrics for performance evaluation. We then propose a novel method, LTAD, to detect defects from multiple and long-tailed classes, without relying on dataset class names. LTAD combines AD by reconstruction and semantic AD modules. AD by reconstruction is implemented with a transformer-based reconstruction module. Semantic AD is implemented with a binary classifier, which relies on learned pseudo class names and a pretrained foundation model. These modules are learned over two phases. Phase 1 learns the pseudo-class names and a variational autoencoder (VAE) for feature synthesis that augments the training data to combat long-tails. Phase 2 then learns the parameters of the reconstruction and classification modules of LTAD. Extensive experiments using the proposed long-tailed datasets show that LTAD substantially outperforms the state-of-the-art methods for most forms of dataset imbalance. The long-tailed dataset split is available at https://zenodo.org/records/10854201 .
Create account to get full access
The paper addresses the problem of anomaly detection (AD) in images, particularly in scenarios with long-tailed class distributions, where some classes have significantly fewer examples than others. The authors introduce several datasets with varying levels of class imbalance and propose a novel method called LTAD (Long-Tailed Anomaly Detection) to detect and localize defects across multiple classes without relying on class names.
LTAD combines two modules: AD by reconstruction and semantic AD. The reconstruction module is implemented using a transformer-based architecture and is responsible for identifying anomalies based on reconstruction errors. The semantic AD module is a binary classifier that relies on learned pseudo-class names and a pre-trained foundation model.
The training process occurs in two phases. Phase 1 learns the pseudo-class names and a variational autoencoder (VAE) for feature synthesis, which augments the training data to combat long-tailed distributions. Phase 2 then trains the parameters of the reconstruction and classification modules of LTAD.
Extensive experiments on the proposed long-tailed datasets demonstrate that LTAD substantially outperforms state-of-the-art methods for most forms of dataset imbalance. The authors have made the long-tailed dataset split available at the provided Zenodo link.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Latent-based Diffusion Model for Long-tailed Recognition
Pengxiao Han, Changkun Ye, Jieming Zhou, Jing Zhang, Jie Hong, Xuesong Li
0
0
Long-tailed imbalance distribution is a common issue in practical computer vision applications. Previous works proposed methods to address this problem, which can be categorized into several classes: re-sampling, re-weighting, transfer learning, and feature augmentation. In recent years, diffusion models have shown an impressive generation ability in many sub-problems of deep computer vision. However, its powerful generation has not been explored in long-tailed problems. We propose a new approach, the Latent-based Diffusion Model for Long-tailed Recognition (LDMLR), as a feature augmentation method to tackle the issue. First, we encode the imbalanced dataset into features using the baseline model. Then, we train a Denoising Diffusion Implicit Model (DDIM) using these encoded features to generate pseudo-features. Finally, we train the classifier using the encoded and pseudo-features from the previous two steps. The model's accuracy shows an improvement on the CIFAR-LT and ImageNet-LT datasets by using the proposed method.
4/24/2024

Self-Supervised Time-Series Anomaly Detection Using Learnable Data Augmentation
Kukjin Choi, Jihun Yi, Jisoo Mok, Sungroh Yoon
0
0
Continuous efforts are being made to advance anomaly detection in various manufacturing processes to increase the productivity and safety of industrial sites. Deep learning replaced rule-based methods and recently emerged as a promising method for anomaly detection in diverse industries. However, in the real world, the scarcity of abnormal data and difficulties in obtaining labeled data create limitations in the training of detection models. In this study, we addressed these shortcomings by proposing a learnable data augmentation-based time-series anomaly detection (LATAD) technique that is trained in a self-supervised manner. LATAD extracts discriminative features from time-series data through contrastive learning. At the same time, learnable data augmentation produces challenging negative samples to enhance learning efficiency. We measured anomaly scores of the proposed technique based on latent feature similarities. As per the results, LATAD exhibited comparable or improved performance to the state-of-the-art anomaly detection assessments on several benchmark datasets and provided a gradient-based diagnosis technique to help identify root causes.
6/28/2024
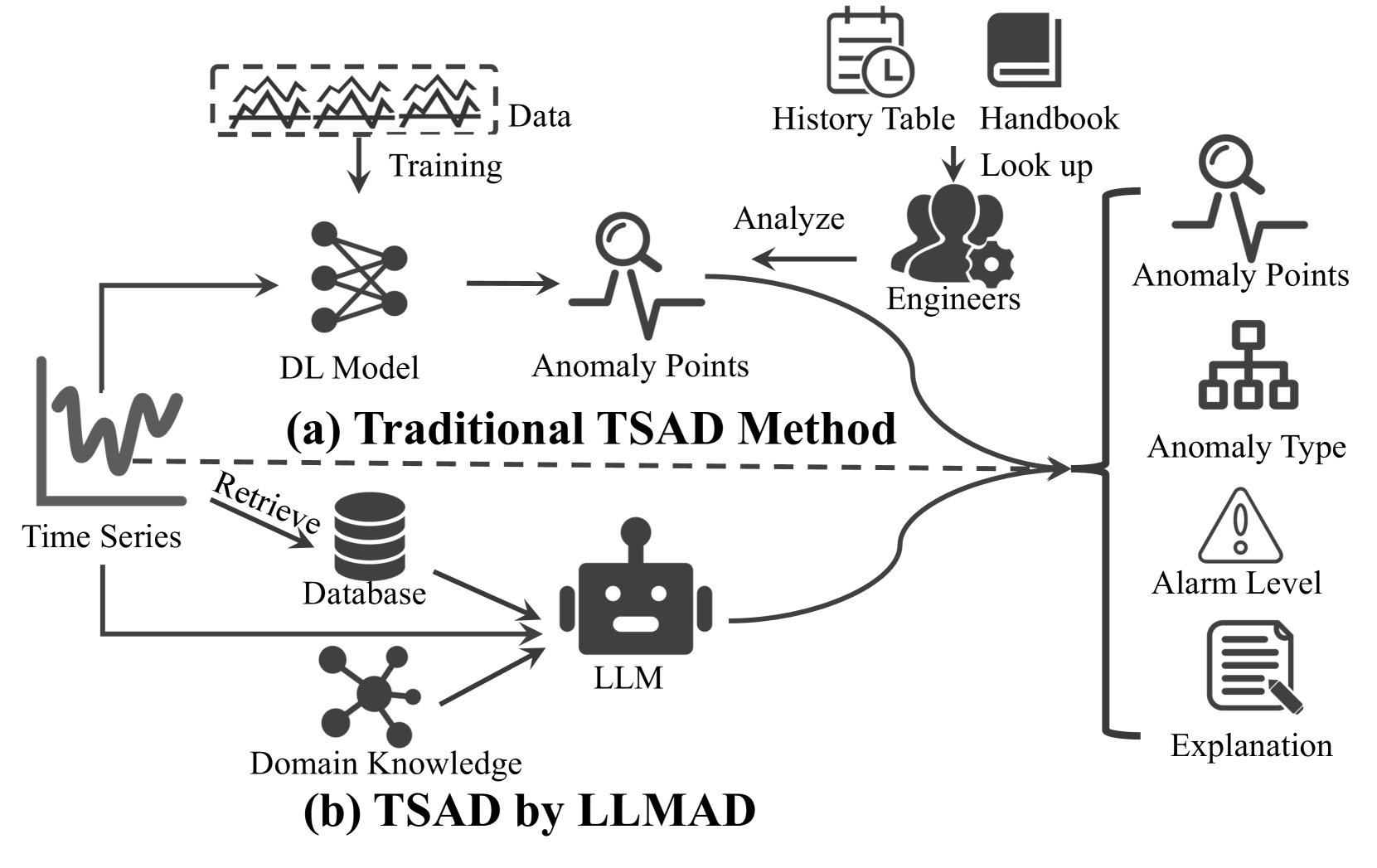
Large Language Models can Deliver Accurate and Interpretable Time Series Anomaly Detection
Jun Liu, Chaoyun Zhang, Jiaxu Qian, Minghua Ma, Si Qin, Chetan Bansal, Qingwei Lin, Saravan Rajmohan, Dongmei Zhang
0
0
Time series anomaly detection (TSAD) plays a crucial role in various industries by identifying atypical patterns that deviate from standard trends, thereby maintaining system integrity and enabling prompt response measures. Traditional TSAD models, which often rely on deep learning, require extensive training data and operate as black boxes, lacking interpretability for detected anomalies. To address these challenges, we propose LLMAD, a novel TSAD method that employs Large Language Models (LLMs) to deliver accurate and interpretable TSAD results. LLMAD innovatively applies LLMs for in-context anomaly detection by retrieving both positive and negative similar time series segments, significantly enhancing LLMs' effectiveness. Furthermore, LLMAD employs the Anomaly Detection Chain-of-Thought (AnoCoT) approach to mimic expert logic for its decision-making process. This method further enhances its performance and enables LLMAD to provide explanations for their detections through versatile perspectives, which are particularly important for user decision-making. Experiments on three datasets indicate that our LLMAD achieves detection performance comparable to state-of-the-art deep learning methods while offering remarkable interpretability for detections. To the best of our knowledge, this is the first work that directly employs LLMs for TSAD.
5/27/2024
🤷
Dinomaly: The Less Is More Philosophy in Multi-Class Unsupervised Anomaly Detection
Jia Guo, Shuai Lu, Weihang Zhang, Huiqi Li
0
0
Recent studies highlighted a practical setting of unsupervised anomaly detection (UAD) that builds a unified model for multi-class images, serving as an alternative to the conventional one-class-one-model setup. Despite various advancements addressing this challenging task, the detection performance under the multi-class setting still lags far behind state-of-the-art class-separated models. Our research aims to bridge this substantial performance gap. In this paper, we introduce a minimalistic reconstruction-based anomaly detection framework, namely Dinomaly, which leverages pure Transformer architectures without relying on complex designs, additional modules, or specialized tricks. Given this powerful framework consisted of only Attentions and MLPs, we found four simple components that are essential to multi-class anomaly detection: (1) Foundation Transformers that extracts universal and discriminative features, (2) Noisy Bottleneck where pre-existing Dropouts do all the noise injection tricks, (3) Linear Attention that naturally cannot focus, and (4) Loose Reconstruction that does not force layer-to-layer and point-by-point reconstruction. Extensive experiments are conducted across three popular anomaly detection benchmarks including MVTec-AD, VisA, and the recently released Real-IAD. Our proposed Dinomaly achieves impressive image AUROC of 99.6%, 98.7%, and 89.3% on the three datasets respectively, which is not only superior to state-of-the-art multi-class UAD methods, but also surpasses the most advanced class-separated UAD records.
5/30/2024