Direct Preference Knowledge Distillation for Large Language Models
2406.19774
0
0
Abstract
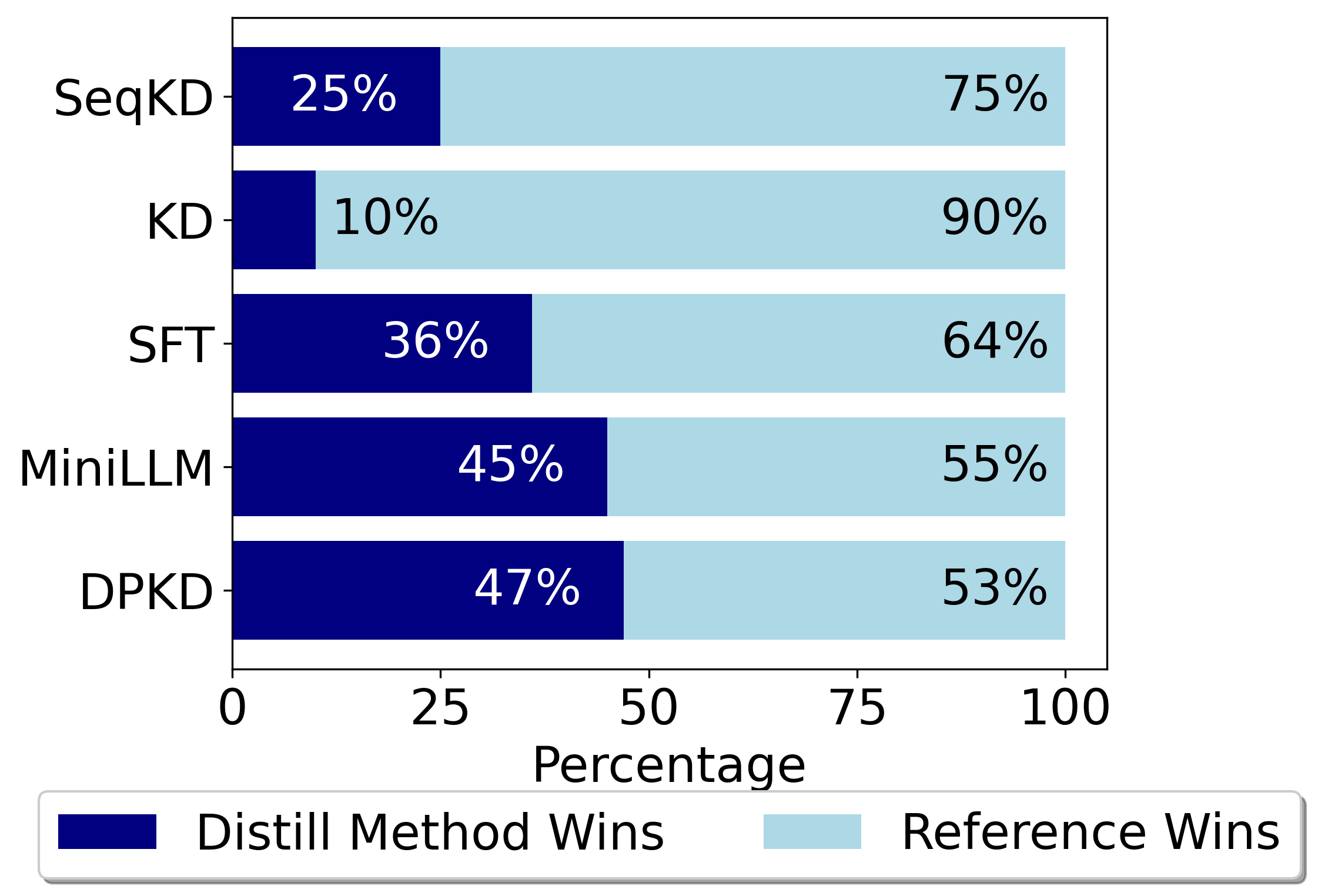
In the field of large language models (LLMs), Knowledge Distillation (KD) is a critical technique for transferring capabilities from teacher models to student models. However, existing KD methods face limitations and challenges in distillation of LLMs, including efficiency and insufficient measurement capabilities of traditional KL divergence. It is shown that LLMs can serve as an implicit reward function, which we define as a supplement to KL divergence. In this work, we propose Direct Preference Knowledge Distillation (DPKD) for LLMs. DPKD utilizes distribution divergence to represent the preference loss and implicit reward function. We re-formulate KD of LLMs into two stages: first optimizing and objective consisting of implicit reward and reverse KL divergence and then improving the preference probability of teacher outputs over student outputs. We conducted experiments and analysis on various datasets with LLM parameters ranging from 120M to 13B and demonstrate the broad applicability and effectiveness of our DPKD approach. Meanwhile, we prove the value and effectiveness of the introduced implicit reward and output preference in KD through experiments and theoretical analysis. The DPKD method outperforms the baseline method in both output response precision and exact match percentage. Code and data are available at https://aka.ms/dpkd.
Create account to get full access
Overview
- This paper introduces a new approach called "Direct Preference Knowledge Distillation" for training smaller language models by learning from the preferences of a larger, more capable model.
- The key idea is to have the larger model provide direct preference feedback, rather than just mimicking its output probabilities, which can lead to better performance for the smaller student model.
- The authors demonstrate the effectiveness of this approach on several language tasks, showing that the student model can outperform previous knowledge distillation methods.
Plain English Explanation
The paper describes a new way to train smaller language models by having them learn from the preferences of a larger, more capable model. Instead of just copying the output probabilities of the larger model, the smaller model is trained to directly match the preferences or rankings that the larger model has for different options.
The key insight is that directly learning the preferences of the larger model can lead to better performance for the smaller model, compared to just trying to mimic the output probabilities. The authors show that this "direct preference knowledge distillation" approach works better than previous knowledge distillation methods on a variety of language tasks.
This is important because it provides a way to create smaller, more efficient language models that can still benefit from the knowledge and capabilities of larger, more powerful models. This could be useful for deploying language AI systems on low-power devices or in situations where computational resources are limited.
Technical Explanation
The paper introduces a new knowledge distillation technique called "Direct Preference Knowledge Distillation" (DPKD) for training smaller language models. In traditional knowledge distillation, the student model is trained to mimic the output probabilities of the larger teacher model.
Instead, DPKD trains the student to directly match the preference rankings that the teacher model has over different output options. The authors propose two variants of this approach:
- Pairwise DPKD: The student is trained to correctly predict whether the teacher prefers one output over another.
- Listwise DPKD: The student is trained to predict the full ranking of a set of outputs according to the teacher's preferences.
The authors evaluate these DPKD approaches on a variety of language tasks, including text generation, question answering, and dialogue response ranking. They show that the student models trained with DPKD can outperform those trained with standard knowledge distillation techniques, as well as other baseline methods.
The intuition is that directly learning the teacher's preferences can provide richer supervisory signals for the student model, rather than just trying to copy the output probabilities. This allows the student to better capture the underlying knowledge and decision-making process of the larger teacher model.
Critical Analysis
The paper presents a compelling approach to knowledge distillation for language models, but there are a few potential caveats and areas for further research:
- The experiments are primarily focused on ranking and generation tasks, so it's unclear how well the DPKD method would translate to other language understanding tasks like classification or sequence labeling.
- The paper does not provide a detailed analysis of the computational and memory overhead of the DPKD approach compared to standard knowledge distillation. This could be an important practical consideration, especially for deploying smaller models on resource-constrained devices.
- The authors mention that the DPKD method relies on the teacher model producing reliable preference rankings, but they don't explore how sensitive the approach is to potential biases or errors in the teacher's preferences. Further research could investigate the robustness of DPKD to imperfect teacher models.
Overall, the Direct Preference Knowledge Distillation approach seems promising and could be a valuable tool for knowledge distillation in large language models. However, additional research is needed to fully understand its limitations and potential applications.
Conclusion
This paper introduces a novel knowledge distillation technique called "Direct Preference Knowledge Distillation" that trains smaller language models to directly match the preference rankings of a larger, more capable teacher model. The authors show that this approach can outperform standard knowledge distillation methods on a variety of language tasks.
The key idea of DPKD is that learning the teacher's preferences can provide richer supervisory signals for the student model, compared to simply mimicking the teacher's output probabilities. This could be a valuable tool for creating smaller, more efficient language models that can still leverage the knowledge and capabilities of larger models.
While the paper demonstrates the effectiveness of DPKD, there are still some open questions and potential areas for further research, such as how it performs on different language tasks and its computational overhead. Overall, this work represents an interesting and promising advancement in the field of knowledge distillation for large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MiniLLM: Knowledge Distillation of Large Language Models
Yuxian Gu, Li Dong, Furu Wei, Minlie Huang
0
0
Knowledge Distillation (KD) is a promising technique for reducing the high computational demand of large language models (LLMs). However, previous KD methods are primarily applied to white-box classification models or training small models to imitate black-box model APIs like ChatGPT. How to effectively distill the knowledge of white-box LLMs into small models is still under-explored, which becomes more important with the prosperity of open-source LLMs. In this work, we propose a KD approach that distills LLMs into smaller language models. We first replace the forward Kullback-Leibler divergence (KLD) objective in the standard KD approaches with reverse KLD, which is more suitable for KD on generative language models, to prevent the student model from overestimating the low-probability regions of the teacher distribution. Then, we derive an effective optimization approach to learn this objective. The student models are named MiniLLM. Extensive experiments in the instruction-following setting show that MiniLLM generates more precise responses with higher overall quality, lower exposure bias, better calibration, and higher long-text generation performance than the baselines. Our method is scalable for different model families with 120M to 13B parameters. Our code, data, and model checkpoints can be found in https://github.com/microsoft/LMOps/tree/main/minillm.
4/11/2024

PLaD: Preference-based Large Language Model Distillation with Pseudo-Preference Pairs
Rongzhi Zhang, Jiaming Shen, Tianqi Liu, Haorui Wang, Zhen Qin, Feng Han, Jialu Liu, Simon Baumgartner, Michael Bendersky, Chao Zhang
0
0
Large Language Models (LLMs) have exhibited impressive capabilities in various tasks, yet their vast parameter sizes restrict their applicability in resource-constrained settings. Knowledge distillation (KD) offers a viable solution by transferring expertise from large teacher models to compact student models. However, traditional KD techniques face specific challenges when applied to LLMs, including restricted access to LLM outputs, significant teacher-student capacity gaps, and the inherited mis-calibration issue. In this work, we present PLaD, a novel preference-based LLM distillation framework. PLaD exploits the teacher-student capacity discrepancy to generate pseudo-preference pairs where teacher outputs are preferred over student outputs. Then, PLaD leverages a ranking loss to re-calibrate student's estimation of sequence likelihood, which steers the student's focus towards understanding the relative quality of outputs instead of simply imitating the teacher. PLaD bypasses the need for access to teacher LLM's internal states, tackles the student's expressivity limitations, and mitigates the student mis-calibration issue. Through extensive experiments on two sequence generation tasks and with various LLMs, we demonstrate the effectiveness of our proposed PLaD framework.
6/7/2024

New!DistiLLM: Towards Streamlined Distillation for Large Language Models
Jongwoo Ko, Sungnyun Kim, Tianyi Chen, Se-Young Yun
0
0
Knowledge distillation (KD) is widely used for compressing a teacher model to a smaller student model, reducing its inference cost and memory footprint while preserving model capabilities. However, current KD methods for auto-regressive sequence models (e.g., large language models) suffer from missing a standardized objective function. Moreover, the recent use of student-generated outputs to address training-inference mismatches has significantly escalated computational costs. To tackle these issues, we introduce DistiLLM, a more effective and efficient KD framework for auto-regressive language models. DistiLLM comprises two components: (1) a novel skew Kullback-Leibler divergence loss, where we unveil and leverage its theoretical properties, and (2) an adaptive off-policy approach designed to enhance the efficiency in utilizing student-generated outputs. Extensive experiments, including instruction-following tasks, demonstrate the effectiveness of DistiLLM in building high-performing student models while achieving up to 4.3$times$ speedup compared to recent KD methods.
7/4/2024

Knowledge Distillation of LLM for Automatic Scoring of Science Education Assessments
Ehsan Latif, Luyang Fang, Ping Ma, Xiaoming Zhai
0
0
This study proposes a method for knowledge distillation (KD) of fine-tuned Large Language Models (LLMs) into smaller, more efficient, and accurate neural networks. We specifically target the challenge of deploying these models on resource-constrained devices. Our methodology involves training the smaller student model (Neural Network) using the prediction probabilities (as soft labels) of the LLM, which serves as a teacher model. This is achieved through a specialized loss function tailored to learn from the LLM's output probabilities, ensuring that the student model closely mimics the teacher's performance. To validate the performance of the KD approach, we utilized a large dataset, 7T, containing 6,684 student-written responses to science questions and three mathematical reasoning datasets with student-written responses graded by human experts. We compared accuracy with state-of-the-art (SOTA) distilled models, TinyBERT, and artificial neural network (ANN) models. Results have shown that the KD approach has 3% and 2% higher scoring accuracy than ANN and TinyBERT, respectively, and comparable accuracy to the teacher model. Furthermore, the student model size is 0.03M, 4,000 times smaller in parameters and x10 faster in inferencing than the teacher model and TinyBERT, respectively. The significance of this research lies in its potential to make advanced AI technologies accessible in typical educational settings, particularly for automatic scoring.
6/13/2024