PLaD: Preference-based Large Language Model Distillation with Pseudo-Preference Pairs

0

Sign in to get full access
Overview
- This research paper proposes a new method called PLaD (Preference-based Large Language Model Distillation) for distilling a large language model into a smaller one while preserving its performance.
- PLaD uses a technique called "pseudo-preference pairs" to guide the distillation process, which helps the smaller model learn the preferences of the larger model.
- The authors show that PLaD can outperform other distillation methods, particularly on tasks where the larger model exhibits strong preferences, such as natural language generation.
Plain English Explanation
In the world of artificial intelligence (AI), large language models like GPT-3 have shown remarkable capabilities in tasks like language generation and understanding. However, these models are often very large and complex, making them difficult to deploy on resource-constrained devices like smartphones or embedded systems.
Distillation is a technique used to compress a large language model into a smaller, more efficient model while trying to preserve its performance. The authors of this paper propose a new distillation method called PLaD, which uses a novel approach called "pseudo-preference pairs" to guide the distillation process.
The key idea behind PLaD is to not only transfer the knowledge from the large model to the small model, but also to capture the preferences of the large model. For example, the large model may have a strong preference for generating certain types of text over others. By preserving these preferences, the small model can better mimic the behavior of the large model, particularly in tasks like natural language generation.
The authors show that PLaD outperforms other distillation methods, especially on tasks where the large model exhibits strong preferences. This suggests that capturing these preferences is an important aspect of distilling large language models effectively.
Technical Explanation
The authors propose a new distillation method called PLaD (Preference-based Large Language Model Distillation) that aims to capture the preferences of a large language model and transfer them to a smaller model during the distillation process.
The key innovation of PLaD is the use of pseudo-preference pairs, which are generated by the large language model and used to train the smaller model. These pseudo-preference pairs consist of a pair of text sequences, where one is preferred over the other by the large model.
The authors show that by optimizing the smaller model to match the preferences of the larger model, as expressed through the pseudo-preference pairs, the distillation process can better preserve the performance of the large model, particularly on tasks like natural language generation where preferences play a crucial role.
The authors evaluate PLaD on several benchmarks and compare it to other distillation methods, such as adversarial moment matching and differentially private knowledge distillation. Their results show that PLaD outperforms these other methods, especially on tasks where the large model exhibits strong preferences.
Critical Analysis
The authors have presented a novel and promising approach to distilling large language models while preserving their performance. The idea of capturing the preferences of the large model through pseudo-preference pairs is an interesting and potentially valuable contribution to the field of knowledge distillation.
However, the authors do not provide a detailed analysis of the limitations or potential issues with their approach. For example, it would be helpful to understand how the generation of the pseudo-preference pairs can be scaled to larger models, and how sensitive the performance of PLaD is to the quality and diversity of the generated pairs.
Additionally, the authors could have explored the potential trade-offs between the performance gains achieved by PLaD and the computational overhead or additional data requirements introduced by the pseudo-preference pair generation process.
Overall, the research presents a compelling approach to language model distillation, but further investigation into the method's robustness, scalability, and potential drawbacks would be valuable for the research community to fully evaluate its merits.
Conclusion
The PLaD method proposed in this research paper represents an interesting and promising approach to distilling large language models while preserving their performance, particularly on tasks where the preferences of the larger model play a significant role.
By capturing these preferences through the use of pseudo-preference pairs, the authors have shown that the smaller distilled model can better mimic the behavior of the larger model, leading to improved performance on tasks like natural language generation.
While the research presents a valuable contribution to the field of knowledge distillation, further investigation into the method's limitations and potential trade-offs would be beneficial to fully assess its impact and applicability in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PLaD: Preference-based Large Language Model Distillation with Pseudo-Preference Pairs
Rongzhi Zhang, Jiaming Shen, Tianqi Liu, Haorui Wang, Zhen Qin, Feng Han, Jialu Liu, Simon Baumgartner, Michael Bendersky, Chao Zhang
Large Language Models (LLMs) have exhibited impressive capabilities in various tasks, yet their vast parameter sizes restrict their applicability in resource-constrained settings. Knowledge distillation (KD) offers a viable solution by transferring expertise from large teacher models to compact student models. However, traditional KD techniques face specific challenges when applied to LLMs, including restricted access to LLM outputs, significant teacher-student capacity gaps, and the inherited mis-calibration issue. In this work, we present PLaD, a novel preference-based LLM distillation framework. PLaD exploits the teacher-student capacity discrepancy to generate pseudo-preference pairs where teacher outputs are preferred over student outputs. Then, PLaD leverages a ranking loss to re-calibrate student's estimation of sequence likelihood, which steers the student's focus towards understanding the relative quality of outputs instead of simply imitating the teacher. PLaD bypasses the need for access to teacher LLM's internal states, tackles the student's expressivity limitations, and mitigates the student mis-calibration issue. Through extensive experiments on two sequence generation tasks and with various LLMs, we demonstrate the effectiveness of our proposed PLaD framework.
Read more6/7/2024
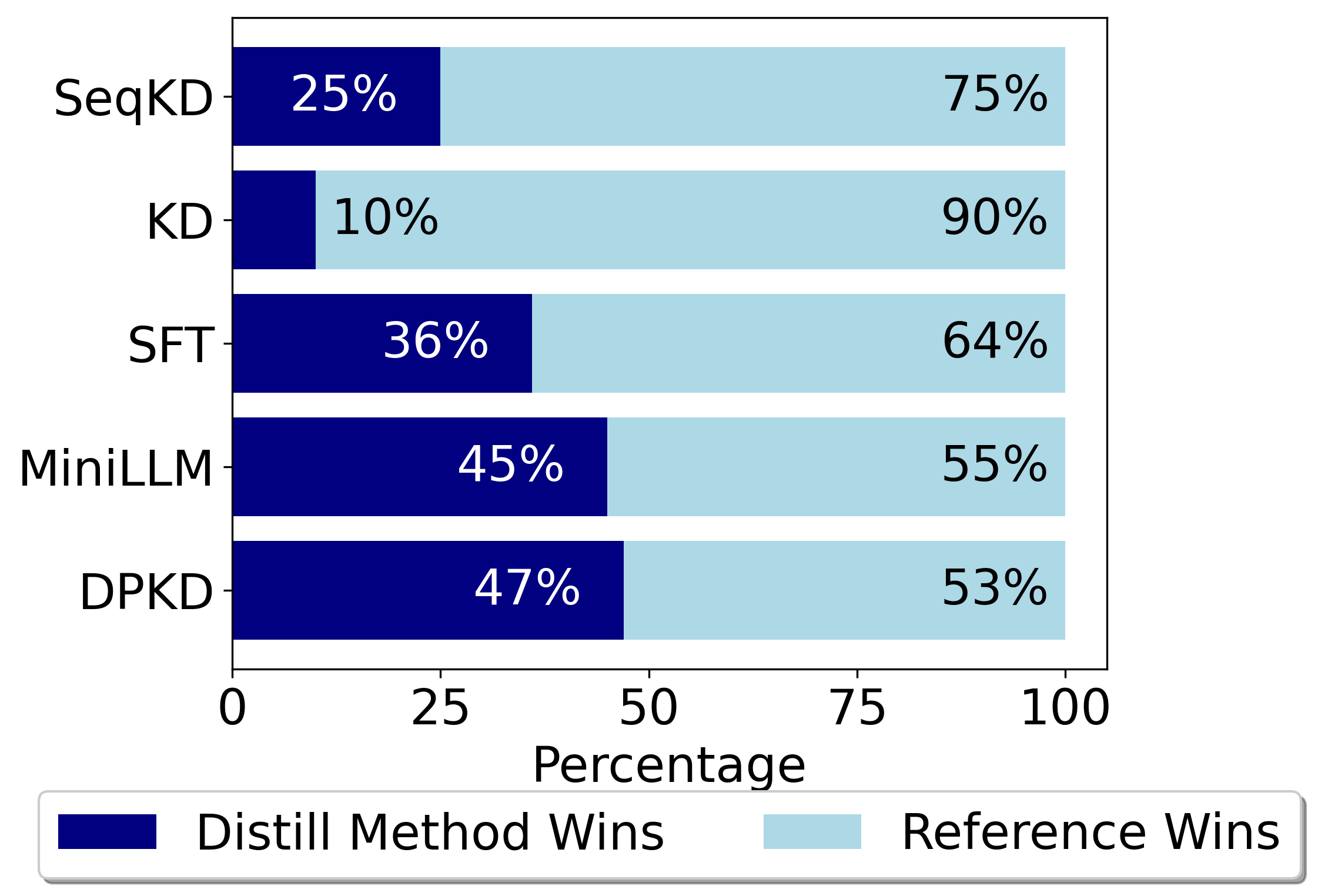
0
Direct Preference Knowledge Distillation for Large Language Models
Yixing Li, Yuxian Gu, Li Dong, Dequan Wang, Yu Cheng, Furu Wei
In the field of large language models (LLMs), Knowledge Distillation (KD) is a critical technique for transferring capabilities from teacher models to student models. However, existing KD methods face limitations and challenges in distillation of LLMs, including efficiency and insufficient measurement capabilities of traditional KL divergence. It is shown that LLMs can serve as an implicit reward function, which we define as a supplement to KL divergence. In this work, we propose Direct Preference Knowledge Distillation (DPKD) for LLMs. DPKD utilizes distribution divergence to represent the preference loss and implicit reward function. We re-formulate KD of LLMs into two stages: first optimizing and objective consisting of implicit reward and reverse KL divergence and then improving the preference probability of teacher outputs over student outputs. We conducted experiments and analysis on various datasets with LLM parameters ranging from 120M to 13B and demonstrate the broad applicability and effectiveness of our DPKD approach. Meanwhile, we prove the value and effectiveness of the introduced implicit reward and output preference in KD through experiments and theoretical analysis. The DPKD method outperforms the baseline method in both output response precision and exact match percentage. Code and data are available at https://aka.ms/dpkd.
Read more7/1/2024

0
Enhancing Knowledge Distillation of Large Language Models through Efficient Multi-Modal Distribution Alignment
Tianyu Peng, Jiajun Zhang
Knowledge distillation (KD) is an effective model compression method that can transfer the internal capabilities of large language models (LLMs) to smaller ones. However, the multi-modal probability distribution predicted by teacher LLMs causes difficulties for student models to learn. In this paper, we first demonstrate the importance of multi-modal distribution alignment with experiments and then highlight the inefficiency of existing KD approaches in learning multi-modal distributions. To address this problem, we propose Ranking Loss based Knowledge Distillation (RLKD), which encourages the consistency of the ranking of peak predictions between the teacher and student models. By incorporating word-level ranking loss, we ensure excellent compatibility with existing distillation objectives while fully leveraging the fine-grained information between different categories in peaks of two predicted distribution. Experimental results demonstrate that our method enables the student model to better learn the multi-modal distributions of the teacher model, leading to a significant performance improvement in various downstream tasks.
Read more9/20/2024

0
DistiLLM: Towards Streamlined Distillation for Large Language Models
Jongwoo Ko, Sungnyun Kim, Tianyi Chen, Se-Young Yun
Knowledge distillation (KD) is widely used for compressing a teacher model to a smaller student model, reducing its inference cost and memory footprint while preserving model capabilities. However, current KD methods for auto-regressive sequence models (e.g., large language models) suffer from missing a standardized objective function. Moreover, the recent use of student-generated outputs to address training-inference mismatches has significantly escalated computational costs. To tackle these issues, we introduce DistiLLM, a more effective and efficient KD framework for auto-regressive language models. DistiLLM comprises two components: (1) a novel skew Kullback-Leibler divergence loss, where we unveil and leverage its theoretical properties, and (2) an adaptive off-policy approach designed to enhance the efficiency in utilizing student-generated outputs. Extensive experiments, including instruction-following tasks, demonstrate the effectiveness of DistiLLM in building high-performing student models while achieving up to 4.3$times$ speedup compared to recent KD methods.
Read more7/4/2024