Discovering Interpretable Directions in the Semantic Latent Space of Diffusion Models
2303.11073
0
0
🔄
Abstract
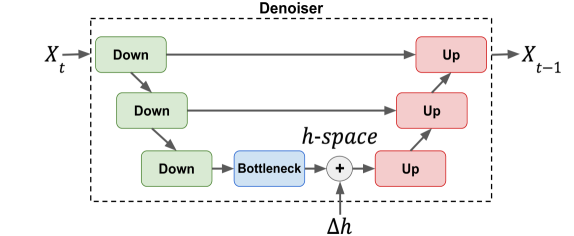
Denoising Diffusion Models (DDMs) have emerged as a strong competitor to Generative Adversarial Networks (GANs). However, despite their widespread use in image synthesis and editing applications, their latent space is still not as well understood. Recently, a semantic latent space for DDMs, coined `$h$-space', was shown to facilitate semantic image editing in a way reminiscent of GANs. The $h$-space is comprised of the bottleneck activations in the DDM's denoiser across all timesteps of the diffusion process. In this paper, we explore the properties of h-space and propose several novel methods for finding meaningful semantic directions within it. We start by studying unsupervised methods for revealing interpretable semantic directions in pretrained DDMs. Specifically, we show that global latent directions emerge as the principal components in the latent space. Additionally, we provide a novel method for discovering image-specific semantic directions by spectral analysis of the Jacobian of the denoiser w.r.t. the latent code. Next, we extend the analysis by finding directions in a supervised fashion in unconditional DDMs. We demonstrate how such directions can be found by relying on either a labeled data set of real images or by annotating generated samples with a domain-specific attribute classifier. We further show how to semantically disentangle the found direction by simple linear projection. Our approaches are applicable without requiring any architectural modifications, text-based guidance, CLIP-based optimization, or model fine-tuning.
Create account to get full access
Overview
- Denoising Diffusion Models (DDMs) have emerged as a strong alternative to Generative Adversarial Networks (GANs) for image synthesis and editing
- However, the latent space of DDMs is not as well understood as GANs
- Recently, a new latent space called "h-space" was discovered in DDMs, which facilitates semantic image editing similar to GANs
- This paper explores the properties of h-space and proposes methods for finding meaningful semantic directions within it
Plain English Explanation
Denoising Diffusion Models (DDMs) are a type of machine learning model that can generate and edit images. They work by gradually adding "noise" to an image and then learning how to remove that noise, gradually revealing the desired image. DDMs as a strong competitor to GANs
Unlike Generative Adversarial Networks (GANs), which are another type of image generation model, the inner workings of DDMs are not as well understood. Recently, researchers discovered a new latent space within DDMs called "h-space" that seems to capture semantic information about the images, similar to how GANs work. h-space and semantic image editing
This paper explores the properties of this h-space and proposes several new techniques for finding meaningful directions or dimensions within it. These directions could then be used to edit images in semantically meaningful ways, like changing the expression on a face or the color of an object. Finding semantic directions in h-space
The key ideas are to use unsupervised methods to find general semantic directions, as well as supervised methods that use labeled data or classifiers to find more specific semantic directions. The researchers show that these techniques can be applied to DDMs without requiring any changes to the model architecture or additional training. Supervised and unsupervised methods for finding semantic directions
Technical Explanation
The paper starts by studying unsupervised methods for revealing interpretable semantic directions in pretrained DDMs. The researchers show that global latent directions emerge as the principal components in the latent space. They also provide a novel method for discovering image-specific semantic directions by analyzing the Jacobian of the denoiser (a key component of the DDM) with respect to the latent code.
Next, the paper extends the analysis to finding semantic directions in a supervised fashion, even for unconditional DDMs (DDMs that are not conditioned on any additional input). The researchers demonstrate how such directions can be found by relying on either a labeled dataset of real images or by annotating generated samples with a domain-specific attribute classifier. They further show how to semantically disentangle the found directions through simple linear projection.
Importantly, the proposed approaches do not require any architectural modifications, text-based guidance, CLIP-based optimization, or model fine-tuning. This makes them widely applicable to various DDM-based systems.
Critical Analysis
The paper provides a thorough and insightful analysis of the latent space of Denoising Diffusion Models, an area that has not been as well-studied as the latent spaces of Generative Adversarial Networks. The researchers' discovery of the "h-space" and their methods for finding meaningful semantic directions within it are a valuable contribution to the field.
One potential limitation is that the paper does not extensively explore the practical applications and real-world implications of their findings. While they demonstrate the ability to edit images in semantically meaningful ways, the paper does not delve into the potential use cases or the broader impact of this technology.
Additionally, the paper does not address potential biases or ethical concerns that may arise from the use of these techniques. As with any generative modeling system, there is a risk of amplifying or perpetuating harmful stereotypes or biases present in the training data. Considerations around bias and ethics in generative models
Overall, this paper makes a strong contribution to our understanding of Denoising Diffusion Models and opens up new avenues for further research and development in this area.
Conclusion
This paper presents a significant step forward in understanding the latent space of Denoising Diffusion Models, a powerful class of generative models. By introducing the concept of "h-space" and proposing methods for finding meaningful semantic directions within it, the researchers have laid the groundwork for more interpretable and controllable image synthesis and editing using DDMs.
The findings in this paper could have important implications for a wide range of applications, from creative tools for artists and designers to AI-powered image manipulation for various industries. As the field of generative modeling continues to evolve, research like this will be crucial in unlocking the full potential of these technologies while addressing important ethical considerations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
On the Semantic Latent Space of Diffusion-Based Text-to-Speech Models
Miri Varshavsky-Hassid, Roy Hirsch, Regev Cohen, Tomer Golany, Daniel Freedman, Ehud Rivlin
0
0
The incorporation of Denoising Diffusion Models (DDMs) in the Text-to-Speech (TTS) domain is rising, providing great value in synthesizing high quality speech. Although they exhibit impressive audio quality, the extent of their semantic capabilities is unknown, and controlling their synthesized speech's vocal properties remains a challenge. Inspired by recent advances in image synthesis, we explore the latent space of frozen TTS models, which is composed of the latent bottleneck activations of the DDM's denoiser. We identify that this space contains rich semantic information, and outline several novel methods for finding semantic directions within it, both supervised and unsupervised. We then demonstrate how these enable off-the-shelf audio editing, without any further training, architectural changes or data requirements. We present evidence of the semantic and acoustic qualities of the edited audio, and provide supplemental samples: https://latent-analysis-grad-tts.github.io/speech-samples/.
6/5/2024
🤿
Do Diffusion Models Learn Semantically Meaningful and Efficient Representations?
Qiyao Liang, Ziming Liu, Ila Fiete
0
0
Diffusion models are capable of impressive feats of image generation with uncommon juxtapositions such as astronauts riding horses on the moon with properly placed shadows. These outputs indicate the ability to perform compositional generalization, but how do the models do so? We perform controlled experiments on conditional DDPMs learning to generate 2D spherical Gaussian bumps centered at specified $x$- and $y$-positions. Our results show that the emergence of semantically meaningful latent representations is key to achieving high performance. En route to successful performance over learning, the model traverses three distinct phases of latent representations: (phase A) no latent structure, (phase B) a 2D manifold of disordered states, and (phase C) a 2D ordered manifold. Corresponding to each of these phases, we identify qualitatively different generation behaviors: 1) multiple bumps are generated, 2) one bump is generated but at inaccurate $x$ and $y$ locations, 3) a bump is generated at the correct $x$ and y location. Furthermore, we show that even under imbalanced datasets where features ($x$- versus $y$-positions) are represented with skewed frequencies, the learning process for $x$ and $y$ is coupled rather than factorized, demonstrating that simple vanilla-flavored diffusion models cannot learn efficient representations in which localization in $x$ and $y$ are factorized into separate 1D tasks. These findings suggest the need for future work to find inductive biases that will push generative models to discover and exploit factorizable independent structures in their inputs, which will be required to vault these models into more data-efficient regimes.
5/1/2024

Global Counterfactual Directions
Bartlomiej Sobieski, Przemys{l}aw Biecek
0
0
Despite increasing progress in development of methods for generating visual counterfactual explanations, especially with the recent rise of Denoising Diffusion Probabilistic Models, previous works consider them as an entirely local technique. In this work, we take the first step at globalizing them. Specifically, we discover that the latent space of Diffusion Autoencoders encodes the inference process of a given classifier in the form of global directions. We propose a novel proxy-based approach that discovers two types of these directions with the use of only single image in an entirely black-box manner. Precisely, g-directions allow for flipping the decision of a given classifier on an entire dataset of images, while h-directions further increase the diversity of explanations. We refer to them in general as Global Counterfactual Directions (GCDs). Moreover, we show that GCDs can be naturally combined with Latent Integrated Gradients resulting in a new black-box attribution method, while simultaneously enhancing the understanding of counterfactual explanations. We validate our approach on existing benchmarks and show that it generalizes to real-world use-cases.
4/22/2024
⛏️
An Edit Friendly DDPM Noise Space: Inversion and Manipulations
Inbar Huberman-Spiegelglas, Vladimir Kulikov, Tomer Michaeli
0
0
Denoising diffusion probabilistic models (DDPMs) employ a sequence of white Gaussian noise samples to generate an image. In analogy with GANs, those noise maps could be considered as the latent code associated with the generated image. However, this native noise space does not possess a convenient structure, and is thus challenging to work with in editing tasks. Here, we propose an alternative latent noise space for DDPM that enables a wide range of editing operations via simple means, and present an inversion method for extracting these edit-friendly noise maps for any given image (real or synthetically generated). As opposed to the native DDPM noise space, the edit-friendly noise maps do not have a standard normal distribution and are not statistically independent across timesteps. However, they allow perfect reconstruction of any desired image, and simple transformations on them translate into meaningful manipulations of the output image (e.g. shifting, color edits). Moreover, in text-conditional models, fixing those noise maps while changing the text prompt, modifies semantics while retaining structure. We illustrate how this property enables text-based editing of real images via the diverse DDPM sampling scheme (in contrast to the popular non-diverse DDIM inversion). We also show how it can be used within existing diffusion-based editing methods to improve their quality and diversity. Webpage: https://inbarhub.github.io/DDPM_inversion
4/10/2024