A Distributed Approach for Persistent Homology Computation on a Large Scale

0

Sign in to get full access
Overview
- This paper presents a distributed approach for computing persistent homology, which is a powerful tool for analyzing the topological structure of large-scale data.
- Persistent homology allows researchers to identify important features and patterns in complex datasets, but traditional methods can be computationally intensive and memory-intensive, especially for large-scale problems.
- The proposed distributed approach aims to address these challenges by leveraging parallel processing and efficient data management to enable persistent homology computation on a large scale.
Plain English Explanation
Persistent homology is a way to uncover the hidden shape and structure within complex datasets, like the points in a 3D point cloud or the connections in a social network. Imagine you have a bunch of dots scattered across a page - persistent homology can help you find the meaningful shapes and patterns in that jumble of dots, even if the shapes are intricate or nested inside each other.
The challenge is that computing persistent homology can be very computationally demanding, especially for huge datasets. This paper introduces a new distributed approach that splits up the work across multiple computers, allowing the persistent homology calculations to be done in parallel. By dividing the problem and spreading it out, the researchers were able to analyze much larger and more complex datasets than would be possible with traditional methods running on a single machine.
The key innovations in this paper are the strategies for efficiently partitioning the data and coordinating the parallel computations to ensure accurate and complete results. This distributed system allows persistent homology to be applied to real-world problems involving massive amounts of data, opening up new possibilities for using this powerful topological analysis technique.
Technical Explanation
The paper proposes a distributed approach for persistent homology computation on large-scale data. The authors note that while persistent homology is a valuable tool for extracting meaningful topological information from complex datasets, traditional methods can become computationally and memory-intensive, especially for large-scale problems.
To address these challenges, the researchers developed a distributed framework that leverages parallel processing and efficient data management techniques. The core idea is to partition the input data and corresponding simplicial complex into smaller subproblems that can be processed independently on multiple worker nodes. A master node coordinates the distributed computation, merging the local results to produce the final persistent homology.
Key technical contributions include:
- An efficient data partitioning scheme that minimizes communication overhead between worker nodes.
- Novel algorithms for merging local persistence diagrams to obtain the global persistence diagram.
- Strategies for handling complex topological features that span multiple partitions.
The paper demonstrates the effectiveness of the distributed approach through experiments on large-scale point cloud and network datasets, showing significant improvements in computational efficiency and memory usage compared to centralized methods.
Critical Analysis
The paper presents a well-designed distributed framework for large-scale persistent homology computation, addressing an important challenge in topological data analysis. The authors have carefully considered the practical issues involved in parallelizing this computationally intensive task, such as efficient data partitioning and merging of local results.
One potential limitation discussed in the paper is the handling of topological features that span multiple partitions. While the authors propose strategies to address this, it may still introduce some approximation error or require additional coordination between worker nodes. Further research could explore alternative partitioning schemes or distributed algorithms that can more seamlessly handle global topological structures.
Additionally, the paper focuses on the algorithmic and computational aspects of the distributed persistent homology approach. It would be interesting to see more discussion on the practical implications and applications of this work, such as the types of large-scale problems it could enable researchers to tackle or the potential impact on specific domains that rely heavily on topological data analysis.
Overall, this paper represents a significant contribution to the field of topological data analysis, demonstrating how distributed computing can be leveraged to scale up persistent homology computations and open up new possibilities for exploring the hidden structure of complex, large-scale data.
Conclusion
This paper introduces a distributed approach for persistent homology computation that addresses the computational and memory challenges associated with traditional methods, particularly for large-scale datasets. By partitioning the data and computations across multiple worker nodes, the proposed framework enables efficient parallel processing and merging of local results to obtain the global persistent homology.
The key innovations in this work include efficient data partitioning strategies, algorithms for merging local persistence diagrams, and techniques for handling topological features that span multiple partitions. Experimental results demonstrate significant improvements in computational efficiency and memory usage compared to centralized persistent homology computation.
This distributed approach represents an important step forward in making persistent homology a more practical and scalable tool for exploring the intricate topological structure of large-scale, complex datasets. By unlocking the ability to perform these computations on a much larger scale, this research could have far-reaching implications for a wide range of applications that rely on topological data analysis, from materials science and neuroscience to network analysis and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
A Distributed Approach for Persistent Homology Computation on a Large Scale
Riccardo Ceccaroni, Lorenzo Di Rocco, Umberto Ferraro Petrillo, Pierpaolo Brutti
Persistent homology (PH) is a powerful mathematical method to automatically extract relevant insights from images, such as those obtained by high-resolution imaging devices like electron microscopes or new-generation telescopes. However, the application of this method comes at a very high computational cost, that is bound to explode more because new imaging devices generate an ever-growing amount of data. In this paper we present PixHomology, a novel algorithm for efficiently computing $0$-dimensional PH on 2D images, optimizing memory and processing time. By leveraging the Apache Spark framework, we also present a distributed version of our algorithm with several optimized variants, able to concurrently process large batches of astronomical images. Finally, we present the results of an experimental analysis showing that our algorithm and its distributed version are efficient in terms of required memory, execution time, and scalability, consistently outperforming existing state-of-the-art PH computation tools when used to process large datasets.
Read more4/15/2024
📊
0
Persistent Homology for High-dimensional Data Based on Spectral Methods
Sebastian Damrich, Philipp Berens, Dmitry Kobak
Persistent homology is a popular computational tool for analyzing the topology of point clouds, such as the presence of loops or voids. However, many real-world datasets with low intrinsic dimensionality reside in an ambient space of much higher dimensionality. We show that in this case traditional persistent homology becomes very sensitive to noise and fails to detect the correct topology. The same holds true for existing refinements of persistent homology. As a remedy, we find that spectral distances on the $k$-nearest-neighbor graph of the data, such as diffusion distance and effective resistance, allow to detect the correct topology even in the presence of high-dimensional noise. Moreover, we derive a novel closed-form formula for effective resistance, and describe its relation to diffusion distances. Finally, we apply these methods to high-dimensional single-cell RNA-sequencing data and show that spectral distances allow robust detection of cell cycle loops.
Read more5/9/2024
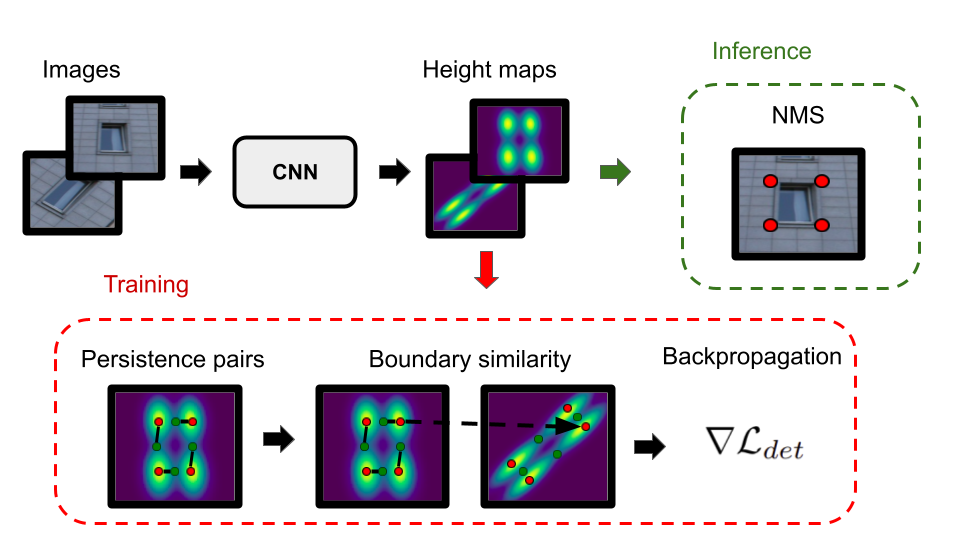
0
Scale-Free Image Keypoints Using Differentiable Persistent Homology
Giovanni Barbarani, Francesco Vaccarino, Gabriele Trivigno, Marco Guerra, Gabriele Berton, Carlo Masone
In computer vision, keypoint detection is a fundamental task, with applications spanning from robotics to image retrieval; however, existing learning-based methods suffer from scale dependency and lack flexibility. This paper introduces a novel approach that leverages Morse theory and persistent homology, powerful tools rooted in algebraic topology. We propose a novel loss function based on the recent introduction of a notion of subgradient in persistent homology, paving the way toward topological learning. Our detector, MorseDet, is the first topology-based learning model for feature detection, which achieves competitive performance in keypoint repeatability and introduces a principled and theoretically robust approach to the problem.
Read more6/4/2024
🚀
0
On the Expressivity of Persistent Homology in Graph Learning
Rub'en Ballester, Bastian Rieck
Persistent homology, a technique from computational topology, has recently shown strong empirical performance in the context of graph classification. Being able to capture long range graph properties via higher-order topological features, such as cycles of arbitrary length, in combination with multi-scale topological descriptors, has improved predictive performance for data sets with prominent topological structures, such as molecules. At the same time, the theoretical properties of persistent homology have not been formally assessed in this context. This paper intends to bridge the gap between computational topology and graph machine learning by providing a brief introduction to persistent homology in the context of graphs, as well as a theoretical discussion and empirical analysis of its expressivity for graph learning tasks.
Read more6/4/2024