Diverse Feature Learning by Self-distillation and Reset
2403.19941
0
0

Abstract
Our paper addresses the problem of models struggling to learn diverse features, due to either forgetting previously learned features or failing to learn new ones. To overcome this problem, we introduce Diverse Feature Learning (DFL), a method that combines an important feature preservation algorithm with a new feature learning algorithm. Specifically, for preserving important features, we utilize self-distillation in ensemble models by selecting the meaningful model weights observed during training. For learning new features, we employ reset that involves periodically re-initializing part of the model. As a result, through experiments with various models on the image classification, we have identified the potential for synergistic effects between self-distillation and reset.
Create account to get full access
Introduction
The key points from the provided text are:
Proper feature learning is important for tasks like colorization, but deep learning models can struggle with issues like forgetting learned features or being unable to learn new features. The paper proposes a method called Diverse Feature Learning (DFL) that combines feature preservation and new feature learning.
For feature preservation, DFL uses self-distillation on ensemble models based on the training trajectory. This leverages the alignment of important features throughout training. For new feature learning, DFL utilizes a reset strategy, which periodically re-initializes part of the model to allow it to explore different weight spaces and learn new features.
By combining self-distillation and reset, DFL creates a synergistic effect that enables learning of diverse important features. The paper demonstrates the effectiveness of DFL experimentally on image classification tasks.
The paper is structured as follows: Section 2 discusses related work, Section 3 explains the details of the DFL method, Section 4 presents the experimental results, and Section 5 covers limitations and future work.
Related Work
The text discusses the importance of learning diverse features in deep learning models and the challenges associated with doing so in the context of single-model training. The key points are:
-
Learning diverse features can improve model performance, as seen in the benefits of ensemble methods. However, training a single model to learn diverse features is challenging.
-
Existing approaches have focused on data-centric methods to address this, such as resampling or using different training sets. But these can lead to loss of information compared to training on all data.
-
The authors propose an algorithm called Diverse Feature Learning (DFL) that aims to bring the advantages of ensembles to single-model training.
-
DFL has two key components: feature preservation and new feature learning.
-
For feature preservation, DFL uses self-distillation, selecting significant weights from the training trajectory as teacher models. This differs from prior self-distillation approaches.
-
For new feature learning, DFL incorporates "reset", which re-initializes the model, to facilitate learning of useful features not easily learned from the current weight distribution.
In summary, the paper presents a novel algorithm, DFL, that combines self-distillation and reset to enable a single model to learn diverse features, drawing inspiration from the benefits of ensemble methods.
Methods
The paper presents a Diverse Feature Learning (DFL) algorithm for training deep learning models. The key aspects are:
-
The model has a student network ϕ0 and multiple teacher networks ϕk. The student is trained using a combination of task-specific loss and self-distillation loss, which encourages the student to learn diverse features by matching its outputs to those of the teachers.
-
The teachers are updated periodically by replacing the least meaningful teacher with the student, based on a meaningfulness measurement function f that evaluates the teachers' performance.
-
The student is also reset periodically by re-initializing its weights, either randomly or by taking the mean of the teacher weights. This helps the student learn new features.
The paper further details the algorithm tailored for image classification tasks. Here, the student ϕ0 is the last layer or part of the model, and the meaningfulness of each teacher is measured by its training accuracy in the previous epoch. The teacher update and student reset cycles are synchronized.
The proposed DFL approach aims to enable the model to learn diverse features through self-distillation, efficient ensemble of teachers, and periodic resetting of the student.
Experiment
This paper evaluates the effectiveness of Diverse Feature Learning (DFL) for image classification using various model architectures on the CIFAR-10 and CIFAR-100 datasets. Key findings:
-
The CIFAR-10 and CIFAR-100 datasets contain 10 and 100 image classes, respectively, with 32x32 pixel images.
-
Experiments were conducted on five lightweight models: VGG-16, SqueezeNet, ShuffleNet, MobileNet-V2, and GoogLeNet. These models have different convolutional neural network architectures.
-
DFL combines feature preservation through self-distillation and new feature learning through layer reset. The paper analyzes how these components affect performance.
-
On CIFAR-100 using the VGG model, DFL resulted in a 1.09% increase in accuracy compared to the baseline. Self-distillation and reset alone led to smaller performance gains.
-
The paper examines how varying the student layers, cycle duration, number of teachers, and reset method impacts DFL's characteristics. Longer cycle durations and appropriate teacher counts tend to improve performance.
-
Applying DFL to diverse model architectures shows mixed results, with some models benefiting more than others. This is likely due to challenges in effectively learning aligned features when the student's capacity is limited.
-
The self-distillation loss analysis suggests limitations in the teacher selection approach, which may restrict DFL's ability to consistently improve performance across different datasets and model architectures.
Conclusion
This paper proposes Diverse Feature Learning (DFL), which combines self-distillation and reset to address the need for feature preservation and new feature learning. The authors demonstrate that DFL can enhance performance, surpassing existing works in specific cases, and show that using reset in conjunction with self-distillation exhibits a synergistic effect.
The paper also suggests that choosing multiple appropriate teachers on the training trajectory can be beneficial for self-distillation. However, the authors acknowledge that the detailed algorithms have certain constraints when materializing the concepts of DFL. Specifically, using the previous epoch's training accuracy as a measure of meaningfulness for the teachers' update introduces a vulnerability to overfitting.
To address this issue, the authors suggest adopting the uncertainty measurement used in active learning and assessing similarity between weights. Additionally, an analysis is required regarding the selection of layers most suitable for feature learning. The paper also discusses applying reset more stably and obtaining model weights for self-distillation in various ways.
Potential Broader Impact
The paper aims to advance the field of machine learning. The work has potential societal implications, though these are not highlighted in the provided text.
Appendix A Overall Experiment Results
The paper presents experimental results for Diverse Feature Learning (DFL) on the CIFAR-100 and CIFAR-10 datasets. Tables 4 and 5 show the test accuracy at the last step of training, with notes about minor differences in results due to using different GPUs. The mean and standard deviation are calculated to account for these differences.
An ablation study is also included, where the last 10 of the 200 training epochs were done without DFL. The results in Tables 6 and 7 show the same trends as Tables 4 and 5 when excluding these final 10 epochs.
Figure 6 depicts the learning process for the default setting in Table 2. It shows the changes in learning rate, test accuracy, classification loss, and self-distillation loss over the training epochs.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
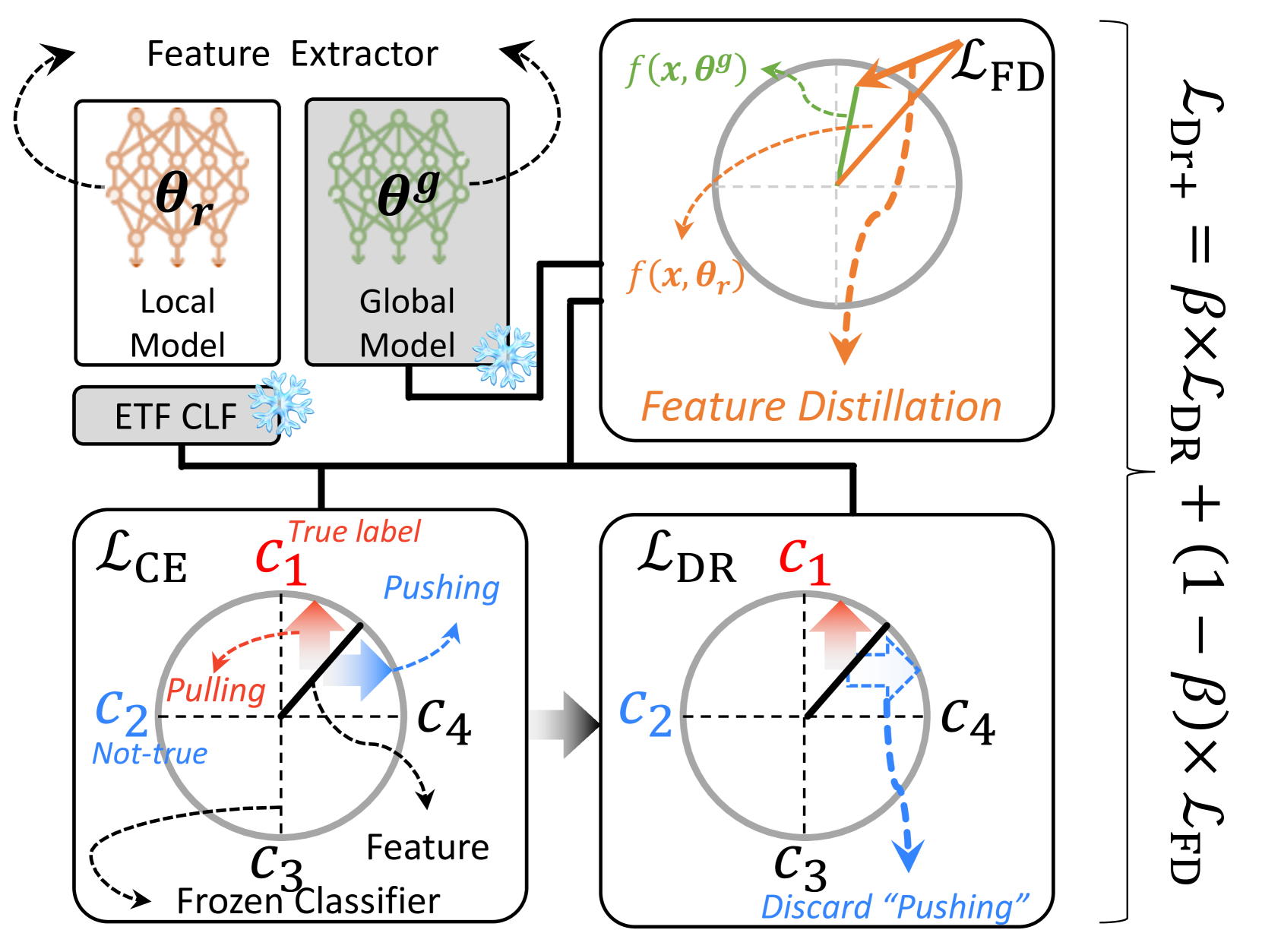
FedDr+: Stabilizing Dot-regression with Global Feature Distillation for Federated Learning
Seongyoon Kim, Minchan Jeong, Sungnyun Kim, Sungwoo Cho, Sumyeong Ahn, Se-Young Yun
0
0
Federated Learning (FL) has emerged as a pivotal framework for the development of effective global models (global FL) or personalized models (personalized FL) across clients with heterogeneous, non-iid data distribution. A key challenge in FL is client drift, where data heterogeneity impedes the aggregation of scattered knowledge. Recent studies have tackled the client drift issue by identifying significant divergence in the last classifier layer. To mitigate this divergence, strategies such as freezing the classifier weights and aligning the feature extractor accordingly have proven effective. Although the local alignment between classifier and feature extractor has been studied as a crucial factor in FL, we observe that it may lead the model to overemphasize the observed classes within each client. Thus, our objectives are twofold: (1) enhancing local alignment while (2) preserving the representation of unseen class samples. This approach aims to effectively integrate knowledge from individual clients, thereby improving performance for both global and personalized FL. To achieve this, we introduce a novel algorithm named FedDr+, which empowers local model alignment using dot-regression loss. FedDr+ freezes the classifier as a simplex ETF to align the features and improves aggregated global models by employing a feature distillation mechanism to retain information about unseen/missing classes. Consequently, we provide empirical evidence demonstrating that our algorithm surpasses existing methods that use a frozen classifier to boost alignment across the diverse distribution.
6/5/2024
🚀
Robust Representation Learning with Self-Distillation for Domain Generalization
Ankur Singh, Senthilnath Jayavelu
0
0
Despite the recent success of deep neural networks, there remains a need for effective methods to enhance domain generalization using vision transformers. In this paper, we propose a novel domain generalization technique called Robust Representation Learning with Self-Distillation (RRLD) comprising i) intermediate-block self-distillation and ii) augmentation-guided self-distillation to improve the generalization capabilities of transformer-based models on unseen domains. This approach enables the network to learn robust and general features that are invariant to different augmentations and domain shifts while effectively mitigating overfitting to source domains. To evaluate the effectiveness of our proposed method, we perform extensive experiments on PACS and OfficeHome benchmark datasets, as well as an industrial wafer semiconductor defect dataset. The results demonstrate that RRLD achieves robust and accurate generalization performance. We observe an average accuracy improvement in the range of 1.2% to 2.3% over the state-of-the-art on the three datasets.
4/15/2024

Self-Distillation Bridges Distribution Gap in Language Model Fine-Tuning
Zhaorui Yang, Tianyu Pang, Haozhe Feng, Han Wang, Wei Chen, Minfeng Zhu, Qian Liu
0
0
The surge in Large Language Models (LLMs) has revolutionized natural language processing, but fine-tuning them for specific tasks often encounters challenges in balancing performance and preserving general instruction-following abilities. In this paper, we posit that the distribution gap between task datasets and the LLMs serves as the primary underlying cause. To address the problem, we introduce Self-Distillation Fine-Tuning (SDFT), a novel approach that bridges the distribution gap by guiding fine-tuning with a distilled dataset generated by the model itself to match its original distribution. Experimental results on the Llama-2-chat model across various benchmarks demonstrate that SDFT effectively mitigates catastrophic forgetting while achieving comparable or superior performance on downstream tasks compared to the vanilla fine-tuning. Moreover, SDFT demonstrates the potential to maintain the helpfulness and safety alignment of LLMs. Our code is available at https://github.com/sail-sg/sdft.
5/29/2024
🤷
Pixel-Wise Contrastive Distillation
Junqiang Huang, Zichao Guo
0
0
We present a simple but effective pixel-level self-supervised distillation framework friendly to dense prediction tasks. Our method, called Pixel-Wise Contrastive Distillation (PCD), distills knowledge by attracting the corresponding pixels from student's and teacher's output feature maps. PCD includes a novel design called SpatialAdaptor which ``reshapes'' a part of the teacher network while preserving the distribution of its output features. Our ablation experiments suggest that this reshaping behavior enables more informative pixel-to-pixel distillation. Moreover, we utilize a plug-in multi-head self-attention module that explicitly relates the pixels of student's feature maps to enhance the effective receptive field, leading to a more competitive student. PCD textbf{outperforms} previous self-supervised distillation methods on various dense prediction tasks. A backbone of mbox{ResNet-18-FPN} distilled by PCD achieves $37.4$ AP$^text{bbox}$ and $34.0$ AP$^text{mask}$ on COCO dataset using the detector of mbox{Mask R-CNN}. We hope our study will inspire future research on how to pre-train a small model friendly to dense prediction tasks in a self-supervised fashion.
4/17/2024