FedDr+: Stabilizing Dot-regression with Global Feature Distillation for Federated Learning

0
Sign in to get full access
Overview
- Proposes FedDr+, a novel federated learning approach that combines dot-regression and global feature distillation to stabilize the training process and improve model performance.
- Addresses the challenges of data heterogeneity and non-IID distributions in federated learning settings.
- Introduces the concept of global feature distillation to leverage shared knowledge across clients and the central server.
Plain English Explanation
FedDr+: Stabilizing Dot-regression with Global Feature Distillation for Federated Learning is a new technique for federated learning that aims to improve the stability and performance of the learning process. Federated learning is a way of training machine learning models where the data is spread out across many devices, like phones or computers, instead of being stored in one central location.
One of the challenges in federated learning is that the data on each device can be quite different, which can make it hard for the model to learn properly. FedDr+ addresses this by combining two key ideas: dot-regression and global feature distillation.
Dot-regression is a way of training the model that focuses on the relationships between the different features in the data, rather than just trying to predict the target variable directly. This can be more robust to differences in the data across devices.
Global feature distillation is a technique where the central server tries to learn a "global" model that captures the shared knowledge across all the devices. This global model is then used to guide the training of the local models on each device, helping to make them more consistent and stable.
By combining these two ideas, FedDr+ is able to train federated learning models that are more accurate and less sensitive to the differences in data between devices. This could be particularly useful in applications where the data is spread across many different users or devices, such as personalized recommendations or healthcare applications.
Technical Explanation
FedDr+: Stabilizing Dot-regression with Global Feature Distillation for Federated Learning proposes a novel federated learning approach that combines dot-regression and global feature distillation to address the challenges of data heterogeneity and non-IID distributions.
The key innovations of FedDr+ are:
-
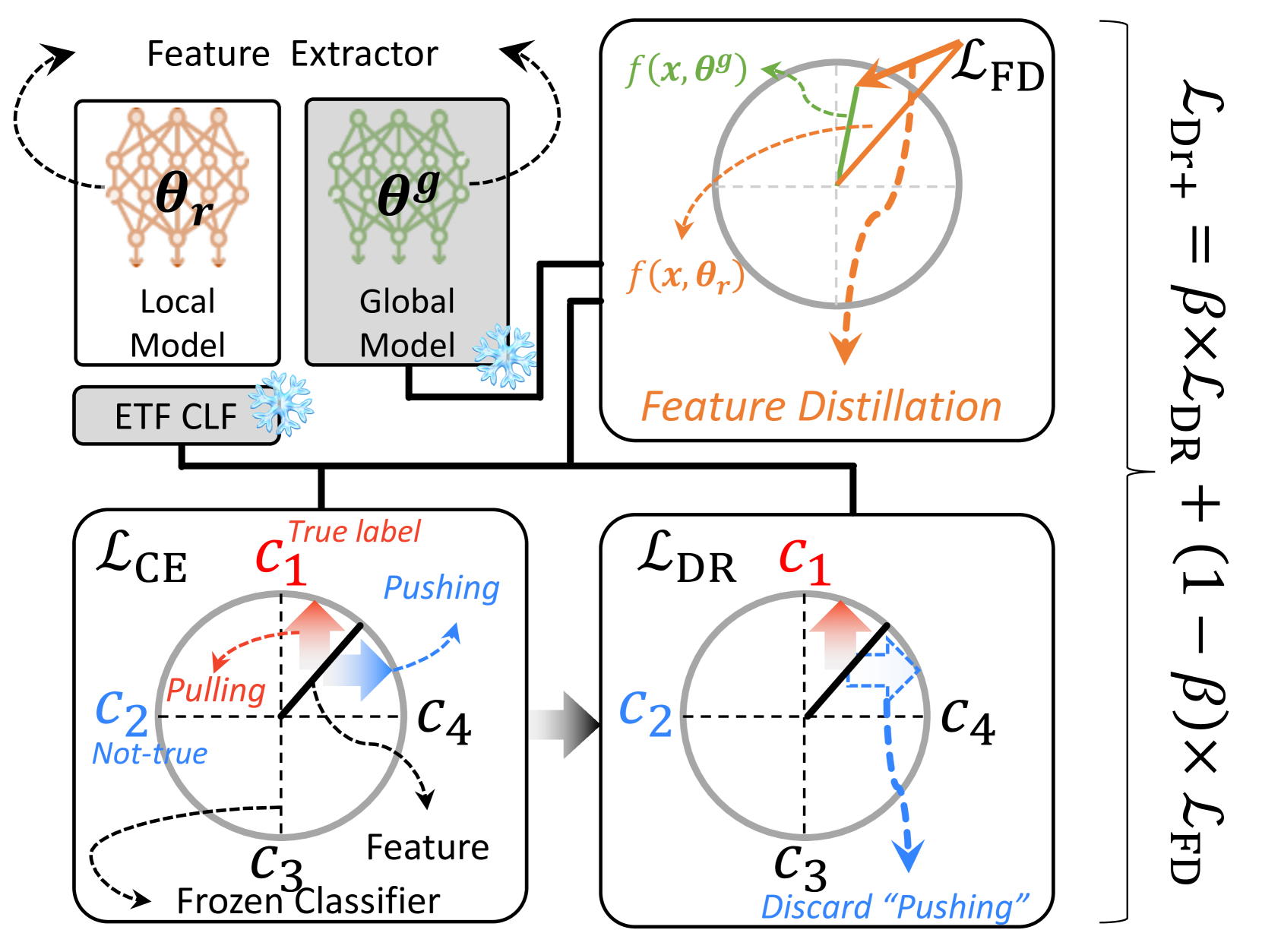
Dot-regression: The authors introduce a dot-regression loss function that focuses on learning the relationships between input features, rather than just predicting the target variable directly. This can help improve model robustness to data heterogeneity across clients.
-
Global Feature Distillation: FedDr+ leverages a global feature distillation mechanism, where the central server learns a shared "global" model that captures the common knowledge across all clients. This global model is then used to guide the training of the local models on each client, helping to stabilize the learning process.
The authors conduct extensive experiments on several benchmark datasets, comparing FedDr+ to state-of-the-art federated learning approaches like FedCal and FedCCL. The results demonstrate that FedDr+ achieves significantly higher accuracy and faster convergence, particularly in challenging non-IID settings.
Critical Analysis
The paper provides a compelling solution to the problem of data heterogeneity in federated learning, which is a critical challenge in many real-world applications. The combination of dot-regression and global feature distillation is a novel and well-designed approach that appears to offer substantial improvements over existing methods.
However, the paper does not fully address the potential trade-offs or limitations of the FedDr+ approach. For example, the additional communication and computation required for the global feature distillation process may increase the overall system overhead, which could be a concern in resource-constrained edge devices. Additionally, the paper does not explore the scalability of FedDr+ as the number of clients or the complexity of the task increases.
Further research could investigate the robustness of FedDr+ to various types of data heterogeneity, as well as its performance in more realistic federated learning scenarios with asynchronous updates, client dropouts, and communication constraints. Exploring ways to optimize the global feature distillation process could also help reduce the computational and communication burden of the FedDr+ approach.
Conclusion
FedDr+: Stabilizing Dot-regression with Global Feature Distillation for Federated Learning presents a novel federated learning approach that combines dot-regression and global feature distillation to address the challenges of data heterogeneity and non-IID distributions. The results demonstrate significant improvements in model accuracy and convergence speed, particularly in challenging non-IID settings.
The FedDr+ approach represents an important step forward in the field of federated learning, as it provides a practical solution for leveraging shared knowledge across clients to improve the stability and performance of the learning process. As federated learning continues to gain traction in real-world applications, techniques like FedDr+ will become increasingly important for ensuring the robustness and reliability of the resulting models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
FedDr+: Stabilizing Dot-regression with Global Feature Distillation for Federated Learning
Seongyoon Kim, Minchan Jeong, Sungnyun Kim, Sungwoo Cho, Sumyeong Ahn, Se-Young Yun
Federated Learning (FL) has emerged as a pivotal framework for the development of effective global models (global FL) or personalized models (personalized FL) across clients with heterogeneous, non-iid data distribution. A key challenge in FL is client drift, where data heterogeneity impedes the aggregation of scattered knowledge. Recent studies have tackled the client drift issue by identifying significant divergence in the last classifier layer. To mitigate this divergence, strategies such as freezing the classifier weights and aligning the feature extractor accordingly have proven effective. Although the local alignment between classifier and feature extractor has been studied as a crucial factor in FL, we observe that it may lead the model to overemphasize the observed classes within each client. Thus, our objectives are twofold: (1) enhancing local alignment while (2) preserving the representation of unseen class samples. This approach aims to effectively integrate knowledge from individual clients, thereby improving performance for both global and personalized FL. To achieve this, we introduce a novel algorithm named FedDr+, which empowers local model alignment using dot-regression loss. FedDr+ freezes the classifier as a simplex ETF to align the features and improves aggregated global models by employing a feature distillation mechanism to retain information about unseen/missing classes. Consequently, we provide empirical evidence demonstrating that our algorithm surpasses existing methods that use a frozen classifier to boost alignment across the diverse distribution.
Read more6/5/2024

0
FedDistill: Global Model Distillation for Local Model De-Biasing in Non-IID Federated Learning
Changlin Song, Divya Saxena, Jiannong Cao, Yuqing Zhao
Federated Learning (FL) is a novel approach that allows for collaborative machine learning while preserving data privacy by leveraging models trained on decentralized devices. However, FL faces challenges due to non-uniformly distributed (non-iid) data across clients, which impacts model performance and its generalization capabilities. To tackle the non-iid issue, recent efforts have utilized the global model as a teaching mechanism for local models. However, our pilot study shows that their effectiveness is constrained by imbalanced data distribution, which induces biases in local models and leads to a 'local forgetting' phenomenon, where the ability of models to generalize degrades over time, particularly for underrepresented classes. This paper introduces FedDistill, a framework enhancing the knowledge transfer from the global model to local models, focusing on the issue of imbalanced class distribution. Specifically, FedDistill employs group distillation, segmenting classes based on their frequency in local datasets to facilitate a focused distillation process to classes with fewer samples. Additionally, FedDistill dissects the global model into a feature extractor and a classifier. This separation empowers local models with more generalized data representation capabilities and ensures more accurate classification across all classes. FedDistill mitigates the adverse effects of data imbalance, ensuring that local models do not forget underrepresented classes but instead become more adept at recognizing and classifying them accurately. Our comprehensive experiments demonstrate FedDistill's effectiveness, surpassing existing baselines in accuracy and convergence speed across several benchmark datasets.
Read more4/16/2024
0
Recovering Global Data Distribution Locally in Federated Learning
Ziyu Yao
Federated Learning (FL) is a distributed machine learning paradigm that enables collaboration among multiple clients to train a shared model without sharing raw data. However, a major challenge in FL is the label imbalance, where clients may exclusively possess certain classes while having numerous minority and missing classes. Previous works focus on optimizing local updates or global aggregation but ignore the underlying imbalanced label distribution across clients. In this paper, we propose a novel approach ReGL to address this challenge, whose key idea is to Recover the Global data distribution Locally. Specifically, each client uses generative models to synthesize images that complement the minority and missing classes, thereby alleviating label imbalance. Moreover, we adaptively fine-tune the image generation process using local real data, which makes the synthetic images align more closely with the global distribution. Importantly, both the generation and fine-tuning processes are conducted at the client-side without leaking data privacy. Through comprehensive experiments on various image classification datasets, we demonstrate the remarkable superiority of our approach over existing state-of-the-art works in fundamentally tackling label imbalance in FL.
Read more9/24/2024

0
An Aggregation-Free Federated Learning for Tackling Data Heterogeneity
Yuan Wang, Huazhu Fu, Renuga Kanagavelu, Qingsong Wei, Yong Liu, Rick Siow Mong Goh
The performance of Federated Learning (FL) hinges on the effectiveness of utilizing knowledge from distributed datasets. Traditional FL methods adopt an aggregate-then-adapt framework, where clients update local models based on a global model aggregated by the server from the previous training round. This process can cause client drift, especially with significant cross-client data heterogeneity, impacting model performance and convergence of the FL algorithm. To address these challenges, we introduce FedAF, a novel aggregation-free FL algorithm. In this framework, clients collaboratively learn condensed data by leveraging peer knowledge, the server subsequently trains the global model using the condensed data and soft labels received from the clients. FedAF inherently avoids the issue of client drift, enhances the quality of condensed data amid notable data heterogeneity, and improves the global model performance. Extensive numerical studies on several popular benchmark datasets show FedAF surpasses various state-of-the-art FL algorithms in handling label-skew and feature-skew data heterogeneity, leading to superior global model accuracy and faster convergence.
Read more5/1/2024